 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUVCGAN: UNet Vision Transformer cycle-consistent GAN for unpaired image-to-image translation
Paper and Code
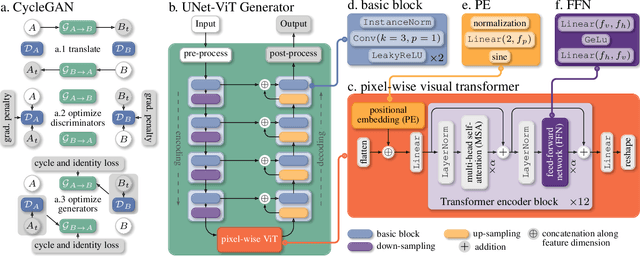


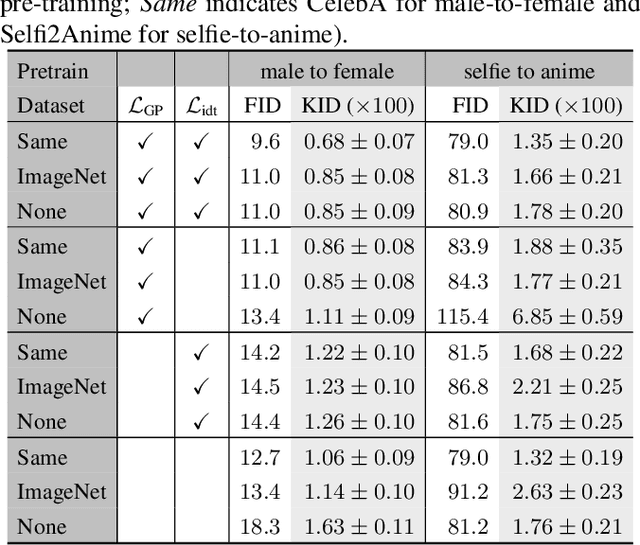
Image-to-image translation has broad applications in art, design, and scientific simulations. The original CycleGAN model emphasizes one-to-one mapping via a cycle-consistent loss, while more recent works promote one-to-many mapping to boost the diversity of the translated images. With scientific simulation and one-to-one needs in mind, this work examines if equipping CycleGAN with a vision transformer (ViT) and employing advanced generative adversarial network (GAN) training techniques can achieve better performance. The resulting UNet ViT Cycle-consistent GAN (UVCGAN) model is compared with previous best-performing models on open benchmark image-to-image translation datasets, Selfie2Anime and CelebA. UVCGAN performs better and retains a strong correlation between the original and translated images. An accompanying ablation study shows that the gradient penalty and BERT-like pre-training also contribute to the improvement.~To promote reproducibility and open science, the source code, hyperparameter configurations, and pre-trained model will be made available at: https://github.com/LS4GAN/uvcgan.