 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLASER: Loss-Aware Singular-value Decomposition and Rank Allocation for Efficient Low-Precision Vision-Language Models
May 30, 2026Vision-language models (VLMs) deliver strong multimodal reasoning capabilities, but their large computational cost and high parameter counts make deployment challenging on resource-constrained devices. Low-rank decomposition has emerged as a promising compression technique, yet existing methods often optimize local matrix reconstruction error, rely on uniform or heuristic rank allocation, and focus mainly on attention projections while leaving feed-forward networks underexplored. In this paper, we propose~\textit{LASER} (\textbf{L}oss-\textbf{A}ware \textbf{S}ingular-value d\textbf{E}composition and \textbf{R}ank allocation), a low-rank compression framework for efficient low-precision VLM inference. LASER derives a curvature-weighted SVD objective from a second-order approximation of the model loss and uses Kronecker-factored Fisher information to guide decomposition toward downstream performance rather than reconstruction alone. We further introduce a loss-aware cross-layer rank allocation strategy based on calibration gradients, enabling more effective parameter budgeting across layers. Finally, we extend low-rank compression to FFN layers through a hybrid scheme that combines SVD with quantization. The evaluation results show that LASER achieves more than $2.3\times$ decoding speedup over previous work while preserving strong accuracy under low-precision inference.
LeJOT-AutoML: LLM-Driven Feature Engineering for Job Execution Time Prediction in Databricks Cost Optimization
Mar 09, 2026Databricks job orchestration systems (e.g., LeJOT) reduce cloud costs by selecting low-priced compute configurations while meeting latency and dependency constraints. Accurate execution-time prediction under heterogeneous instance types and non-stationary runtime conditions is therefore critical. Existing pipelines rely on static, manually engineered features that under-capture runtime effects (e.g., partition pruning, data skew, and shuffle amplification), and predictive signals are scattered across logs, metadata, and job scripts-lengthening update cycles and increasing engineering overhead. We present LeJOT-AutoML, an agent-driven AutoML framework that embeds large language model agents throughout the ML lifecycle. LeJOT-AutoML combines retrieval-augmented generation over a domain knowledge base with a Model Context Protocol toolchain (log parsers, metadata queries, and a read-only SQL sandbox) to analyze job artifacts, synthesize and validate feature-extraction code via safety gates, and train/select predictors. This design materializes runtime-derived features that are difficult to obtain through static analysis alone. On enterprise Databricks workloads, LeJOT-AutoML generates over 200 features and reduces the feature-engineering and evaluation loop from weeks to 20-30 minutes, while maintaining competitive prediction accuracy. Integrated into the LeJOT pipeline, it enables automated continuous model updates and achieves 19.01% cost savings in our deployment setting through improved orchestration.
AutoSizer: Automatic Sizing of Analog and Mixed-Signal Circuits via Large Language Model (LLM) Agents
Feb 02, 2026The design of Analog and Mixed-Signal (AMS) integrated circuits remains heavily reliant on expert knowledge, with transistor sizing a major bottleneck due to nonlinear behavior, high-dimensional design spaces, and strict performance constraints. Existing Electronic Design Automation (EDA) methods typically frame sizing as static black-box optimization, resulting in inefficient and less robust solutions. Although Large Language Models (LLMs) exhibit strong reasoning abilities, they are not suited for precise numerical optimization in AMS sizing. To address this gap, we propose AutoSizer, a reflective LLM-driven meta-optimization framework that unifies circuit understanding, adaptive search-space construction, and optimization orchestration in a closed loop. It employs a two-loop optimization framework, with an inner loop for circuit sizing and an outer loop that analyzes optimization dynamics and constraints to iteratively refine the search space from simulation feedback. We further introduce AMS-SizingBench, an open benchmark comprising 24 diverse AMS circuits in SKY130 CMOS technology, designed to evaluate adaptive optimization policies under realistic simulator-based constraints. AutoSizer experimentally achieves higher solution quality, faster convergence, and higher success rate across varying circuit difficulties, outperforming both traditional optimization methods and existing LLM-based agents.
Parameter Inference and Uncertainty Quantification with Diffusion Models: Extending CDI to 2D Spatial Conditioning
Jan 23, 2026Uncertainty quantification is critical in scientific inverse problems to distinguish identifiable parameters from those that remain ambiguous given available measurements. The Conditional Diffusion Model-based Inverse Problem Solver (CDI) has previously demonstrated effective probabilistic inference for one-dimensional temporal signals, but its applicability to higher-dimensional spatial data remains unexplored. We extend CDI to two-dimensional spatial conditioning, enabling probabilistic parameter inference directly from spatial observations. We validate this extension on convergent beam electron diffraction (CBED) parameter inference - a challenging multi-parameter inverse problem in materials characterization where sample geometry, electronic structure, and thermal properties must be extracted from 2D diffraction patterns. Using simulated CBED data with ground-truth parameters, we demonstrate that CDI produces well-calibrated posterior distributions that accurately reflect measurement constraints: tight distributions for well-determined quantities and appropriately broad distributions for ambiguous parameters. In contrast, standard regression methods - while appearing accurate on aggregate metrics - mask this underlying uncertainty by predicting training set means for poorly constrained parameters. Our results confirm that CDI successfully extends from temporal to spatial domains, providing the genuine uncertainty information required for robust scientific inference.
LeJOT: An Intelligent Job Cost Orchestration Solution for Databricks Platform
Dec 20, 2025With the rapid advancements in big data technologies, the Databricks platform has become a cornerstone for enterprises and research institutions, offering high computational efficiency and a robust ecosystem. However, managing the escalating operational costs associated with job execution remains a critical challenge. Existing solutions rely on static configurations or reactive adjustments, which fail to adapt to the dynamic nature of workloads. To address this, we introduce LeJOT, an intelligent job cost orchestration framework that leverages machine learning for execution time prediction and a solver-based optimization model for real-time resource allocation. Unlike conventional scheduling techniques, LeJOT proactively predicts workload demands, dynamically allocates computing resources, and minimizes costs while ensuring performance requirements are met. Experimental results on real-world Databricks workloads demonstrate that LeJOT achieves an average 20% reduction in cloud computing costs within a minute-level scheduling timeframe, outperforming traditional static allocation strategies. Our approach provides a scalable and adaptive solution for cost-efficient job scheduling in Data Lakehouse environments.
CircuitSense: A Hierarchical Circuit System Benchmark Bridging Visual Comprehension and Symbolic Reasoning in Engineering Design Process
Sep 26, 2025Engineering design operates through hierarchical abstraction from system specifications to component implementations, requiring visual understanding coupled with mathematical reasoning at each level. While Multi-modal Large Language Models (MLLMs) excel at natural image tasks, their ability to extract mathematical models from technical diagrams remains unexplored. We present \textbf{CircuitSense}, a comprehensive benchmark evaluating circuit understanding across this hierarchy through 8,006+ problems spanning component-level schematics to system-level block diagrams. Our benchmark uniquely examines the complete engineering workflow: Perception, Analysis, and Design, with a particular emphasis on the critical but underexplored capability of deriving symbolic equations from visual inputs. We introduce a hierarchical synthetic generation pipeline consisting of a grid-based schematic generator and a block diagram generator with auto-derived symbolic equation labels. Comprehensive evaluation of six state-of-the-art MLLMs, including both closed-source and open-source models, reveals fundamental limitations in visual-to-mathematical reasoning. Closed-source models achieve over 85\% accuracy on perception tasks involving component recognition and topology identification, yet their performance on symbolic derivation and analytical reasoning falls below 19\%, exposing a critical gap between visual parsing and symbolic reasoning. Models with stronger symbolic reasoning capabilities consistently achieve higher design task accuracy, confirming the fundamental role of mathematical understanding in circuit synthesis and establishing symbolic reasoning as the key metric for engineering competence.
Towards an Introspective Dynamic Model of Globally Distributed Computing Infrastructures
Jun 24, 2025Large-scale scientific collaborations like ATLAS, Belle II, CMS, DUNE, and others involve hundreds of research institutes and thousands of researchers spread across the globe. These experiments generate petabytes of data, with volumes soon expected to reach exabytes. Consequently, there is a growing need for computation, including structured data processing from raw data to consumer-ready derived data, extensive Monte Carlo simulation campaigns, and a wide range of end-user analysis. To manage these computational and storage demands, centralized workflow and data management systems are implemented. However, decisions regarding data placement and payload allocation are often made disjointly and via heuristic means. A significant obstacle in adopting more effective heuristic or AI-driven solutions is the absence of a quick and reliable introspective dynamic model to evaluate and refine alternative approaches. In this study, we aim to develop such an interactive system using real-world data. By examining job execution records from the PanDA workflow management system, we have pinpointed key performance indicators such as queuing time, error rate, and the extent of remote data access. The dataset includes five months of activity. Additionally, we are creating a generative AI model to simulate time series of payloads, which incorporate visible features like category, event count, and submitting group, as well as hidden features like the total computational load-derived from existing PanDA records and computing site capabilities. These hidden features, which are not visible to job allocators, whether heuristic or AI-driven, influence factors such as queuing times and data movement.
EvRT-DETR: The Surprising Effectiveness of DETR-based Detection for Event Cameras
Dec 03, 2024Event-based cameras (EBCs) have emerged as a bio-inspired alternative to traditional cameras, offering advantages in power efficiency, temporal resolution, and high dynamic range. However, the development of image analysis methods for EBCs is challenging due to the sparse and asynchronous nature of the data. This work addresses the problem of object detection for the EBC cameras. The current approaches to EBC object detection focus on constructing complex data representations and rely on specialized architectures. Here, we demonstrate that the combination of a Real-Time DEtection TRansformer, or RT-DETR, a state-of-the-art natural image detector, with a simple image-like representation of the EBC data achieves remarkable performance, surpassing current state-of-the-art results. Specifically, we show that a properly trained RT-DETR model on the EBC data achieves performance comparable to the most advanced EBC object detection methods. Next, we propose a low-rank adaptation (LoRA)-inspired way to augment the RT-DETR model to handle temporal dynamics of the data. The designed EvRT-DETR model outperforms the current, most advanced results on standard benchmark datasets Gen1 (mAP $+2.3$) and Gen4 (mAP $+1.4$) while only using standard modules from natural image and video analysis. These results demonstrate that effective EBC object detection can be achieved through careful adaptation of mainstream object detection architectures without requiring specialized architectural engineering. The code is available at: https://github.com/realtime-intelligence/evrt-detr
Efficient Compression of Sparse Accelerator Data Using Implicit Neural Representations and Importance Sampling
Dec 02, 2024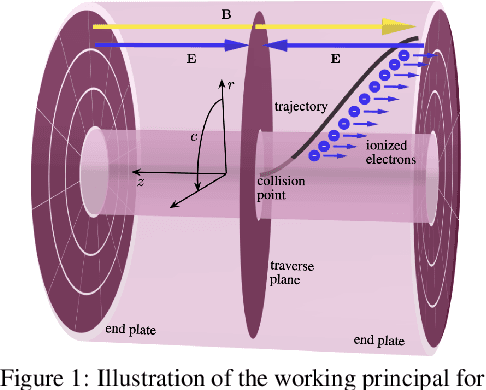
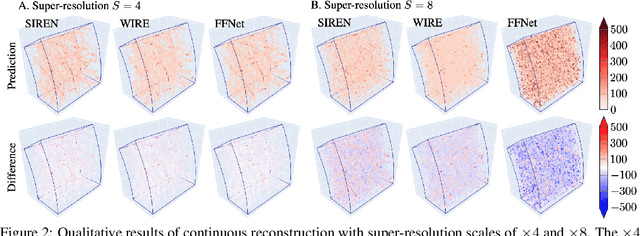
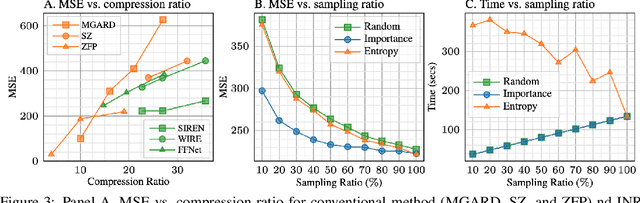
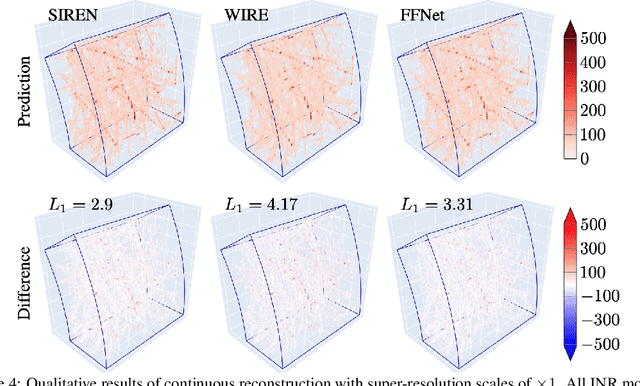
High-energy, large-scale particle colliders in nuclear and high-energy physics generate data at extraordinary rates, reaching up to $1$ terabyte and several petabytes per second, respectively. The development of real-time, high-throughput data compression algorithms capable of reducing this data to manageable sizes for permanent storage is of paramount importance. A unique characteristic of the tracking detector data is the extreme sparsity of particle trajectories in space, with an occupancy rate ranging from approximately $10^{-6}$ to $10\%$. Furthermore, for downstream tasks, a continuous representation of this data is often more useful than a voxel-based, discrete representation due to the inherently continuous nature of the signals involved. To address these challenges, we propose a novel approach using implicit neural representations for data learning and compression. We also introduce an importance sampling technique to accelerate the network training process. Our method is competitive with traditional compression algorithms, such as MGARD, SZ, and ZFP, while offering significant speed-ups and maintaining negligible accuracy loss through our importance sampling strategy.
Variable Rate Neural Compression for Sparse Detector Data
Nov 18, 2024High-energy large-scale particle colliders generate data at extraordinary rates. Developing real-time high-throughput data compression algorithms to reduce data volume and meet the bandwidth requirement for storage has become increasingly critical. Deep learning is a promising technology that can address this challenging topic. At the newly constructed sPHENIX experiment at the Relativistic Heavy Ion Collider, a Time Projection Chamber (TPC) serves as the main tracking detector, which records three-dimensional particle trajectories in a volume of a gas-filled cylinder. In terms of occupancy, the resulting data flow can be very sparse reaching $10^{-3}$ for proton-proton collisions. Such sparsity presents a challenge to conventional learning-free lossy compression algorithms, such as SZ, ZFP, and MGARD. In contrast, emerging deep learning-based models, particularly those utilizing convolutional neural networks for compression, have outperformed these conventional methods in terms of compression ratios and reconstruction accuracy. However, research on the efficacy of these deep learning models in handling sparse datasets, like those produced in particle colliders, remains limited. Furthermore, most deep learning models do not adapt their processing speeds to data sparsity, which affects efficiency. To address this issue, we propose a novel approach for TPC data compression via key-point identification facilitated by sparse convolution. Our proposed algorithm, BCAE-VS, achieves a $75\%$ improvement in reconstruction accuracy with a $10\%$ increase in compression ratio over the previous state-of-the-art model. Additionally, BCAE-VS manages to achieve these results with a model size over two orders of magnitude smaller. Lastly, we have experimentally verified that as sparsity increases, so does the model's throughput.