 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable Rate Neural Compression for Sparse Detector Data
Nov 18, 2024High-energy large-scale particle colliders generate data at extraordinary rates. Developing real-time high-throughput data compression algorithms to reduce data volume and meet the bandwidth requirement for storage has become increasingly critical. Deep learning is a promising technology that can address this challenging topic. At the newly constructed sPHENIX experiment at the Relativistic Heavy Ion Collider, a Time Projection Chamber (TPC) serves as the main tracking detector, which records three-dimensional particle trajectories in a volume of a gas-filled cylinder. In terms of occupancy, the resulting data flow can be very sparse reaching $10^{-3}$ for proton-proton collisions. Such sparsity presents a challenge to conventional learning-free lossy compression algorithms, such as SZ, ZFP, and MGARD. In contrast, emerging deep learning-based models, particularly those utilizing convolutional neural networks for compression, have outperformed these conventional methods in terms of compression ratios and reconstruction accuracy. However, research on the efficacy of these deep learning models in handling sparse datasets, like those produced in particle colliders, remains limited. Furthermore, most deep learning models do not adapt their processing speeds to data sparsity, which affects efficiency. To address this issue, we propose a novel approach for TPC data compression via key-point identification facilitated by sparse convolution. Our proposed algorithm, BCAE-VS, achieves a $75\%$ improvement in reconstruction accuracy with a $10\%$ increase in compression ratio over the previous state-of-the-art model. Additionally, BCAE-VS manages to achieve these results with a model size over two orders of magnitude smaller. Lastly, we have experimentally verified that as sparsity increases, so does the model's throughput.
Exploring Level Blending across Platformers via Paths and Affordances
Aug 22, 2020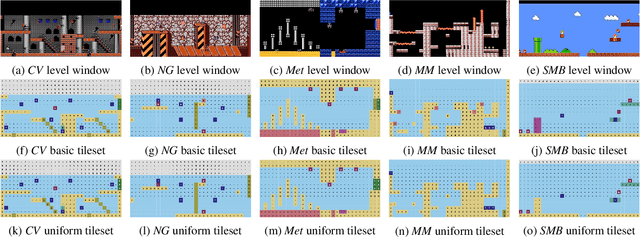
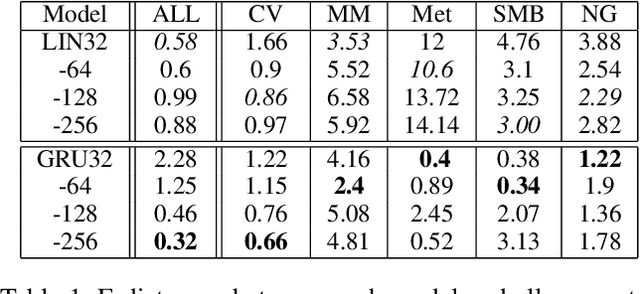

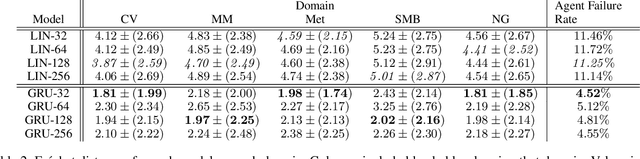
Techniques for procedural content generation via machine learning (PCGML) have been shown to be useful for generating novel game content. While used primarily for producing new content in the style of the game domain used for training, recent works have increasingly started to explore methods for discovering and generating content in novel domains via techniques such as level blending and domain transfer. In this paper, we build on these works and introduce a new PCGML approach for producing novel game content spanning multiple domains. We use a new affordance and path vocabulary to encode data from six different platformer games and train variational autoencoders on this data, enabling us to capture the latent level space spanning all the domains and generate new content with varying proportions of the different domains.
CHARDA: Causal Hybrid Automata Recovery via Dynamic Analysis
Jul 11, 2017
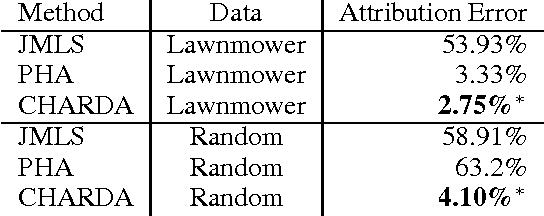

We propose and evaluate a new technique for learning hybrid automata automatically by observing the runtime behavior of a dynamical system. Working from a sequence of continuous state values and predicates about the environment, CHARDA recovers the distinct dynamic modes, learns a model for each mode from a given set of templates, and postulates causal guard conditions which trigger transitions between modes. Our main contribution is the use of information-theoretic measures (1)~as a cost function for data segmentation and model selection to penalize over-fitting and (2)~to determine the likely causes of each transition. CHARDA is easily extended with different classes of model templates, fitting methods, or predicates. In our experiments on a complex videogame character, CHARDA successfully discovers a reasonable over-approximation of the character's true behaviors. Our results also compare favorably against recent work in automatically learning probabilistic timed automata in an aircraft domain: CHARDA exactly learns the modes of these simpler automata.