 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Some Noise: Unlocking Language Model Parallel Inference Capability through Noisy Training
Jun 25, 2024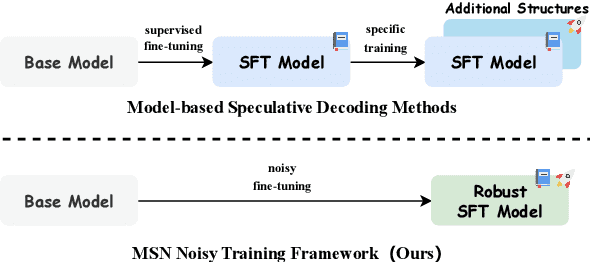
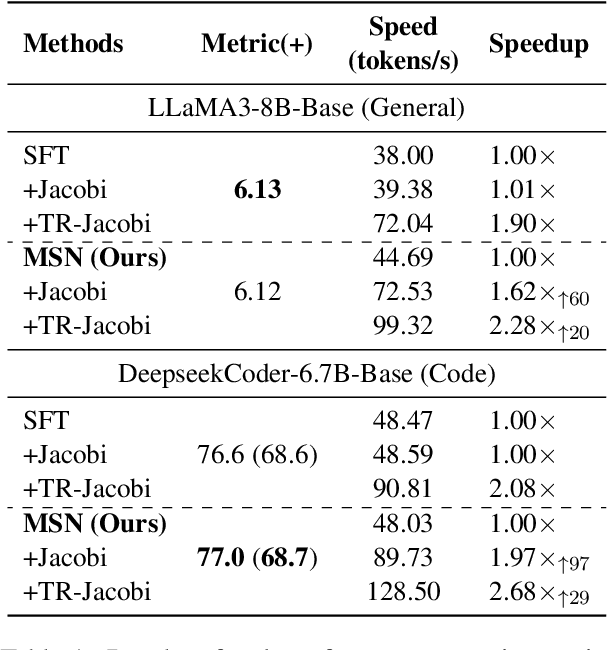
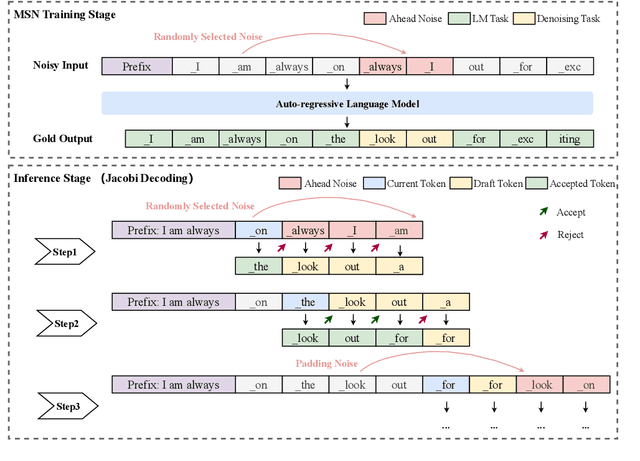
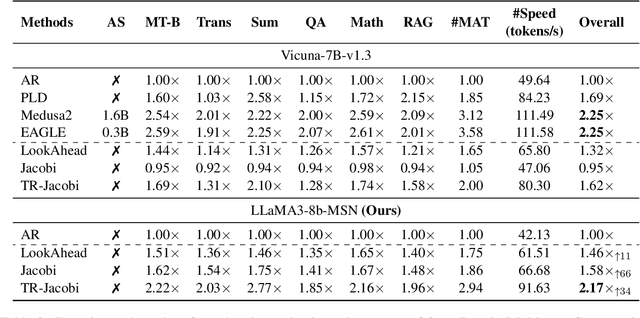
Existing speculative decoding methods typically require additional model structure and training processes to assist the model for draft token generation. This makes the migration of acceleration methods to the new model more costly and more demanding on device memory. To address this problem, we propose the Make Some Noise (MSN) training framework as a replacement for the supervised fine-tuning stage of the large language model. The training method simply introduces some noise at the input for the model to learn the denoising task. It significantly enhances the parallel decoding capability of the model without affecting the original task capability. In addition, we propose a tree-based retrieval-augmented Jacobi (TR-Jacobi) decoding strategy to further improve the inference speed of MSN models. Experiments in both the general and code domains have shown that MSN can improve inference speed by 2.3-2.7x times without compromising model performance. The MSN model also achieves comparable acceleration ratios to the SOTA model with additional model structure on Spec-Bench.
CroPrompt: Cross-task Interactive Prompting for Zero-shot Spoken Language Understanding
Jun 15, 2024Slot filling and intent detection are two highly correlated tasks in spoken language understanding (SLU). Recent SLU research attempts to explore zero-shot prompting techniques in large language models to alleviate the data scarcity problem. Nevertheless, the existing prompting work ignores the cross-task interaction information for SLU, which leads to sub-optimal performance. To solve this problem, we present the pioneering work of Cross-task Interactive Prompting (CroPrompt) for SLU, which enables the model to interactively leverage the information exchange across the correlated tasks in SLU. Additionally, we further introduce a multi-task self-consistency mechanism to mitigate the error propagation caused by the intent information injection. We conduct extensive experiments on the standard SLU benchmark and the results reveal that CroPrompt consistently outperforms the existing prompting approaches. In addition, the multi-task self-consistency mechanism can effectively ease the error propagation issue, thereby enhancing the performance. We hope this work can inspire more research on cross-task prompting for SLU.
Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages
Oct 23, 2023Chain-of-thought (CoT) is capable of eliciting models to explicitly generate reasoning paths, thus promoting reasoning accuracy and attracting increasing attention. Specifically, zero-shot CoT achieves remarkable improvements in a wide range of reasoning tasks by simply instructing the LLM with the prompt "Let's think step by step!". Despite the success of zero-shot CoT, the existing zero-shot prompting techniques remain limited to a single language, making it challenging to generalize to other languages and hindering global development. In this work, we introduce cross-lingual prompting (CLP), aiming to improve zero-shot CoT reasoning across languages. Specifically, CLP consists of two main components: (1) cross-lingual alignment prompting and (2) task-specific solver prompting. The cross-lingual alignment prompting is responsible for aligning representations across different languages, whereas the task-specific solver prompting is used to generate the final chain of thoughts and results for the reasoning task. In addition, we further introduce cross-lingual self-consistent prompting (CLSP) to ensemble different reasoning paths across languages. Our experimental evaluations on several benchmarks demonstrate that CLP and CLSP significantly outperform the existing prompting methods and achieve state-of-the-art performance. We hope this work will inspire further breakthroughs in cross-lingual CoT.
HIT-SCIR at MMNLU-22: Consistency Regularization for Multilingual Spoken Language Understanding
Jan 05, 2023Multilingual spoken language understanding (SLU) consists of two sub-tasks, namely intent detection and slot filling. To improve the performance of these two sub-tasks, we propose to use consistency regularization based on a hybrid data augmentation strategy. The consistency regularization enforces the predicted distributions for an example and its semantically equivalent augmentation to be consistent. We conduct experiments on the MASSIVE dataset under both full-dataset and zero-shot settings. Experimental results demonstrate that our proposed method improves the performance on both intent detection and slot filling tasks. Our system\footnote{The code will be available at \url{https://github.com/bozheng-hit/MMNLU-22-HIT-SCIR}.} ranked 1st in the MMNLU-22 competition under the full-dataset setting.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
GL-GIN: Fast and Accurate Non-Autoregressive Model for Joint Multiple Intent Detection and Slot Filling
Jun 03, 2021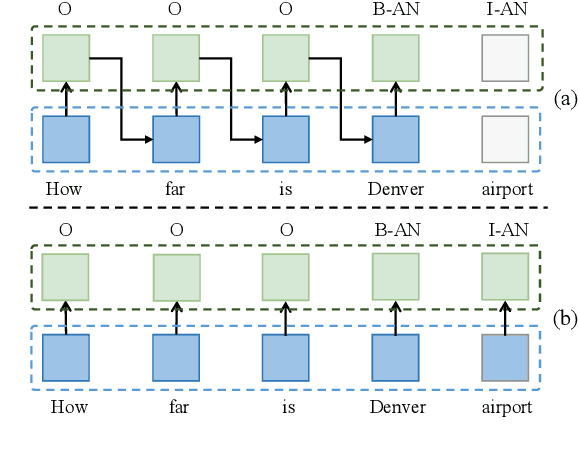
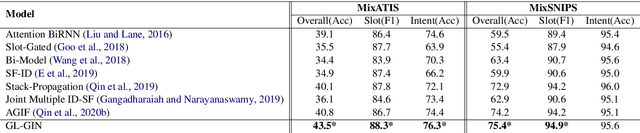
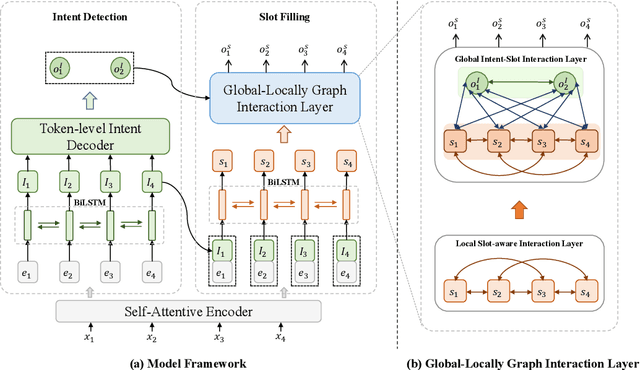

Multi-intent SLU can handle multiple intents in an utterance, which has attracted increasing attention. However, the state-of-the-art joint models heavily rely on autoregressive approaches, resulting in two issues: slow inference speed and information leakage. In this paper, we explore a non-autoregressive model for joint multiple intent detection and slot filling, achieving more fast and accurate. Specifically, we propose a Global-Locally Graph Interaction Network (GL-GIN) where a local slot-aware graph interaction layer is proposed to model slot dependency for alleviating uncoordinated slots problem while a global intent-slot graph interaction layer is introduced to model the interaction between multiple intents and all slots in the utterance. Experimental results on two public datasets show that our framework achieves state-of-the-art performance while being 11.5 times faster.