 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTourPlanner: A Competitive Consensus Framework with Constraint-Gated Reinforcement Learning for Travel Planning
Jan 08, 2026Travel planning is a sophisticated decision-making process that requires synthesizing multifaceted information to construct itineraries. However, existing travel planning approaches face several challenges: (1) Pruning candidate points of interest (POIs) while maintaining a high recall rate; (2) A single reasoning path restricts the exploration capability within the feasible solution space for travel planning; (3) Simultaneously optimizing hard constraints and soft constraints remains a significant difficulty. To address these challenges, we propose TourPlanner, a comprehensive framework featuring multi-path reasoning and constraint-gated reinforcement learning. Specifically, we first introduce a Personalized Recall and Spatial Optimization (PReSO) workflow to construct spatially-aware candidate POIs' set. Subsequently, we propose Competitive consensus Chain-of-Thought (CCoT), a multi-path reasoning paradigm that improves the ability of exploring the feasible solution space. To further refine the plan, we integrate a sigmoid-based gating mechanism into the reinforcement learning stage, which dynamically prioritizes soft-constraint satisfaction only after hard constraints are met. Experimental results on travel planning benchmarks demonstrate that TourPlanner achieves state-of-the-art performance, significantly surpassing existing methods in both feasibility and user-preference alignment.
Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
Nov 16, 2025We present Uni-MoE 2.0 from the Lychee family. As a fully open-source omnimodal large model (OLM), it substantially advances Lychee's Uni-MoE series in language-centric multimodal understanding, reasoning, and generating. Based on the Qwen2.5-7B dense architecture, we build Uni-MoE-2.0-Omni from scratch through three core contributions: dynamic-capacity Mixture-of-Experts (MoE) design, a progressive training strategy enhanced with an iterative reinforcement strategy, and a carefully curated multimodal data matching technique. It is capable of omnimodal understanding, as well as generating images, text, and speech. Architecturally, our new MoE framework balances computational efficiency and capability for 10 cross-modal inputs using shared, routed, and null experts, while our Omni-Modality 3D RoPE ensures spatio-temporal cross-modality alignment in the self-attention layer. For training, following cross-modal pretraining, we use a progressive supervised fine-tuning strategy that activates modality-specific experts and is enhanced by balanced data composition and an iterative GSPO-DPO method to stabilise RL training and improve reasoning. Data-wise, the base model, trained on approximately 75B tokens of open-source multimodal data, is equipped with special speech and image generation tokens, allowing it to learn these generative tasks by conditioning its outputs on linguistic cues. Extensive evaluation across 85 benchmarks demonstrates that our model achieves SOTA or highly competitive performance against leading OLMs, surpassing Qwen2.5-Omni (trained with 1.2T tokens) on over 50 of 76 benchmarks. Key strengths include video understanding (+7% avg. of 8), omnimodallity understanding (+7% avg. of 4), and audiovisual reasoning (+4%). It also advances long-form speech processing (reducing WER by 4.2%) and leads in low-level image processing and controllable generation across 5 metrics.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
AvatarShield: Visual Reinforcement Learning for Human-Centric Video Forgery Detection
May 21, 2025The rapid advancement of Artificial Intelligence Generated Content (AIGC) technologies, particularly in video generation, has led to unprecedented creative capabilities but also increased threats to information integrity, identity security, and public trust. Existing detection methods, while effective in general scenarios, lack robust solutions for human-centric videos, which pose greater risks due to their realism and potential for legal and ethical misuse. Moreover, current detection approaches often suffer from poor generalization, limited scalability, and reliance on labor-intensive supervised fine-tuning. To address these challenges, we propose AvatarShield, the first interpretable MLLM-based framework for detecting human-centric fake videos, enhanced via Group Relative Policy Optimization (GRPO). Through our carefully designed accuracy detection reward and temporal compensation reward, it effectively avoids the use of high-cost text annotation data, enabling precise temporal modeling and forgery detection. Meanwhile, we design a dual-encoder architecture, combining high-level semantic reasoning and low-level artifact amplification to guide MLLMs in effective forgery detection. We further collect FakeHumanVid, a large-scale human-centric video benchmark that includes synthesis methods guided by pose, audio, and text inputs, enabling rigorous evaluation of detection methods in real-world scenes. Extensive experiments show that AvatarShield significantly outperforms existing approaches in both in-domain and cross-domain detection, setting a new standard for human-centric video forensics.
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025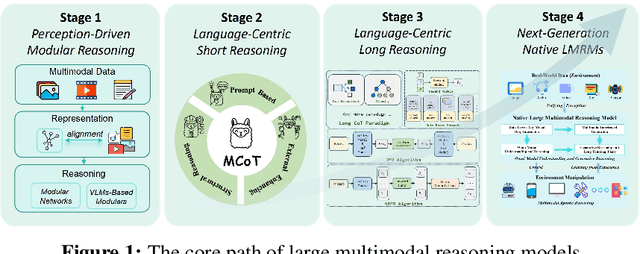
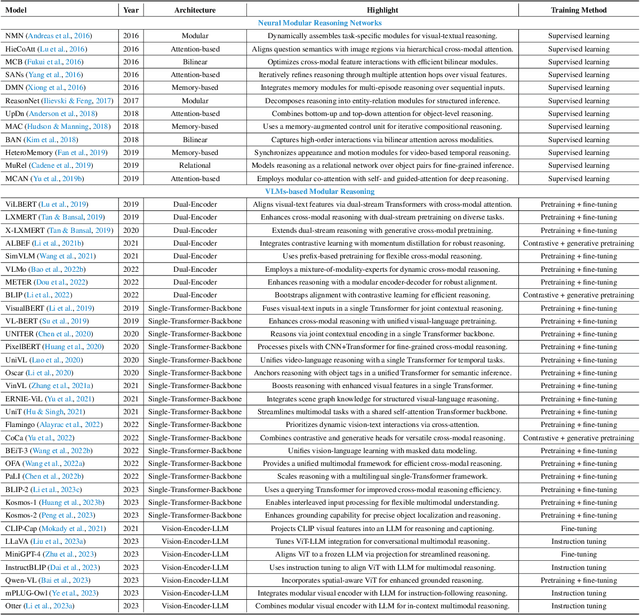
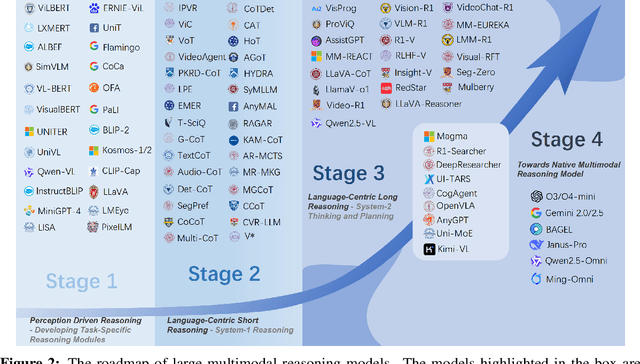
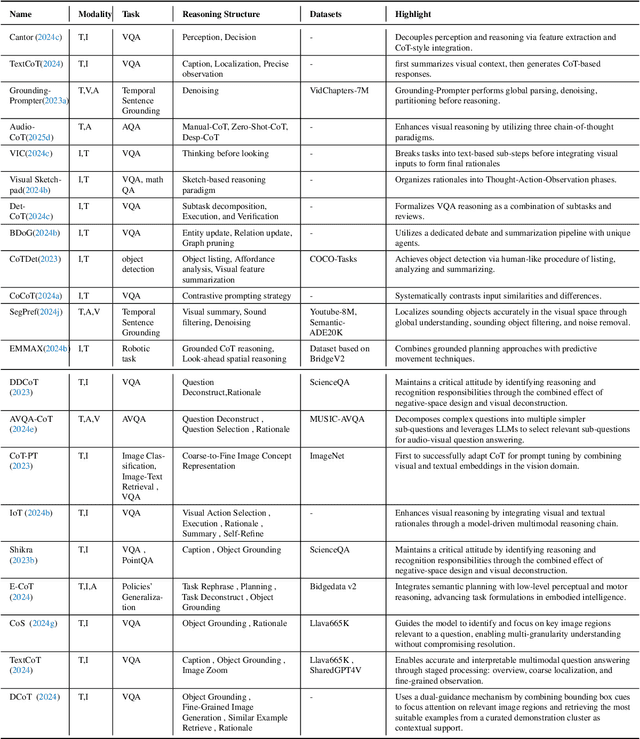
Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
Q-Insight: Understanding Image Quality via Visual Reinforcement Learning
Mar 28, 2025



Image quality assessment (IQA) focuses on the perceptual visual quality of images, playing a crucial role in downstream tasks such as image reconstruction, compression, and generation. The rapid advancement of multi-modal large language models (MLLMs) has significantly broadened the scope of IQA, moving toward comprehensive image quality understanding that incorporates content analysis, degradation perception, and comparison reasoning beyond mere numerical scoring. Previous MLLM-based methods typically either generate numerical scores lacking interpretability or heavily rely on supervised fine-tuning (SFT) using large-scale annotated datasets to provide descriptive assessments, limiting their flexibility and applicability. In this paper, we propose Q-Insight, a reinforcement learning-based model built upon group relative policy optimization (GRPO), which demonstrates strong visual reasoning capability for image quality understanding while requiring only a limited amount of rating scores and degradation labels. By jointly optimizing score regression and degradation perception tasks with carefully designed reward functions, our approach effectively exploits their mutual benefits for enhanced performance. Extensive experiments demonstrate that Q-Insight substantially outperforms existing state-of-the-art methods in both score regression and degradation perception tasks, while exhibiting impressive zero-shot generalization to comparison reasoning tasks. Code will be available at https://github.com/lwq20020127/Q-Insight.
SecureGS: Boosting the Security and Fidelity of 3D Gaussian Splatting Steganography
Mar 08, 2025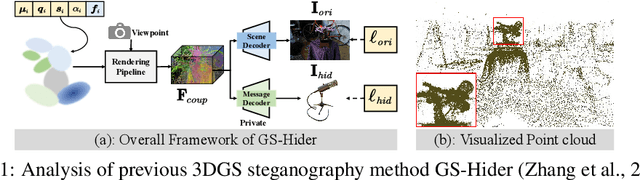
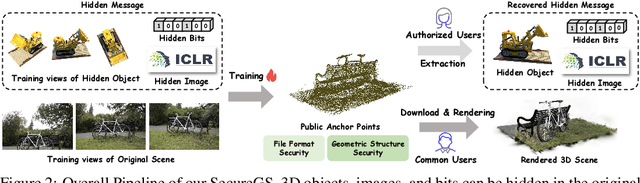
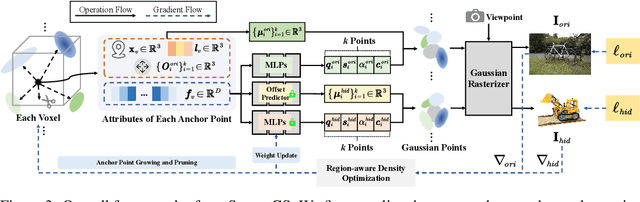

3D Gaussian Splatting (3DGS) has emerged as a premier method for 3D representation due to its real-time rendering and high-quality outputs, underscoring the critical need to protect the privacy of 3D assets. Traditional NeRF steganography methods fail to address the explicit nature of 3DGS since its point cloud files are publicly accessible. Existing GS steganography solutions mitigate some issues but still struggle with reduced rendering fidelity, increased computational demands, and security flaws, especially in the security of the geometric structure of the visualized point cloud. To address these demands, we propose a SecureGS, a secure and efficient 3DGS steganography framework inspired by Scaffold-GS's anchor point design and neural decoding. SecureGS uses a hybrid decoupled Gaussian encryption mechanism to embed offsets, scales, rotations, and RGB attributes of the hidden 3D Gaussian points in anchor point features, retrievable only by authorized users through privacy-preserving neural networks. To further enhance security, we propose a density region-aware anchor growing and pruning strategy that adaptively locates optimal hiding regions without exposing hidden information. Extensive experiments show that SecureGS significantly surpasses existing GS steganography methods in rendering fidelity, speed, and security.
OmniGuard: Hybrid Manipulation Localization via Augmented Versatile Deep Image Watermarking
Dec 02, 2024



With the rapid growth of generative AI and its widespread application in image editing, new risks have emerged regarding the authenticity and integrity of digital content. Existing versatile watermarking approaches suffer from trade-offs between tamper localization precision and visual quality. Constrained by the limited flexibility of previous framework, their localized watermark must remain fixed across all images. Under AIGC-editing, their copyright extraction accuracy is also unsatisfactory. To address these challenges, we propose OmniGuard, a novel augmented versatile watermarking approach that integrates proactive embedding with passive, blind extraction for robust copyright protection and tamper localization. OmniGuard employs a hybrid forensic framework that enables flexible localization watermark selection and introduces a degradation-aware tamper extraction network for precise localization under challenging conditions. Additionally, a lightweight AIGC-editing simulation layer is designed to enhance robustness across global and local editing. Extensive experiments show that OmniGuard achieves superior fidelity, robustness, and flexibility. Compared to the recent state-of-the-art approach EditGuard, our method outperforms it by 4.25dB in PSNR of the container image, 20.7% in F1-Score under noisy conditions, and 14.8% in average bit accuracy.
Understanding Layer Significance in LLM Alignment
Oct 23, 2024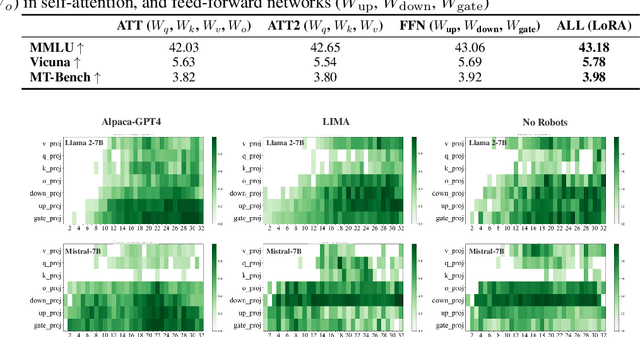
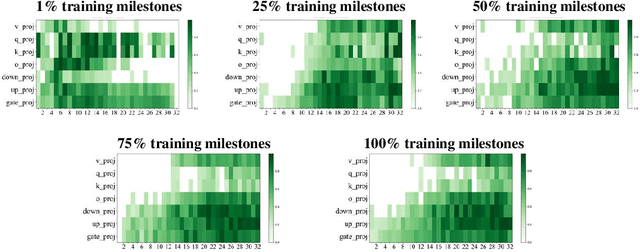


Aligning large language models (LLMs) through fine-tuning is essential for tailoring them to specific applications. Therefore, understanding what LLMs learn during the alignment process is crucial. Recent studies suggest that alignment primarily adjusts a model's presentation style rather than its foundational knowledge, indicating that only certain components of the model are significantly impacted. To delve deeper into LLM alignment, we propose to identify which layers within LLMs are most critical to the alignment process, thereby uncovering how alignment influences model behavior at a granular level. We propose a novel approach to identify the important layers for LLM alignment (ILA). It involves learning a binary mask for each incremental weight matrix in the LoRA algorithm, indicating the significance of each layer. ILA consistently identifies important layers across various alignment datasets, with nearly 90% overlap even with substantial dataset differences, highlighting fundamental patterns in LLM alignment. Experimental results indicate that freezing non-essential layers improves overall model performance, while selectively tuning the most critical layers significantly enhances fine-tuning efficiency with minimal performance loss.