 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoAgentBench: A Dynamic Execution Benchmark for Tool-Augmented Agents in Spatial Analysis
Apr 15, 2026The integration of Large Language Models (LLMs) into Geographic Information Systems (GIS) marks a paradigm shift toward autonomous spatial analysis. However, evaluating these LLM-based agents remains challenging due to the complex, multi-step nature of geospatial workflows. Existing benchmarks primarily rely on static text or code matching, neglecting dynamic runtime feedback and the multimodal nature of spatial outputs. To address this gap, we introduce GeoAgentBench (GABench), a dynamic and interactive evaluation benchmark tailored for tool-augmented GIS agents. GABench provides a realistic execution sandbox integrating 117 atomic GIS tools, encompassing 53 typical spatial analysis tasks across 6 core GIS domains. Recognizing that precise parameter configuration is the primary determinant of execution success in dynamic GIS environments, we designed the Parameter Execution Accuracy (PEA) metric, which utilizes a "Last-Attempt Alignment" strategy to quantify the fidelity of implicit parameter inference. Complementing this, a Vision-Language Model (VLM) based verification is proposed to assess data-spatial accuracy and cartographic style adherence. Furthermore, to address the frequent task failures caused by parameter misalignments and runtime anomalies, we developed a novel agent architecture, Plan-and-React, that mimics expert cognitive workflows by decoupling global orchestration from step-wise reactive execution. Extensive experiments with seven representative LLMs demonstrate that the Plan-and-React paradigm significantly outperforms traditional frameworks, achieving the optimal balance between logical rigor and execution robustness, particularly in multi-step reasoning and error recovery. Our findings highlight current capability boundaries and establish a robust standard for assessing and advancing the next generation of autonomous GeoAI.
Success is in the Details: Evaluate and Enhance Details Sensitivity of Code LLMs through Counterfactuals
May 20, 2025Code Sensitivity refers to the ability of Code LLMs to recognize and respond to details changes in problem descriptions. While current code benchmarks and instruction data focus on difficulty and diversity, sensitivity is overlooked. We first introduce the CTF-Code benchmark, constructed using counterfactual perturbations, minimizing input changes while maximizing output changes. The evaluation shows that many LLMs have a more than 10\% performance drop compared to the original problems. To fully utilize sensitivity, CTF-Instruct, an incremental instruction fine-tuning framework, extends on existing data and uses a selection mechanism to meet the three dimensions of difficulty, diversity, and sensitivity. Experiments show that LLMs fine-tuned with CTF-Instruct data achieve over a 2\% improvement on CTF-Code, and more than a 10\% performance boost on LiveCodeBench, validating the feasibility of enhancing LLMs' sensitivity to improve performance.
Turning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling
Aug 16, 2024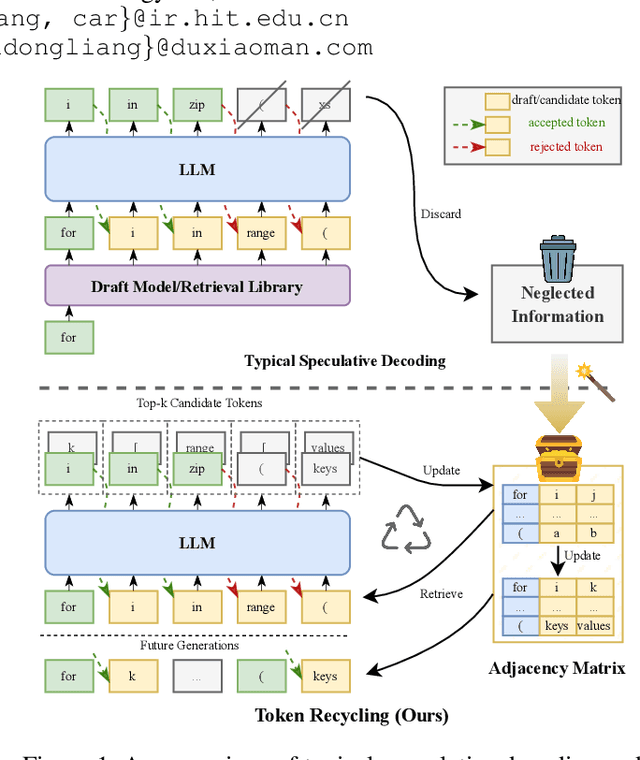

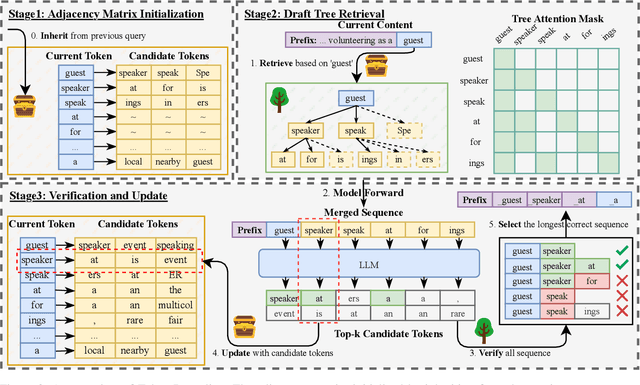
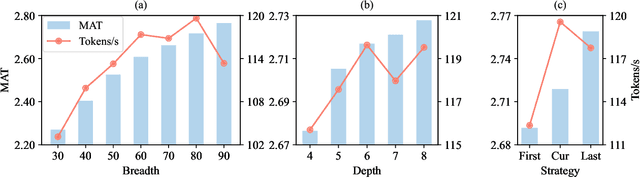
The rapid growth in the parameters of large language models (LLMs) has made inference latency a fundamental bottleneck, limiting broader application of LLMs. Speculative decoding represents a lossless approach to accelerate inference through a guess-and-verify paradigm, leveraging the parallel capabilities of modern hardware. Some speculative decoding methods rely on additional structures to guess draft tokens, such as small models or parameter-efficient architectures, which need extra training before use. Alternatively, retrieval-based train-free techniques build libraries from pre-existing corpora or by n-gram generation. However, they face challenges like large storage requirements, time-consuming retrieval, and limited adaptability. Observing that candidate tokens generated during the decoding process are likely to reoccur in future sequences, we propose Token Recycling. This approach stores candidate tokens in an adjacency matrix and employs a breadth-first search (BFS)-like algorithm on the matrix to construct a draft tree. The tree is then validated through tree attention. New candidate tokens from the decoding process are then used to update the matrix. Token Recycling requires \textless2MB of additional storage and achieves approximately 2x speedup across all sizes of LLMs. It significantly outperforms existing train-free methods by 30\% and even a training method by 25\%. It can be directly applied to any existing LLMs and tasks without the need for adaptation.
Causal Customer Churn Analysis with Low-rank Tensor Block Hazard Model
May 18, 2024



This study introduces an innovative method for analyzing the impact of various interventions on customer churn, using the potential outcomes framework. We present a new causal model, the tensorized latent factor block hazard model, which incorporates tensor completion methods for a principled causal analysis of customer churn. A crucial element of our approach is the formulation of a 1-bit tensor completion for the parameter tensor. This captures hidden customer characteristics and temporal elements from churn records, effectively addressing the binary nature of churn data and its time-monotonic trends. Our model also uniquely categorizes interventions by their similar impacts, enhancing the precision and practicality of implementing customer retention strategies. For computational efficiency, we apply a projected gradient descent algorithm combined with spectral clustering. We lay down the theoretical groundwork for our model, including its non-asymptotic properties. The efficacy and superiority of our model are further validated through comprehensive experiments on both simulated and real-world applications.
Semi-Instruct: Bridging Natural-Instruct and Self-Instruct for Code Large Language Models
Mar 01, 2024


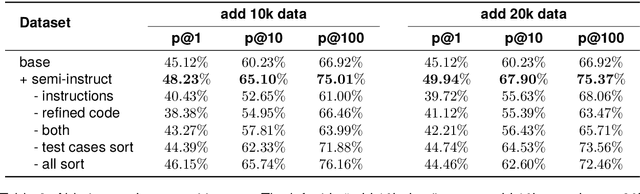
Instruction tuning plays a pivotal role in Code Large Language Models (Code LLMs) for the task of program synthesis. Presently, two dominant paradigms for collecting tuning data are natural-instruct (human-written) and self-instruct (automatically generated). Natural-instruct includes diverse and correct codes but lacks instruction-code pairs, and exists improper code formats like nested single-line codes. In contrast, self-instruct automatically generates proper paired data. However, it suffers from low diversity due to generating duplicates and cannot ensure the correctness of codes. To bridge the both paradigms, we propose \textbf{Semi-Instruct}. It first converts diverse but improper codes from natural-instruct into proper instruction-code pairs through a method similar to self-instruct. To verify the correctness of generated codes, we design a novel way to construct test cases by generating cases' inputs and executing correct codes from natural-instruct to get outputs. Finally, diverse and correct instruction-code pairs are retained for instruction tuning. Experiments show that semi-instruct is significantly better than natural-instruct and self-instruct. Furthermore, the performance steadily improves as data scale increases.
MultiPoT: Multilingual Program of Thoughts Harnesses Multiple Programming Languages
Feb 16, 2024



Program of Thoughts (PoT) is an approach characterized by its executable intermediate steps, which ensure the accuracy of the numerical calculations in the reasoning process. Currently, PoT primarily uses Python. However, relying solely on a single language may result in suboptimal solutions and overlook the potential benefits of other programming languages. In this paper, we conduct comprehensive experiments on the programming languages used in PoT and find that no single language consistently delivers optimal performance across all tasks and models. The effectiveness of each language varies depending on the specific scenarios. Inspired by this, we propose a task and model agnostic approach called MultiPoT, which harnesses strength and diversity from various languages. Experimental results reveal that it significantly outperforms Python Self-Consistency. Furthermore, it achieves comparable or superior performance compared to the best monolingual PoT in almost all tasks across all models. In particular, MultiPoT achieves more than 4.6\% improvement on average on both Starcoder and ChatGPT (gpt-3.5-turbo).
Real-RawVSR: Real-World Raw Video Super-Resolution with a Benchmark Dataset
Sep 26, 2022
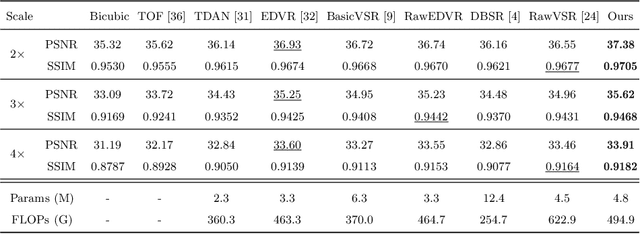

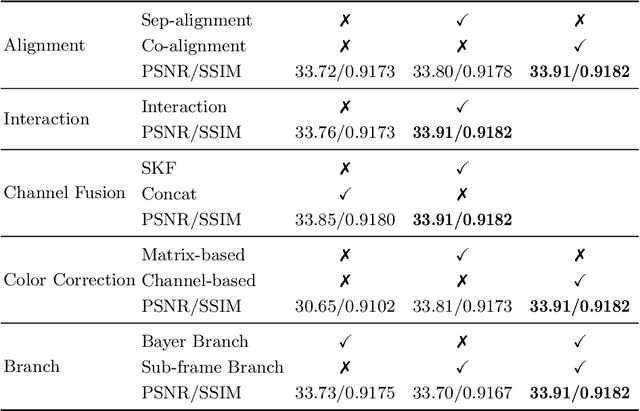
In recent years, real image super-resolution (SR) has achieved promising results due to the development of SR datasets and corresponding real SR methods. In contrast, the field of real video SR is lagging behind, especially for real raw videos. Considering the superiority of raw image SR over sRGB image SR, we construct a real-world raw video SR (Real-RawVSR) dataset and propose a corresponding SR method. We utilize two DSLR cameras and a beam-splitter to simultaneously capture low-resolution (LR) and high-resolution (HR) raw videos with 2x, 3x, and 4x magnifications. There are 450 video pairs in our dataset, with scenes varying from indoor to outdoor, and motions including camera and object movements. To our knowledge, this is the first real-world raw VSR dataset. Since the raw video is characterized by the Bayer pattern, we propose a two-branch network, which deals with both the packed RGGB sequence and the original Bayer pattern sequence, and the two branches are complementary to each other. After going through the proposed co-alignment, interaction, fusion, and reconstruction modules, we generate the corresponding HR sRGB sequence. Experimental results demonstrate that the proposed method outperforms benchmark real and synthetic video SR methods with either raw or sRGB inputs. Our code and dataset are available at https://github.com/zmzhang1998/Real-RawVSR.
Robust physics discovery via supervised and unsupervised pattern recognition using the Euler characteristic
Oct 15, 2021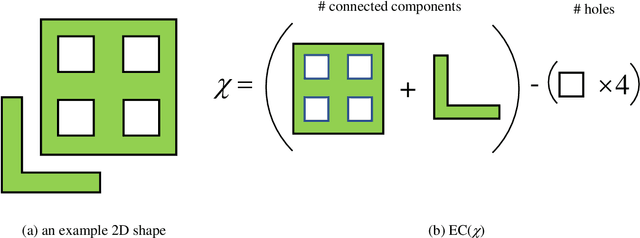

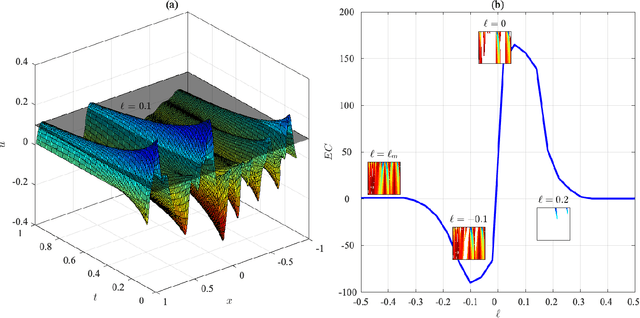
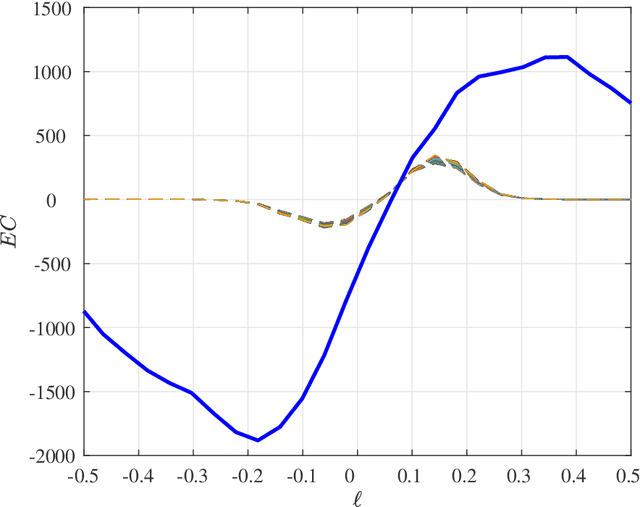
Machine learning approaches have been widely used for discovering the underlying physics of dynamical systems from measured data. Existing approaches, however, still lack robustness, especially when the measured data contain a large level of noise. The lack of robustness is mainly attributed to the insufficient representativeness of used features. As a result, the intrinsic mechanism governing the observed system cannot be accurately identified. In this study, we use an efficient topological descriptor for complex data, i.e., the Euler characteristics (ECs), as features to characterize the spatiotemporal data collected from dynamical systems and discover the underlying physics. Unsupervised manifold learning and supervised classification results show that EC can be used to efficiently distinguish systems with different while similar governing models. We also demonstrate that the machine learning approaches using EC can improve the confidence level of sparse regression methods of physics discovery.
Parsimony-Enhanced Sparse Bayesian Learning for Robust Discovery of Partial Differential Equations
Jul 08, 2021
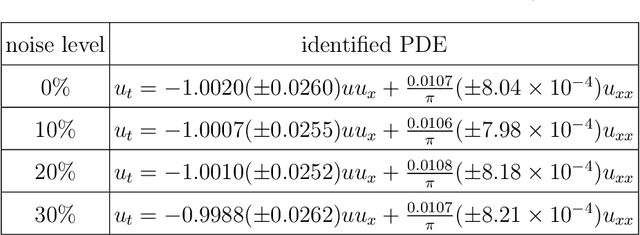
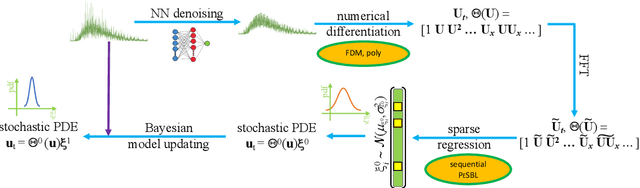
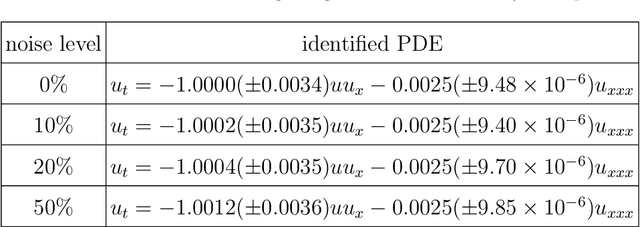
Robust physics discovery is of great interest for many scientific and engineering fields. Inspired by the principle that a representative model is the one simplest possible, a new model selection criteria considering both model's Parsimony and Sparsity is proposed. A Parsimony Enhanced Sparse Bayesian Learning (PeSBL) method is developed for discovering the governing Partial Differential Equations (PDEs) of nonlinear dynamical systems. Compared with the conventional Sparse Bayesian Learning (SBL) method, the PeSBL method promotes parsimony of the learned model in addition to its sparsity. In this method, the parsimony of model terms is evaluated using their locations in the prescribed candidate library, for the first time, considering the increased complexity with the power of polynomials and the order of spatial derivatives. Subsequently, the model parameters are updated through Bayesian inference with the raw data. This procedure aims to reduce the error associated with the possible loss of information in data preprocessing and numerical differentiation prior to sparse regression. Results of numerical case studies indicate that the governing PDEs of many canonical dynamical systems can be correctly identified using the proposed PeSBL method from highly noisy data (up to 50% in the current study). Next, the proposed methodology is extended for stochastic PDE learning where all parameters and modeling error are considered as random variables. Hierarchical Bayesian Inference (HBI) is integrated with the proposed framework for stochastic PDE learning from a population of observations. Finally, the proposed PeSBL is demonstrated for system response prediction with uncertainties and anomaly diagnosis. Codes of all demonstrated examples in this study are available on the website: https://github.com/ymlasu.
Condition Assessment of Stay Cables through Enhanced Time Series Classification Using a Deep Learning Approach
Jan 11, 2021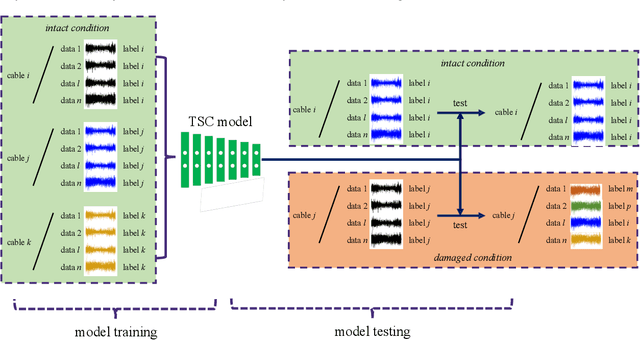

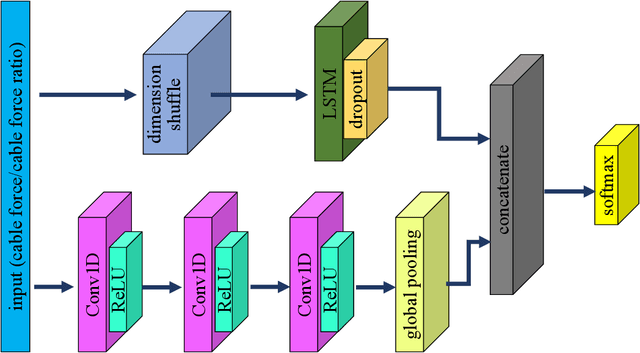

This study proposes a data-driven method that detects cable damage from measured cable forces by recognizing biased patterns from the intact conditions. The proposed method solves the pattern recognition problem for cable damage detection through time series classification (TSC) in deep learning, considering that the cable's behavior can be implicitly represented by the measured cable force series. A deep learning model, long short term memory fully convolutional network (LSTM-FCN), is leveraged by assigning appropriate inputs and representative class labels for the TSC problem, First, a TSC classifier is trained and validated using the data collected under intact conditions of stay cables, setting the segmented data series as input and the cable (or cable pair) ID as class labels. Subsequently, the classifier is tested using the data collected under possible damaged conditions. Finally, the cable or cable pair corresponding to the least classification accuracy is recommended as the most probable damaged cable or cable pair. The proposed method was tested on an in-service cable-stayed bridge with damaged stay cables. Two scenarios in the proposed TSC scheme were investigated: 1) raw time series of cable forces were fed into the classifiers; and 2) cable force ratios were inputted in the classifiers considering the possible variation of force distribution between cable pairs due to cable damage. Combining the results of TSC testing in these two scenarios, the cable with rupture was correctly identified. This study proposes a data-driven methodology for cable damage detection that requires the least data preprocessing and feature engineering, which enables fast and convenient early detection in real applications.