 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic bootstrapped pretraining
Sep 17, 2025We introduce Synthetic Bootstrapped Pretraining (SBP), a language model (LM) pretraining procedure that first learns a model of relations between documents from the pretraining dataset and then leverages it to synthesize a vast new corpus for joint training. While the standard pretraining teaches LMs to learn causal correlations among tokens within a single document, it is not designed to efficiently model the rich, learnable inter-document correlations that can potentially lead to better performance. We validate SBP by designing a compute-matched pretraining setup and pretrain a 3B-parameter model on up to 1T tokens from scratch. We find SBP consistently improves upon a strong repetition baseline and delivers a significant fraction of performance improvement attainable by an oracle upper bound with access to 20x more unique data. Qualitative analysis reveals that the synthesized documents go beyond mere paraphrases -- SBP first abstracts a core concept from the seed material and then crafts a new narration on top of it. Besides strong empirical performance, SBP admits a natural Bayesian interpretation: the synthesizer implicitly learns to abstract the latent concepts shared between related documents.
Step-by-Step Reasoning for Math Problems via Twisted Sequential Monte Carlo
Oct 02, 2024



Augmenting the multi-step reasoning abilities of Large Language Models (LLMs) has been a persistent challenge. Recently, verification has shown promise in improving solution consistency by evaluating generated outputs. However, current verification approaches suffer from sampling inefficiencies, requiring a large number of samples to achieve satisfactory performance. Additionally, training an effective verifier often depends on extensive process supervision, which is costly to acquire. In this paper, we address these limitations by introducing a novel verification method based on Twisted Sequential Monte Carlo (TSMC). TSMC sequentially refines its sampling effort to focus exploration on promising candidates, resulting in more efficient generation of high-quality solutions. We apply TSMC to LLMs by estimating the expected future rewards at partial solutions. This approach results in a more straightforward training target that eliminates the need for step-wise human annotations. We empirically demonstrate the advantages of our method across multiple math benchmarks, and also validate our theoretical analysis of both our approach and existing verification methods.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Revisiting MoE and Dense Speed-Accuracy Comparisons for LLM Training
May 23, 2024



Mixture-of-Experts (MoE) enjoys performance gain by increasing model capacity while keeping computation cost constant. When comparing MoE to dense models, prior work typically adopt the following setting: 1) use FLOPs or activated parameters as a measure of model complexity; 2) train all models to the same number of tokens. We argue that this setting favors MoE as FLOPs and activated parameters do not accurately measure the communication overhead in sparse layers, leading to a larger actual training budget for MoE. In this work, we revisit the settings by adopting step time as a more accurate measure of model complexity, and by determining the total compute budget under the Chinchilla compute-optimal settings. To efficiently run MoE on modern accelerators, we adopt a 3D sharding method that keeps the dense-to-MoE step time increase within a healthy range. We evaluate MoE and dense LLMs on a set of nine 0-shot and two 1-shot English tasks, as well as MMLU 5-shot and GSM8K 8-shot across three model scales at 6.4B, 12.6B, and 29.6B. Experimental results show that even under these settings, MoE consistently outperform dense LLMs on the speed-accuracy trade-off curve with meaningful gaps. Our full model implementation and sharding strategy will be released at~\url{https://github.com/apple/axlearn}
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Mar 22, 2024



In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
Recurrent Drafter for Fast Speculative Decoding in Large Language Models
Mar 22, 2024



In this paper, we introduce an improved approach of speculative decoding aimed at enhancing the efficiency of serving large language models. Our method capitalizes on the strengths of two established techniques: the classic two-model speculative decoding approach, and the more recent single-model approach, Medusa. Drawing inspiration from Medusa, our approach adopts a single-model strategy for speculative decoding. However, our method distinguishes itself by employing a single, lightweight draft head with a recurrent dependency design, akin in essence to the small, draft model uses in classic speculative decoding, but without the complexities of the full transformer architecture. And because of the recurrent dependency, we can use beam search to swiftly filter out undesired candidates with the draft head. The outcome is a method that combines the simplicity of single-model design and avoids the need to create a data-dependent tree attention structure only for inference in Medusa. We empirically demonstrate the effectiveness of the proposed method on several popular open source language models, along with a comprehensive analysis of the trade-offs involved in adopting this approach.
Divide-or-Conquer? Which Part Should You Distill Your LLM?
Feb 22, 2024



Recent methods have demonstrated that Large Language Models (LLMs) can solve reasoning tasks better when they are encouraged to solve subtasks of the main task first. In this paper we devise a similar strategy that breaks down reasoning tasks into a problem decomposition phase and a problem solving phase and show that the strategy is able to outperform a single stage solution. Further, we hypothesize that the decomposition should be easier to distill into a smaller model compared to the problem solving because the latter requires large amounts of domain knowledge while the former only requires learning general problem solving strategies. We propose methods to distill these two capabilities and evaluate their impact on reasoning outcomes and inference cost. We find that we can distill the problem decomposition phase and at the same time achieve good generalization across tasks, datasets, and models. However, it is harder to distill the problem solving capability without losing performance and the resulting distilled model struggles with generalization. These results indicate that by using smaller, distilled problem decomposition models in combination with problem solving LLMs we can achieve reasoning with cost-efficient inference and local adaptation.
Graph-Based Model-Agnostic Data Subsampling for Recommendation Systems
May 25, 2023Data subsampling is widely used to speed up the training of large-scale recommendation systems. Most subsampling methods are model-based and often require a pre-trained pilot model to measure data importance via e.g. sample hardness. However, when the pilot model is misspecified, model-based subsampling methods deteriorate. Since model misspecification is persistent in real recommendation systems, we instead propose model-agnostic data subsampling methods by only exploring input data structure represented by graphs. Specifically, we study the topology of the user-item graph to estimate the importance of each user-item interaction (an edge in the user-item graph) via graph conductance, followed by a propagation step on the network to smooth out the estimated importance value. Since our proposed method is model-agnostic, we can marry the merits of both model-agnostic and model-based subsampling methods. Empirically, we show that combing the two consistently improves over any single method on the used datasets. Experimental results on KuaiRec and MIND datasets demonstrate that our proposed methods achieve superior results compared to baseline approaches.
NVDiff: Graph Generation through the Diffusion of Node Vectors
Nov 19, 2022



Learning to generate graphs is challenging as a graph is a set of pairwise connected, unordered nodes encoding complex combinatorial structures. Recently, several works have proposed graph generative models based on normalizing flows or score-based diffusion models. However, these models need to generate nodes and edges in parallel from the same process, whose dimensionality is unnecessarily high. We propose NVDiff, which takes the VGAE structure and uses a score-based generative model (SGM) as a flexible prior to sample node vectors. By modeling only node vectors in the latent space, NVDiff significantly reduces the dimension of the diffusion process and thus improves sampling speed. Built on the NVDiff framework, we introduce an attention-based score network capable of capturing both local and global contexts of graphs. Experiments indicate that NVDiff significantly reduces computations and can model much larger graphs than competing methods. At the same time, it achieves superior or competitive performances over various datasets compared to previous methods.
Collaborative Anomaly Detection
Sep 20, 2022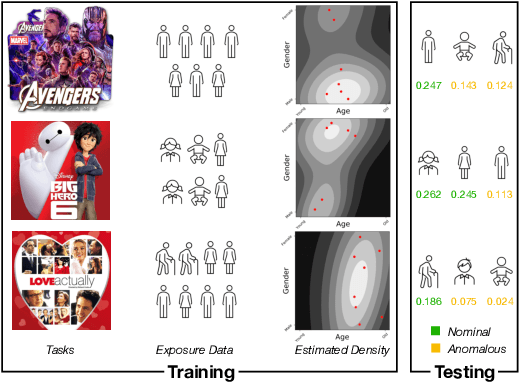
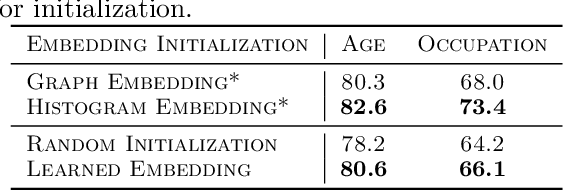
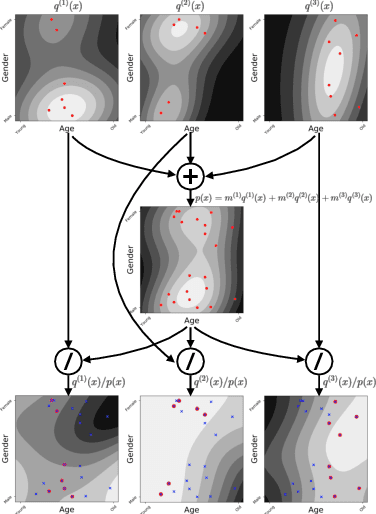

In recommendation systems, items are likely to be exposed to various users and we would like to learn about the familiarity of a new user with an existing item. This can be formulated as an anomaly detection (AD) problem distinguishing between "common users" (nominal) and "fresh users" (anomalous). Considering the sheer volume of items and the sparsity of user-item paired data, independently applying conventional single-task detection methods on each item quickly becomes difficult, while correlations between items are ignored. To address this multi-task anomaly detection problem, we propose collaborative anomaly detection (CAD) to jointly learn all tasks with an embedding encoding correlations among tasks. We explore CAD with conditional density estimation and conditional likelihood ratio estimation. We found that: $i$) estimating a likelihood ratio enjoys more efficient learning and yields better results than density estimation. $ii$) It is beneficial to select a small number of tasks in advance to learn a task embedding model, and then use it to warm-start all task embeddings. Consequently, these embeddings can capture correlations between tasks and generalize to new correlated tasks.