 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond NL2Code: A Structured Survey of Multimodal Code Intelligence
Jun 16, 2026While Large Language Models (LLMs) have substantially advanced text-to-code synthesis, many real programming tasks specify intent through visual artifacts such as screenshots, charts, vector drawings, videos, and interactive states. These tasks require models to connect visual perception to executable programs, because correctness depends not only on syntax but also on layout, data semantics, interaction behavior, and domain-specific constraints that apply after execution. This survey examines Multimodal Code Intelligence, covering systems that generate, edit, refine, or reason with code under visually grounded inputs and outputs. We first formulate the field by the role that code plays in each task, distinguishing code as a rendered artifact, an editable symbolic structure, a scientific representation, an intermediate reasoning trace, or an executable policy or tool interface. We then organize benchmarks and methods into four domains: Graphical User Interface, Scientific Visualization, Structured Graphics, and Frontier Tasks and Frameworks. This taxonomy connects mature artifact-generation problems to emerging agentic and unified settings and allows us to compare how different tasks treat evidence of correctness. Looking ahead, we argue that future research may benefit from four verification-centered directions. Multi-signal validation can combine complementary evidence of correctness, multi-state verification can test behavior across execution trajectories, cross-task transfer testing can probe reusable visual-code skills, and verifiable agent traces can reveal whether agent actions are grounded in visual evidence. Together, these directions may move this field from single-output imitation toward evidence-grounded executable systems. An ongoing project and resources are available on \href{https://github.com/xjywhu/Awesome-Multimodal-LLM-for-Code}{GitHub}.
CVE-Factory: Scaling Expert-Level Agentic Tasks for Code Security Vulnerability
Feb 03, 2026Evaluating and improving the security capabilities of code agents requires high-quality, executable vulnerability tasks. However, existing works rely on costly, unscalable manual reproduction and suffer from outdated data distributions. To address these, we present CVE-Factory, the first multi-agent framework to achieve expert-level quality in automatically transforming sparse CVE metadata into fully executable agentic tasks. Cross-validation against human expert reproductions shows that CVE-Factory achieves 95\% solution correctness and 96\% environment fidelity, confirming its expert-level quality. It is also evaluated on the latest realistic vulnerabilities and achieves a 66.2\% verified success. This automation enables two downstream contributions. First, we construct LiveCVEBench, a continuously updated benchmark of 190 tasks spanning 14 languages and 153 repositories that captures emerging threats including AI-tooling vulnerabilities. Second, we synthesize over 1,000 executable training environments, the first large-scale scaling of agentic tasks in code security. Fine-tuned Qwen3-32B improves from 5.3\% to 35.8\% on LiveCVEBench, surpassing Claude 4.5 Sonnet, with gains generalizing to Terminal Bench (12.5\% to 31.3\%). We open-source CVE-Factory, LiveCVEBench, Abacus-cve (fine-tuned model), training dataset, and leaderboard. All resources are available at https://github.com/livecvebench/CVE-Factory .
Success is in the Details: Evaluate and Enhance Details Sensitivity of Code LLMs through Counterfactuals
May 20, 2025Code Sensitivity refers to the ability of Code LLMs to recognize and respond to details changes in problem descriptions. While current code benchmarks and instruction data focus on difficulty and diversity, sensitivity is overlooked. We first introduce the CTF-Code benchmark, constructed using counterfactual perturbations, minimizing input changes while maximizing output changes. The evaluation shows that many LLMs have a more than 10\% performance drop compared to the original problems. To fully utilize sensitivity, CTF-Instruct, an incremental instruction fine-tuning framework, extends on existing data and uses a selection mechanism to meet the three dimensions of difficulty, diversity, and sensitivity. Experiments show that LLMs fine-tuned with CTF-Instruct data achieve over a 2\% improvement on CTF-Code, and more than a 10\% performance boost on LiveCodeBench, validating the feasibility of enhancing LLMs' sensitivity to improve performance.
ChartEdit: How Far Are MLLMs From Automating Chart Analysis? Evaluating MLLMs' Capability via Chart Editing
May 17, 2025Although multimodal large language models (MLLMs) show promise in generating chart rendering code, chart editing presents a greater challenge. This difficulty stems from its nature as a labor-intensive task for humans that also demands MLLMs to integrate chart understanding, complex reasoning, and precise intent interpretation. While many MLLMs claim such editing capabilities, current assessments typically rely on limited case studies rather than robust evaluation methodologies, highlighting the urgent need for a comprehensive evaluation framework. In this work, we propose ChartEdit, a new high-quality benchmark designed for chart editing tasks. This benchmark comprises $1,405$ diverse editing instructions applied to $233$ real-world charts, with each instruction-chart instance having been manually annotated and validated for accuracy. Utilizing ChartEdit, we evaluate the performance of 10 mainstream MLLMs across two types of experiments, assessing them at both the code and chart levels. The results suggest that large-scale models can generate code to produce images that partially match the reference images. However, their ability to generate accurate edits according to the instructions remains limited. The state-of-the-art (SOTA) model achieves a score of only $59.96$, highlighting significant challenges in precise modification. In contrast, small-scale models, including chart-domain models, struggle both with following editing instructions and generating overall chart images, underscoring the need for further development in this area. Code is available at https://github.com/xxlllz/ChartEdit.
Is Compression Really Linear with Code Intelligence?
May 16, 2025



Understanding the relationship between data compression and the capabilities of Large Language Models (LLMs) is crucial, especially in specialized domains like code intelligence. Prior work posited a linear relationship between compression and general intelligence. However, it overlooked the multifaceted nature of code that encompasses diverse programming languages and tasks, and struggled with fair evaluation of modern Code LLMs. We address this by evaluating a diverse array of open-source Code LLMs on comprehensive multi-language, multi-task code benchmarks. To address the challenge of efficient and fair evaluation of pre-trained LLMs' code intelligence, we introduce \textit{Format Annealing}, a lightweight, transparent training methodology designed to assess the intrinsic capabilities of these pre-trained models equitably. Compression efficacy, measured as bits-per-character (BPC), is determined using a novel, large-scale, and previously unseen code validation set derived from GitHub. Our empirical results reveal a fundamental logarithmic relationship between measured code intelligence and BPC. This finding refines prior hypotheses of linearity, which we suggest are likely observations of the logarithmic curve's tail under specific, limited conditions. Our work provides a more nuanced understanding of compression's role in developing code intelligence and contributes a robust evaluation framework in the code domain.
ChartCoder: Advancing Multimodal Large Language Model for Chart-to-Code Generation
Jan 11, 2025



Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in chart understanding tasks. However, interpreting charts with textual descriptions often leads to information loss, as it fails to fully capture the dense information embedded in charts. In contrast, parsing charts into code provides lossless representations that can effectively contain all critical details. Although existing open-source MLLMs have achieved success in chart understanding tasks, they still face two major challenges when applied to chart-to-code tasks.: (1) Low executability and poor restoration of chart details in the generated code and (2) Lack of large-scale and diverse training data. To address these challenges, we propose \textbf{ChartCoder}, the first dedicated chart-to-code MLLM, which leverages Code LLMs as the language backbone to enhance the executability of the generated code. Furthermore, we introduce \textbf{Chart2Code-160k}, the first large-scale and diverse dataset for chart-to-code generation, and propose the \textbf{Snippet-of-Thought (SoT)} method, which transforms direct chart-to-code generation data into step-by-step generation. Experiments demonstrate that ChartCoder, with only 7B parameters, surpasses existing open-source MLLMs on chart-to-code benchmarks, achieving superior chart restoration and code excitability. Our code will be available at https://github.com/thunlp/ChartCoder.
Turning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling
Aug 16, 2024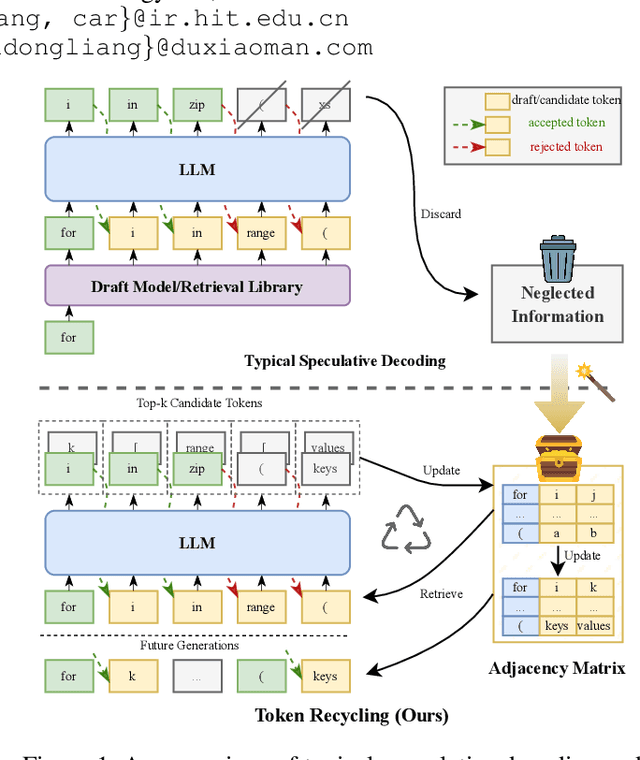

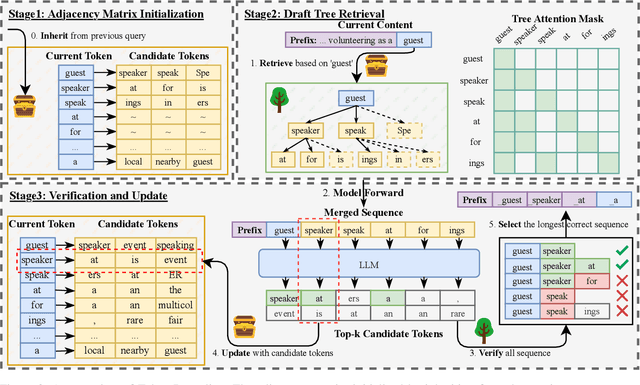
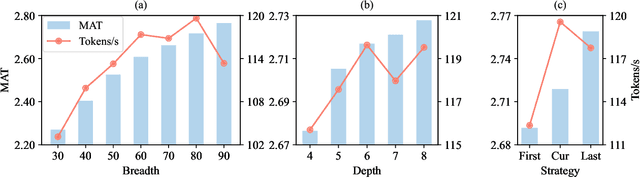
The rapid growth in the parameters of large language models (LLMs) has made inference latency a fundamental bottleneck, limiting broader application of LLMs. Speculative decoding represents a lossless approach to accelerate inference through a guess-and-verify paradigm, leveraging the parallel capabilities of modern hardware. Some speculative decoding methods rely on additional structures to guess draft tokens, such as small models or parameter-efficient architectures, which need extra training before use. Alternatively, retrieval-based train-free techniques build libraries from pre-existing corpora or by n-gram generation. However, they face challenges like large storage requirements, time-consuming retrieval, and limited adaptability. Observing that candidate tokens generated during the decoding process are likely to reoccur in future sequences, we propose Token Recycling. This approach stores candidate tokens in an adjacency matrix and employs a breadth-first search (BFS)-like algorithm on the matrix to construct a draft tree. The tree is then validated through tree attention. New candidate tokens from the decoding process are then used to update the matrix. Token Recycling requires \textless2MB of additional storage and achieves approximately 2x speedup across all sizes of LLMs. It significantly outperforms existing train-free methods by 30\% and even a training method by 25\%. It can be directly applied to any existing LLMs and tasks without the need for adaptation.
Make Some Noise: Unlocking Language Model Parallel Inference Capability through Noisy Training
Jun 25, 2024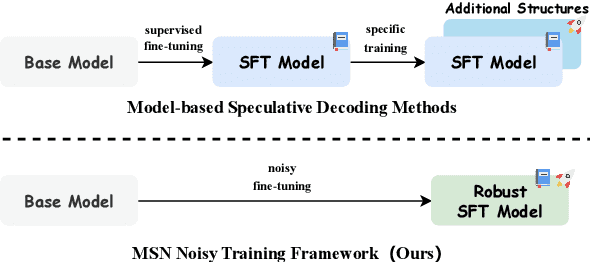
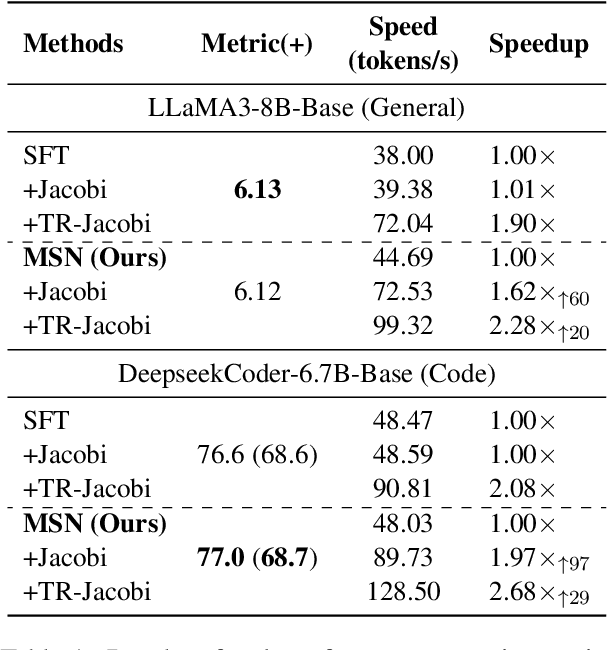
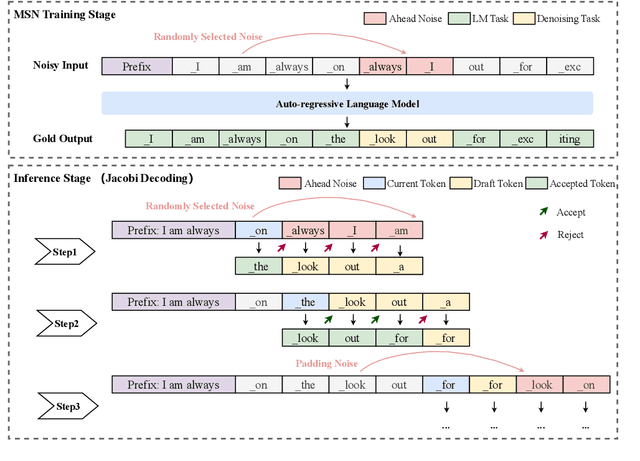
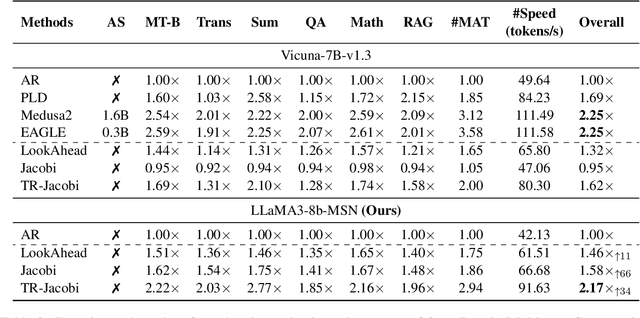
Existing speculative decoding methods typically require additional model structure and training processes to assist the model for draft token generation. This makes the migration of acceleration methods to the new model more costly and more demanding on device memory. To address this problem, we propose the Make Some Noise (MSN) training framework as a replacement for the supervised fine-tuning stage of the large language model. The training method simply introduces some noise at the input for the model to learn the denoising task. It significantly enhances the parallel decoding capability of the model without affecting the original task capability. In addition, we propose a tree-based retrieval-augmented Jacobi (TR-Jacobi) decoding strategy to further improve the inference speed of MSN models. Experiments in both the general and code domains have shown that MSN can improve inference speed by 2.3-2.7x times without compromising model performance. The MSN model also achieves comparable acceleration ratios to the SOTA model with additional model structure on Spec-Bench.
Semi-Instruct: Bridging Natural-Instruct and Self-Instruct for Code Large Language Models
Mar 01, 2024


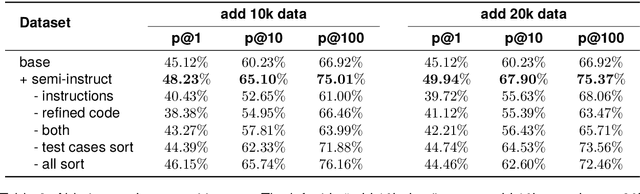
Instruction tuning plays a pivotal role in Code Large Language Models (Code LLMs) for the task of program synthesis. Presently, two dominant paradigms for collecting tuning data are natural-instruct (human-written) and self-instruct (automatically generated). Natural-instruct includes diverse and correct codes but lacks instruction-code pairs, and exists improper code formats like nested single-line codes. In contrast, self-instruct automatically generates proper paired data. However, it suffers from low diversity due to generating duplicates and cannot ensure the correctness of codes. To bridge the both paradigms, we propose \textbf{Semi-Instruct}. It first converts diverse but improper codes from natural-instruct into proper instruction-code pairs through a method similar to self-instruct. To verify the correctness of generated codes, we design a novel way to construct test cases by generating cases' inputs and executing correct codes from natural-instruct to get outputs. Finally, diverse and correct instruction-code pairs are retained for instruction tuning. Experiments show that semi-instruct is significantly better than natural-instruct and self-instruct. Furthermore, the performance steadily improves as data scale increases.
MultiPoT: Multilingual Program of Thoughts Harnesses Multiple Programming Languages
Feb 16, 2024



Program of Thoughts (PoT) is an approach characterized by its executable intermediate steps, which ensure the accuracy of the numerical calculations in the reasoning process. Currently, PoT primarily uses Python. However, relying solely on a single language may result in suboptimal solutions and overlook the potential benefits of other programming languages. In this paper, we conduct comprehensive experiments on the programming languages used in PoT and find that no single language consistently delivers optimal performance across all tasks and models. The effectiveness of each language varies depending on the specific scenarios. Inspired by this, we propose a task and model agnostic approach called MultiPoT, which harnesses strength and diversity from various languages. Experimental results reveal that it significantly outperforms Python Self-Consistency. Furthermore, it achieves comparable or superior performance compared to the best monolingual PoT in almost all tasks across all models. In particular, MultiPoT achieves more than 4.6\% improvement on average on both Starcoder and ChatGPT (gpt-3.5-turbo).