 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier neural operators for spatiotemporal dynamics in two-dimensional turbulence
Sep 25, 2024High-fidelity direct numerical simulation of turbulent flows for most real-world applications remains an outstanding computational challenge. Several machine learning approaches have recently been proposed to alleviate the computational cost even though they become unstable or unphysical for long time predictions. We identify that the Fourier neural operator (FNO) based models combined with a partial differential equation (PDE) solver can accelerate fluid dynamic simulations and thus address computational expense of large-scale turbulence simulations. We treat the FNO model on the same footing as a PDE solver and answer important questions about the volume and temporal resolution of data required to build pre-trained models for turbulence. We also discuss the pitfalls of purely data-driven approaches that need to be avoided by the machine learning models to become viable and competitive tools for long time simulations of turbulence.
Unsupervised Domain Transfer for Science: Exploring Deep Learning Methods for Translation between LArTPC Detector Simulations with Differing Response Models
May 05, 2023Deep learning (DL) techniques have broad applications in science, especially in seeking to streamline the pathway to potential solutions and discoveries. Frequently, however, DL models are trained on the results of simulation yet applied to real experimental data. As such, any systematic differences between the simulated and real data may degrade the model's performance -- an effect known as "domain shift." This work studies a toy model of the systematic differences between simulated and real data. It presents a fully unsupervised, task-agnostic method to reduce differences between two systematically different samples. The method is based on the recent advances in unpaired image-to-image translation techniques and is validated on two sets of samples of simulated Liquid Argon Time Projection Chamber (LArTPC) detector events, created to illustrate common systematic differences between the simulated and real data in a controlled way. LArTPC-based detectors represent the next-generation particle detectors, producing unique high-resolution particle track data. This work open-sources the generated LArTPC data set, called Simple Liquid-Argon Track Samples (or SLATS), allowing researchers from diverse domains to study the LArTPC-like data for the first time. The code and trained models are available at https://github.com/LS4GAN/uvcgan4slats.
Rethinking CycleGAN: Improving Quality of GANs for Unpaired Image-to-Image Translation
Mar 28, 2023An unpaired image-to-image (I2I) translation technique seeks to find a mapping between two domains of data in a fully unsupervised manner. While the initial solutions to the I2I problem were provided by the generative adversarial neural networks (GANs), currently, diffusion models (DM) hold the state-of-the-art status on the I2I translation benchmarks in terms of FID. Yet, they suffer from some limitations, such as not using data from the source domain during the training, or maintaining consistency of the source and translated images only via simple pixel-wise errors. This work revisits the classic CycleGAN model and equips it with recent advancements in model architectures and model training procedures. The revised model is shown to significantly outperform other advanced GAN- and DM-based competitors on a variety of benchmarks. In the case of Male2Female translation of CelebA, the model achieves over 40% improvement in FID score compared to the state-of-the-art results. This work also demonstrates the ineffectiveness of the pixel-wise I2I translation faithfulness metrics and suggests their revision. The code and trained models are available at https://github.com/LS4GAN/uvcgan2
UVCGAN: UNet Vision Transformer cycle-consistent GAN for unpaired image-to-image translation
Mar 21, 2022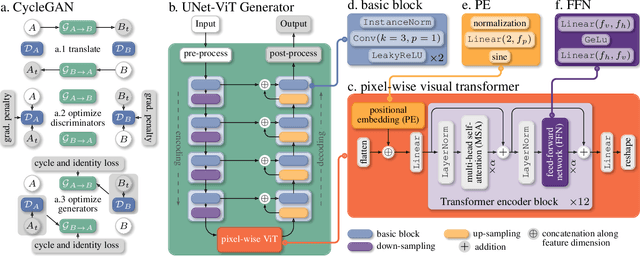


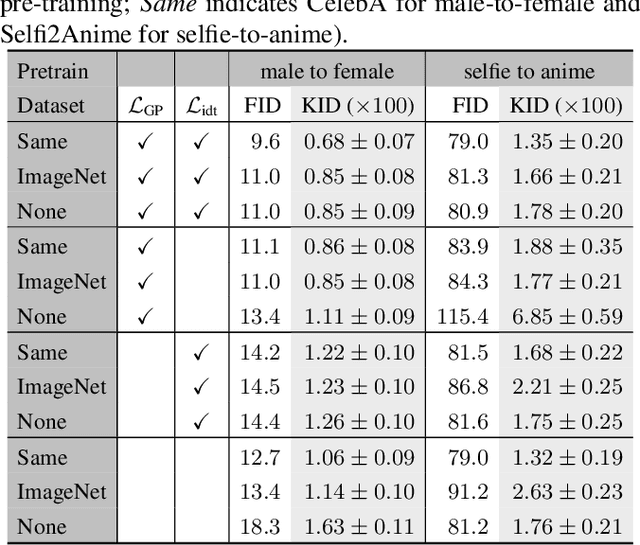
Image-to-image translation has broad applications in art, design, and scientific simulations. The original CycleGAN model emphasizes one-to-one mapping via a cycle-consistent loss, while more recent works promote one-to-many mapping to boost the diversity of the translated images. With scientific simulation and one-to-one needs in mind, this work examines if equipping CycleGAN with a vision transformer (ViT) and employing advanced generative adversarial network (GAN) training techniques can achieve better performance. The resulting UNet ViT Cycle-consistent GAN (UVCGAN) model is compared with previous best-performing models on open benchmark image-to-image translation datasets, Selfie2Anime and CelebA. UVCGAN performs better and retains a strong correlation between the original and translated images. An accompanying ablation study shows that the gradient penalty and BERT-like pre-training also contribute to the improvement.~To promote reproducibility and open science, the source code, hyperparameter configurations, and pre-trained model will be made available at: https://github.com/LS4GAN/uvcgan.