 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSizer: Automatic Sizing of Analog and Mixed-Signal Circuits via Large Language Model (LLM) Agents
Feb 02, 2026The design of Analog and Mixed-Signal (AMS) integrated circuits remains heavily reliant on expert knowledge, with transistor sizing a major bottleneck due to nonlinear behavior, high-dimensional design spaces, and strict performance constraints. Existing Electronic Design Automation (EDA) methods typically frame sizing as static black-box optimization, resulting in inefficient and less robust solutions. Although Large Language Models (LLMs) exhibit strong reasoning abilities, they are not suited for precise numerical optimization in AMS sizing. To address this gap, we propose AutoSizer, a reflective LLM-driven meta-optimization framework that unifies circuit understanding, adaptive search-space construction, and optimization orchestration in a closed loop. It employs a two-loop optimization framework, with an inner loop for circuit sizing and an outer loop that analyzes optimization dynamics and constraints to iteratively refine the search space from simulation feedback. We further introduce AMS-SizingBench, an open benchmark comprising 24 diverse AMS circuits in SKY130 CMOS technology, designed to evaluate adaptive optimization policies under realistic simulator-based constraints. AutoSizer experimentally achieves higher solution quality, faster convergence, and higher success rate across varying circuit difficulties, outperforming both traditional optimization methods and existing LLM-based agents.
Parameter Inference and Uncertainty Quantification with Diffusion Models: Extending CDI to 2D Spatial Conditioning
Jan 23, 2026Uncertainty quantification is critical in scientific inverse problems to distinguish identifiable parameters from those that remain ambiguous given available measurements. The Conditional Diffusion Model-based Inverse Problem Solver (CDI) has previously demonstrated effective probabilistic inference for one-dimensional temporal signals, but its applicability to higher-dimensional spatial data remains unexplored. We extend CDI to two-dimensional spatial conditioning, enabling probabilistic parameter inference directly from spatial observations. We validate this extension on convergent beam electron diffraction (CBED) parameter inference - a challenging multi-parameter inverse problem in materials characterization where sample geometry, electronic structure, and thermal properties must be extracted from 2D diffraction patterns. Using simulated CBED data with ground-truth parameters, we demonstrate that CDI produces well-calibrated posterior distributions that accurately reflect measurement constraints: tight distributions for well-determined quantities and appropriately broad distributions for ambiguous parameters. In contrast, standard regression methods - while appearing accurate on aggregate metrics - mask this underlying uncertainty by predicting training set means for poorly constrained parameters. Our results confirm that CDI successfully extends from temporal to spatial domains, providing the genuine uncertainty information required for robust scientific inference.
CircuitSense: A Hierarchical Circuit System Benchmark Bridging Visual Comprehension and Symbolic Reasoning in Engineering Design Process
Sep 26, 2025Engineering design operates through hierarchical abstraction from system specifications to component implementations, requiring visual understanding coupled with mathematical reasoning at each level. While Multi-modal Large Language Models (MLLMs) excel at natural image tasks, their ability to extract mathematical models from technical diagrams remains unexplored. We present \textbf{CircuitSense}, a comprehensive benchmark evaluating circuit understanding across this hierarchy through 8,006+ problems spanning component-level schematics to system-level block diagrams. Our benchmark uniquely examines the complete engineering workflow: Perception, Analysis, and Design, with a particular emphasis on the critical but underexplored capability of deriving symbolic equations from visual inputs. We introduce a hierarchical synthetic generation pipeline consisting of a grid-based schematic generator and a block diagram generator with auto-derived symbolic equation labels. Comprehensive evaluation of six state-of-the-art MLLMs, including both closed-source and open-source models, reveals fundamental limitations in visual-to-mathematical reasoning. Closed-source models achieve over 85\% accuracy on perception tasks involving component recognition and topology identification, yet their performance on symbolic derivation and analytical reasoning falls below 19\%, exposing a critical gap between visual parsing and symbolic reasoning. Models with stronger symbolic reasoning capabilities consistently achieve higher design task accuracy, confirming the fundamental role of mathematical understanding in circuit synthesis and establishing symbolic reasoning as the key metric for engineering competence.
EvRT-DETR: The Surprising Effectiveness of DETR-based Detection for Event Cameras
Dec 03, 2024Event-based cameras (EBCs) have emerged as a bio-inspired alternative to traditional cameras, offering advantages in power efficiency, temporal resolution, and high dynamic range. However, the development of image analysis methods for EBCs is challenging due to the sparse and asynchronous nature of the data. This work addresses the problem of object detection for the EBC cameras. The current approaches to EBC object detection focus on constructing complex data representations and rely on specialized architectures. Here, we demonstrate that the combination of a Real-Time DEtection TRansformer, or RT-DETR, a state-of-the-art natural image detector, with a simple image-like representation of the EBC data achieves remarkable performance, surpassing current state-of-the-art results. Specifically, we show that a properly trained RT-DETR model on the EBC data achieves performance comparable to the most advanced EBC object detection methods. Next, we propose a low-rank adaptation (LoRA)-inspired way to augment the RT-DETR model to handle temporal dynamics of the data. The designed EvRT-DETR model outperforms the current, most advanced results on standard benchmark datasets Gen1 (mAP $+2.3$) and Gen4 (mAP $+1.4$) while only using standard modules from natural image and video analysis. These results demonstrate that effective EBC object detection can be achieved through careful adaptation of mainstream object detection architectures without requiring specialized architectural engineering. The code is available at: https://github.com/realtime-intelligence/evrt-detr
Mitigating Parameter Degeneracy using Joint Conditional Diffusion Model for WECC Composite Load Model in Power Systems
Nov 15, 2024Data-driven modeling for dynamic systems has gained widespread attention in recent years. Its inverse formulation, parameter estimation, aims to infer the inherent model parameters from observations. However, parameter degeneracy, where different combinations of parameters yield the same observable output, poses a critical barrier to accurately and uniquely identifying model parameters. In the context of WECC composite load model (CLM) in power systems, utility practitioners have observed that CLM parameters carefully selected for one fault event may not perform satisfactorily in another fault. Here, we innovate a joint conditional diffusion model-based inverse problem solver (JCDI), that incorporates a joint conditioning architecture with simultaneous inputs of multi-event observations to improve parameter generalizability. Simulation studies on the WECC CLM show that the proposed JCDI effectively reduces uncertainties of degenerate parameters, thus the parameter estimation error is decreased by 42.1% compared to a single-event learning scheme. This enables the model to achieve high accuracy in predicting power trajectories under different fault events, including electronic load tripping and motor stalling, outperforming standard deep reinforcement learning and supervised learning approaches. We anticipate this work will contribute to mitigating parameter degeneracy in system dynamics, providing a general parameter estimation framework across various scientific domains.
Unsupervised Domain Transfer for Science: Exploring Deep Learning Methods for Translation between LArTPC Detector Simulations with Differing Response Models
May 05, 2023Deep learning (DL) techniques have broad applications in science, especially in seeking to streamline the pathway to potential solutions and discoveries. Frequently, however, DL models are trained on the results of simulation yet applied to real experimental data. As such, any systematic differences between the simulated and real data may degrade the model's performance -- an effect known as "domain shift." This work studies a toy model of the systematic differences between simulated and real data. It presents a fully unsupervised, task-agnostic method to reduce differences between two systematically different samples. The method is based on the recent advances in unpaired image-to-image translation techniques and is validated on two sets of samples of simulated Liquid Argon Time Projection Chamber (LArTPC) detector events, created to illustrate common systematic differences between the simulated and real data in a controlled way. LArTPC-based detectors represent the next-generation particle detectors, producing unique high-resolution particle track data. This work open-sources the generated LArTPC data set, called Simple Liquid-Argon Track Samples (or SLATS), allowing researchers from diverse domains to study the LArTPC-like data for the first time. The code and trained models are available at https://github.com/LS4GAN/uvcgan4slats.
Rethinking CycleGAN: Improving Quality of GANs for Unpaired Image-to-Image Translation
Mar 28, 2023An unpaired image-to-image (I2I) translation technique seeks to find a mapping between two domains of data in a fully unsupervised manner. While the initial solutions to the I2I problem were provided by the generative adversarial neural networks (GANs), currently, diffusion models (DM) hold the state-of-the-art status on the I2I translation benchmarks in terms of FID. Yet, they suffer from some limitations, such as not using data from the source domain during the training, or maintaining consistency of the source and translated images only via simple pixel-wise errors. This work revisits the classic CycleGAN model and equips it with recent advancements in model architectures and model training procedures. The revised model is shown to significantly outperform other advanced GAN- and DM-based competitors on a variety of benchmarks. In the case of Male2Female translation of CelebA, the model achieves over 40% improvement in FID score compared to the state-of-the-art results. This work also demonstrates the ineffectiveness of the pixel-wise I2I translation faithfulness metrics and suggests their revision. The code and trained models are available at https://github.com/LS4GAN/uvcgan2
UVCGAN: UNet Vision Transformer cycle-consistent GAN for unpaired image-to-image translation
Mar 21, 2022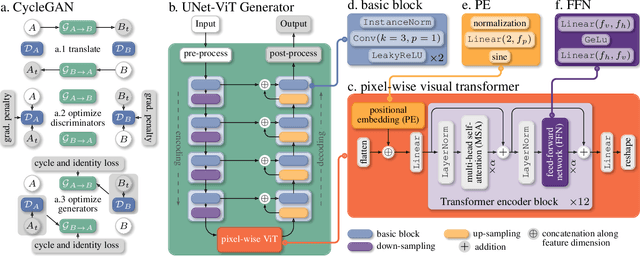


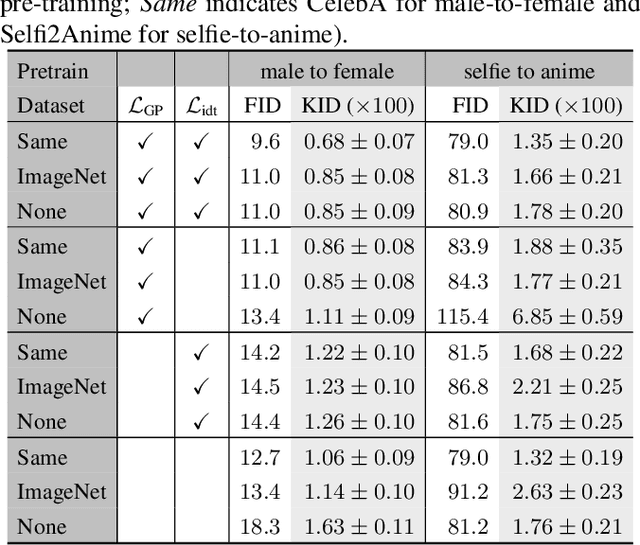
Image-to-image translation has broad applications in art, design, and scientific simulations. The original CycleGAN model emphasizes one-to-one mapping via a cycle-consistent loss, while more recent works promote one-to-many mapping to boost the diversity of the translated images. With scientific simulation and one-to-one needs in mind, this work examines if equipping CycleGAN with a vision transformer (ViT) and employing advanced generative adversarial network (GAN) training techniques can achieve better performance. The resulting UNet ViT Cycle-consistent GAN (UVCGAN) model is compared with previous best-performing models on open benchmark image-to-image translation datasets, Selfie2Anime and CelebA. UVCGAN performs better and retains a strong correlation between the original and translated images. An accompanying ablation study shows that the gradient penalty and BERT-like pre-training also contribute to the improvement.~To promote reproducibility and open science, the source code, hyperparameter configurations, and pre-trained model will be made available at: https://github.com/LS4GAN/uvcgan.