 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
Towards an Introspective Dynamic Model of Globally Distributed Computing Infrastructures
Jun 24, 2025Large-scale scientific collaborations like ATLAS, Belle II, CMS, DUNE, and others involve hundreds of research institutes and thousands of researchers spread across the globe. These experiments generate petabytes of data, with volumes soon expected to reach exabytes. Consequently, there is a growing need for computation, including structured data processing from raw data to consumer-ready derived data, extensive Monte Carlo simulation campaigns, and a wide range of end-user analysis. To manage these computational and storage demands, centralized workflow and data management systems are implemented. However, decisions regarding data placement and payload allocation are often made disjointly and via heuristic means. A significant obstacle in adopting more effective heuristic or AI-driven solutions is the absence of a quick and reliable introspective dynamic model to evaluate and refine alternative approaches. In this study, we aim to develop such an interactive system using real-world data. By examining job execution records from the PanDA workflow management system, we have pinpointed key performance indicators such as queuing time, error rate, and the extent of remote data access. The dataset includes five months of activity. Additionally, we are creating a generative AI model to simulate time series of payloads, which incorporate visible features like category, event count, and submitting group, as well as hidden features like the total computational load-derived from existing PanDA records and computing site capabilities. These hidden features, which are not visible to job allocators, whether heuristic or AI-driven, influence factors such as queuing times and data movement.
A Comprehensive Evaluation of Contemporary ML-Based Solvers for Combinatorial Optimization
May 22, 2025Machine learning (ML) has demonstrated considerable potential in supporting model design and optimization for combinatorial optimization (CO) problems. However, much of the progress to date has been evaluated on small-scale, synthetic datasets, raising concerns about the practical effectiveness of ML-based solvers in real-world, large-scale CO scenarios. Additionally, many existing CO benchmarks lack sufficient training data, limiting their utility for evaluating data-driven approaches. To address these limitations, we introduce FrontierCO, a comprehensive benchmark that covers eight canonical CO problem types and evaluates 16 representative ML-based solvers--including graph neural networks and large language model (LLM) agents. FrontierCO features challenging instances drawn from industrial applications and frontier CO research, offering both realistic problem difficulty and abundant training data. Our empirical results provide critical insights into the strengths and limitations of current ML methods, helping to guide more robust and practically relevant advances at the intersection of machine learning and combinatorial optimization. Our data is available at https://huggingface.co/datasets/CO-Bench/FrontierCO.
CO-Bench: Benchmarking Language Model Agents in Algorithm Search for Combinatorial Optimization
Apr 06, 2025Although LLM-based agents have attracted significant attention in domains such as software engineering and machine learning research, their role in advancing combinatorial optimization (CO) remains relatively underexplored. This gap underscores the need for a deeper understanding of their potential in tackling structured, constraint-intensive problems-a pursuit currently limited by the absence of comprehensive benchmarks for systematic investigation. To address this, we introduce CO-Bench, a benchmark suite featuring 36 real-world CO problems drawn from a broad range of domains and complexity levels. CO-Bench includes structured problem formulations and curated data to support rigorous investigation of LLM agents. We evaluate multiple agent frameworks against established human-designed algorithms, revealing key strengths and limitations of current approaches and identifying promising directions for future research. CO-Bench is publicly available at https://github.com/sunnweiwei/CO-Bench.
SORREL: Suboptimal-Demonstration-Guided Reinforcement Learning for Learning to Branch
Dec 20, 2024Mixed Integer Linear Program (MILP) solvers are mostly built upon a Branch-and-Bound (B\&B) algorithm, where the efficiency of traditional solvers heavily depends on hand-crafted heuristics for branching. The past few years have witnessed the increasing popularity of data-driven approaches to automatically learn these heuristics. However, the success of these methods is highly dependent on the availability of high-quality demonstrations, which requires either the development of near-optimal heuristics or a time-consuming sampling process. This paper averts this challenge by proposing Suboptimal-Demonstration-Guided Reinforcement Learning (SORREL) for learning to branch. SORREL selectively learns from suboptimal demonstrations based on value estimation. It utilizes suboptimal demonstrations through both offline reinforcement learning on the demonstrations generated by suboptimal heuristics and self-imitation learning on past good experiences sampled by itself. Our experiments demonstrate its advanced performance in both branching quality and training efficiency over previous methods for various MILPs.
Step-by-Step Reasoning for Math Problems via Twisted Sequential Monte Carlo
Oct 02, 2024



Augmenting the multi-step reasoning abilities of Large Language Models (LLMs) has been a persistent challenge. Recently, verification has shown promise in improving solution consistency by evaluating generated outputs. However, current verification approaches suffer from sampling inefficiencies, requiring a large number of samples to achieve satisfactory performance. Additionally, training an effective verifier often depends on extensive process supervision, which is costly to acquire. In this paper, we address these limitations by introducing a novel verification method based on Twisted Sequential Monte Carlo (TSMC). TSMC sequentially refines its sampling effort to focus exploration on promising candidates, resulting in more efficient generation of high-quality solutions. We apply TSMC to LLMs by estimating the expected future rewards at partial solutions. This approach results in a more straightforward training target that eliminates the need for step-wise human annotations. We empirically demonstrate the advantages of our method across multiple math benchmarks, and also validate our theoretical analysis of both our approach and existing verification methods.
Concept Discovery for Fast Adapatation
Jan 19, 2023



The advances in deep learning have enabled machine learning methods to outperform human beings in various areas, but it remains a great challenge for a well-trained model to quickly adapt to a new task. One promising solution to realize this goal is through meta-learning, also known as learning to learn, which has achieved promising results in few-shot learning. However, current approaches are still enormously different from human beings' learning process, especially in the ability to extract structural and transferable knowledge. This drawback makes current meta-learning frameworks non-interpretable and hard to extend to more complex tasks. We tackle this problem by introducing concept discovery to the few-shot learning problem, where we achieve more effective adaptation by meta-learning the structure among the data features, leading to a composite representation of the data. Our proposed method Concept-Based Model-Agnostic Meta-Learning (COMAML) has been shown to achieve consistent improvements in the structured data for both synthesized datasets and real-world datasets.
ARIEL: Adversarial Graph Contrastive Learning
Aug 15, 2022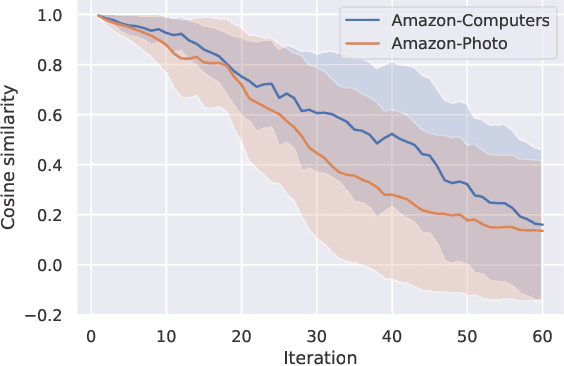
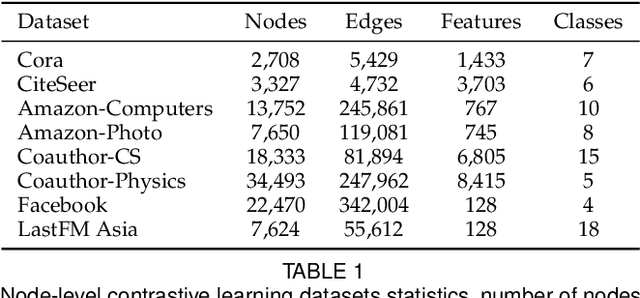
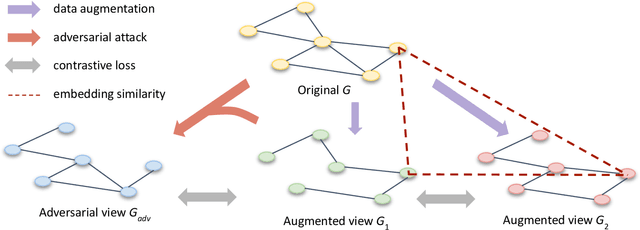
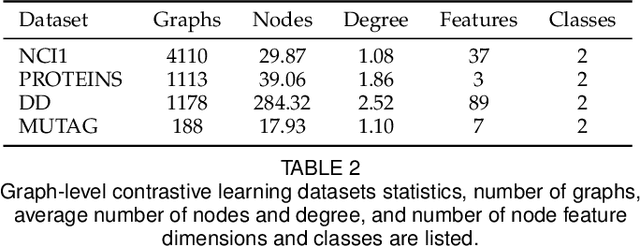
Contrastive learning is an effective unsupervised method in graph representation learning, and the key component of contrastive learning lies in the construction of positive and negative samples. Previous methods usually utilize the proximity of nodes in the graph as the principle. Recently, the data augmentation based contrastive learning method has advanced to show great power in the visual domain, and some works extended this method from images to graphs. However, unlike the data augmentation on images, the data augmentation on graphs is far less intuitive and much harder to provide high-quality contrastive samples, which leaves much space for improvement. In this work, by introducing an adversarial graph view for data augmentation, we propose a simple but effective method, Adversarial Graph Contrastive Learning (ARIEL), to extract informative contrastive samples within reasonable constraints. We develop a new technique called information regularization for stable training and use subgraph sampling for scalability. We generalize our method from node-level contrastive learning to the graph-level by treating each graph instance as a supernode. ARIEL consistently outperforms the current graph contrastive learning methods for both node-level and graph-level classification tasks on real-world datasets. We further demonstrate that ARIEL is more robust in face of adversarial attacks.
Adversarial Graph Contrastive Learning with Information Regularization
Mar 03, 2022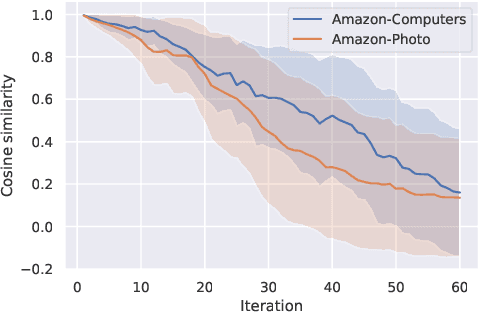
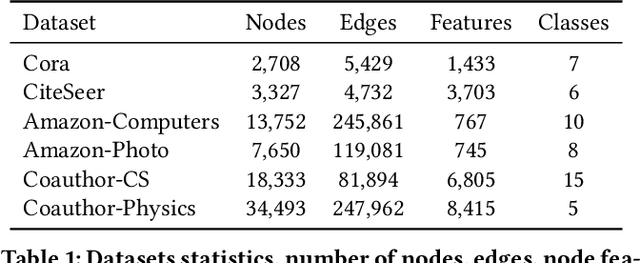


Contrastive learning is an effective unsupervised method in graph representation learning. Recently, the data augmentation based contrastive learning method has been extended from images to graphs. However, most prior works are directly adapted from the models designed for images. Unlike the data augmentation on images, the data augmentation on graphs is far less intuitive and much harder to provide high-quality contrastive samples, which are the key to the performance of contrastive learning models. This leaves much space for improvement over the existing graph contrastive learning frameworks. In this work, by introducing an adversarial graph view and an information regularizer, we propose a simple but effective method, Adversarial Graph Contrastive Learning (ARIEL), to extract informative contrastive samples within a reasonable constraint. It consistently outperforms the current graph contrastive learning methods in the node classification task over various real-world datasets and further improves the robustness of graph contrastive learning.
Exploiting Long-Term Dependencies for Generating Dynamic Scene Graphs
Dec 18, 2021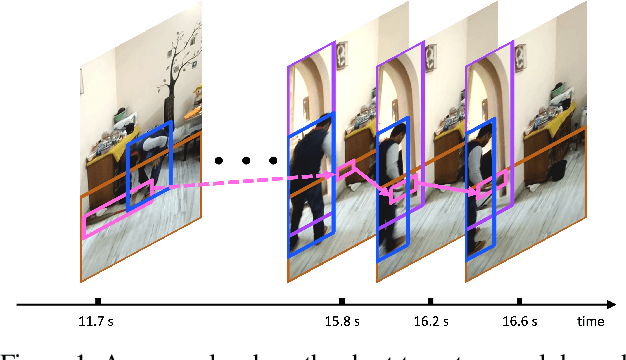
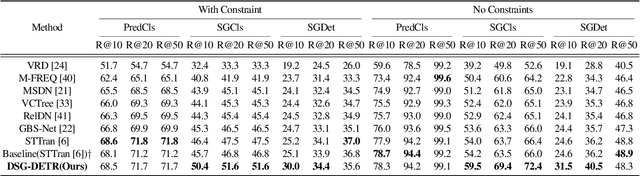
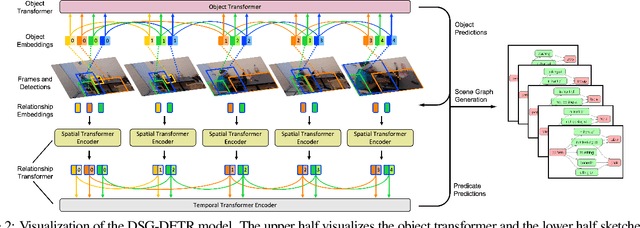
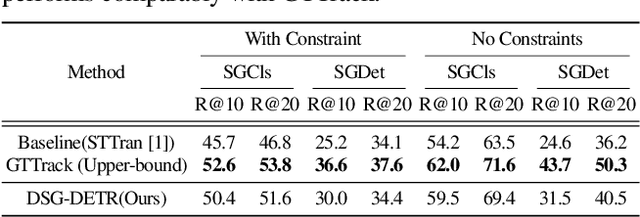
Structured video representation in the form of dynamic scene graphs is an effective tool for several video understanding tasks. Compared to the task of scene graph generation from images, dynamic scene graph generation is more challenging due to the temporal dynamics of the scene and the inherent temporal fluctuations of predictions. We show that capturing long-term dependencies is the key to effective generation of dynamic scene graphs. We present the detect-track-recognize paradigm by constructing consistent long-term object tracklets from a video, followed by transformers to capture the dynamics of objects and visual relations. Experimental results demonstrate that our Dynamic Scene Graph Detection Transformer (DSG-DETR) outperforms state-of-the-art methods by a significant margin on the benchmark dataset Action Genome. We also perform ablation studies and validate the effectiveness of each component of the proposed approach.