 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Instruct: Bridging Natural-Instruct and Self-Instruct for Code Large Language Models
Paper and Code
Mar 01, 2024


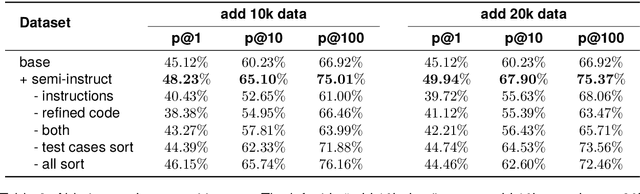
Instruction tuning plays a pivotal role in Code Large Language Models (Code LLMs) for the task of program synthesis. Presently, two dominant paradigms for collecting tuning data are natural-instruct (human-written) and self-instruct (automatically generated). Natural-instruct includes diverse and correct codes but lacks instruction-code pairs, and exists improper code formats like nested single-line codes. In contrast, self-instruct automatically generates proper paired data. However, it suffers from low diversity due to generating duplicates and cannot ensure the correctness of codes. To bridge the both paradigms, we propose \textbf{Semi-Instruct}. It first converts diverse but improper codes from natural-instruct into proper instruction-code pairs through a method similar to self-instruct. To verify the correctness of generated codes, we design a novel way to construct test cases by generating cases' inputs and executing correct codes from natural-instruct to get outputs. Finally, diverse and correct instruction-code pairs are retained for instruction tuning. Experiments show that semi-instruct is significantly better than natural-instruct and self-instruct. Furthermore, the performance steadily improves as data scale increases.