 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF2HDR: Two-Stage HDR Video Reconstruction via Flow Adapter and Physical Motion Modeling
Mar 18, 2026Reconstructing High Dynamic Range (HDR) videos from sequences of alternating-exposure Low Dynamic Range (LDR) frames remains highly challenging, especially under dynamic scenes where cross-exposure inconsistencies and complex motion make inter-frame alignment difficult, leading to ghosting and detail loss. Existing methods often suffer from inaccurate alignment, suboptimal feature aggregation, and degraded reconstruction quality in motion-dominated regions. To address these challenges, we propose F2HDR, a two-stage HDR video reconstruction framework that robustly perceives inter-frame motion and restores fine details in complex dynamic scenarios. The proposed framework integrates a flow adapter that adapts generic optical flow for robust cross-exposure alignment, a physical motion modeling to identify salient motion regions, and a motion-aware refinement network that aggregates complementary information while removing ghosting and noise. Extensive experiments demonstrate that F2HDR achieves state-of-the-art performance on real-world HDR video benchmarks, producing ghost-free and high-fidelity results under large motion and exposure variations.
SpiralDiff: Spiral Diffusion with LoRA for RGB-to-RAW Conversion Across Cameras
Mar 16, 2026RAW images preserve superior fidelity and rich scene information compared to RGB, making them essential for tasks in challenging imaging conditions. To alleviate the high cost of data collection, recent RGB-to-RAW conversion methods aim to synthesize RAW images from RGB. However, they overlook two key challenges: (i) the reconstruction difficulty varies with pixel intensity, and (ii) multi-camera conversion requires camera-specific adaptation. To address these issues, we propose SpiralDiff, a diffusion-based framework tailored for RGB-to-RAW conversion with a signal-dependent noise weighting strategy that adapts reconstruction fidelity across intensity levels. In addition, we introduce CamLoRA, a camera-aware lightweight adaptation module that enables a unified model to adapt to different camera-specific ISP characteristics. Extensive experiments on four benchmark datasets demonstrate the superiority of SpiralDiff in RGB-to-RAW conversion quality and its downstream benefits in RAW-based object detection. Our code and model are available at https://github.com/Chuancy-TJU/SpiralDiff.
$\text{F}^2\text{HDR}$: Two-Stage HDR Video Reconstruction via Flow Adapter and Physical Motion Modeling
Mar 16, 2026Reconstructing High Dynamic Range (HDR) videos from sequences of alternating-exposure Low Dynamic Range (LDR) frames remains highly challenging, especially under dynamic scenes where cross-exposure inconsistencies and complex motion make inter-frame alignment difficult, leading to ghosting and detail loss. Existing methods often suffer from inaccurate alignment, suboptimal feature aggregation, and degraded reconstruction quality in motion-dominated regions. To address these challenges, we propose $\text{F}^2\text{HDR}$, a two-stage HDR video reconstruction framework that robustly perceives inter-frame motion and restores fine details in complex dynamic scenarios. The proposed framework integrates a flow adapter that adapts generic optical flow for robust cross-exposure alignment, a physical motion modeling to identify salient motion regions, and a motion-aware refinement network that aggregates complementary information while removing ghosting and noise. Extensive experiments demonstrate that $\text{F}^2\text{HDR}$ achieves state-of-the-art performance on real-world HDR video benchmarks, producing ghost-free and high-fidelity results under large motion and exposure variations.
OAHuman: Occlusion-Aware 3D Human Reconstruction from Monocular Images
Mar 15, 2026Monocular 3D human reconstruction in real-world scenarios remains highly challenging due to frequent occlusions from surrounding objects, people, or image truncation. Such occlusions lead to missing geometry and unreliable appearance cues, severely degrading the completeness and realism of reconstructed human models. Although recent neural implicit methods achieve impressive results on clean inputs, they struggle under occlusion due to entangled modeling of shape and texture. In this paper, we propose OAHuman, an occlusion-aware framework that explicitly decouples geometry reconstruction and texture synthesis for robust 3D human modeling from a single RGB image. The core innovation lies in the decoupling-perception paradigm, which addresses the fundamental issue of geometry-texture cross-contamination in occluded regions. Our framework ensures that geometry reconstruction is perceptually reinforced even in occluded areas, isolating it from texture interference. In parallel, texture synthesis is learned exclusively from visible regions, preventing texture errors from being transferred to the occluded areas. This decoupling approach enables OAHuman to achieve robust and high-fidelity reconstruction under occlusion, which has been a long-standing challenge in the field. Extensive experiments on occlusion-rich benchmarks demonstrate that OAHuman achieves superior performance in terms of structural completeness, surface detail, and texture realism, significantly improving monocular 3D human reconstruction under occlusion conditions.
Active Inference for Micro-Gesture Recognition: EFE-Guided Temporal Sampling and Adaptive Learning
Mar 08, 2026Micro-gestures are subtle and transient movements triggered by unconscious neural and emotional activities, holding great potential for human-computer interaction and clinical monitoring. However, their low amplitude, short duration, and strong inter-subject variability make existing deep models prone to degradation under low-sample, noisy, and cross-subject conditions. This paper presents an active inference-based framework for micro-gesture recognition, featuring Expected Free Energy (EFE)-guided temporal sampling and uncertainty-aware adaptive learning. The model actively selects the most discriminative temporal segments under EFE guidance, enabling dynamic observation and information gain maximization. Meanwhile, sample weighting driven by predictive uncertainty mitigates the effects of label noise and distribution shift. Experiments on the SMG dataset demonstrate the effectiveness of the proposed method, achieving consistent improvements across multiple mainstream backbones. Ablation studies confirm that both the EFE-guided observation and the adaptive learning mechanism are crucial to the performance gains. This work offers an interpretable and scalable paradigm for temporal behavior modeling under low-resource and noisy conditions, with broad applicability to wearable sensing, HCI, and clinical emotion monitoring.
Distribution-Specific Learning for Joint Salient and Camouflaged Object Detection
Aug 08, 2025Salient object detection (SOD) and camouflaged object detection (COD) are two closely related but distinct computer vision tasks. Although both are class-agnostic segmentation tasks that map from RGB space to binary space, the former aims to identify the most salient objects in the image, while the latter focuses on detecting perfectly camouflaged objects that blend into the background in the image. These two tasks exhibit strong contradictory attributes. Previous works have mostly believed that joint learning of these two tasks would confuse the network, reducing its performance on both tasks. However, here we present an opposite perspective: with the correct approach to learning, the network can simultaneously possess the capability to find both salient and camouflaged objects, allowing both tasks to benefit from joint learning. We propose SCJoint, a joint learning scheme for SOD and COD tasks, assuming that the decoding processes of SOD and COD have different distribution characteristics. The key to our method is to learn the respective means and variances of the decoding processes for both tasks by inserting a minimal amount of task-specific learnable parameters within a fully shared network structure, thereby decoupling the contradictory attributes of the two tasks at a minimal cost. Furthermore, we propose a saliency-based sampling strategy (SBSS) to sample the training set of the SOD task to balance the training set sizes of the two tasks. In addition, SBSS improves the training set quality and shortens the training time. Based on the proposed SCJoint and SBSS, we train a powerful generalist network, named JoNet, which has the ability to simultaneously capture both ``salient" and ``camouflaged". Extensive experiments demonstrate the competitive performance and effectiveness of our proposed method. The code is available at https://github.com/linuxsino/JoNet.
FEALLM: Advancing Facial Emotion Analysis in Multimodal Large Language Models with Emotional Synergy and Reasoning
May 19, 2025Facial Emotion Analysis (FEA) plays a crucial role in visual affective computing, aiming to infer a person's emotional state based on facial data. Scientifically, facial expressions (FEs) result from the coordinated movement of facial muscles, which can be decomposed into specific action units (AUs) that provide detailed emotional insights. However, traditional methods often struggle with limited interpretability, constrained generalization and reasoning abilities. Recently, Multimodal Large Language Models (MLLMs) have shown exceptional performance in various visual tasks, while they still face significant challenges in FEA due to the lack of specialized datasets and their inability to capture the intricate relationships between FEs and AUs. To address these issues, we introduce a novel FEA Instruction Dataset that provides accurate and aligned FE and AU descriptions and establishes causal reasoning relationships between them, followed by constructing a new benchmark, FEABench. Moreover, we propose FEALLM, a novel MLLM architecture designed to capture more detailed facial information, enhancing its capability in FEA tasks. Our model demonstrates strong performance on FEABench and impressive generalization capability through zero-shot evaluation on various datasets, including RAF-DB, AffectNet, BP4D, and DISFA, showcasing its robustness and effectiveness in FEA tasks. The dataset and code will be available at https://github.com/953206211/FEALLM.
DSDNet: Raw Domain Demoiréing via Dual Color-Space Synergy
Apr 22, 2025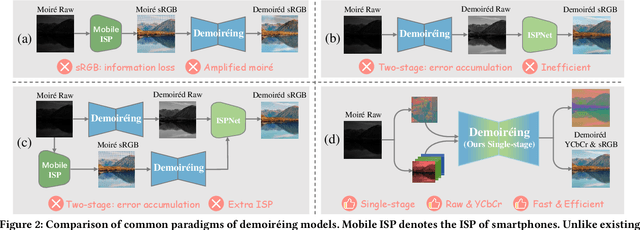
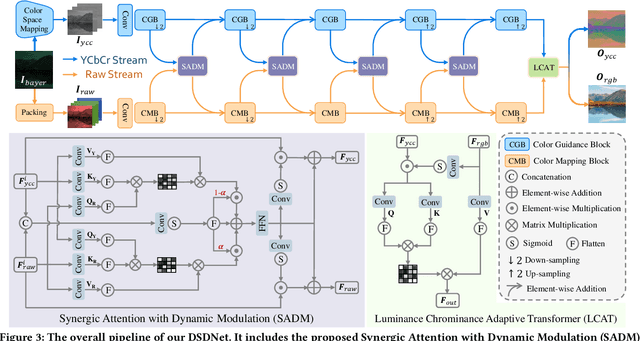
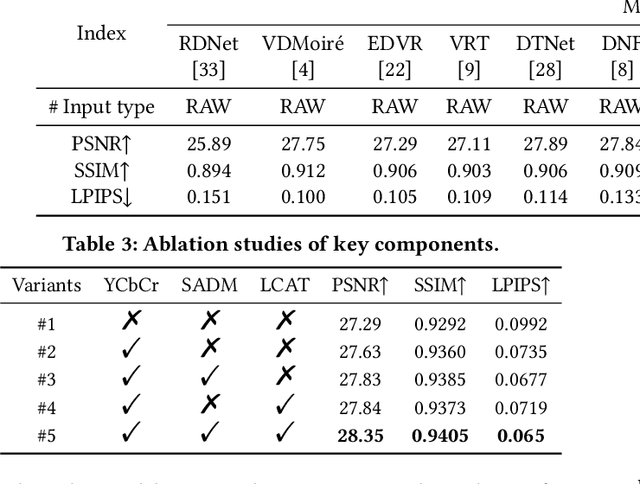
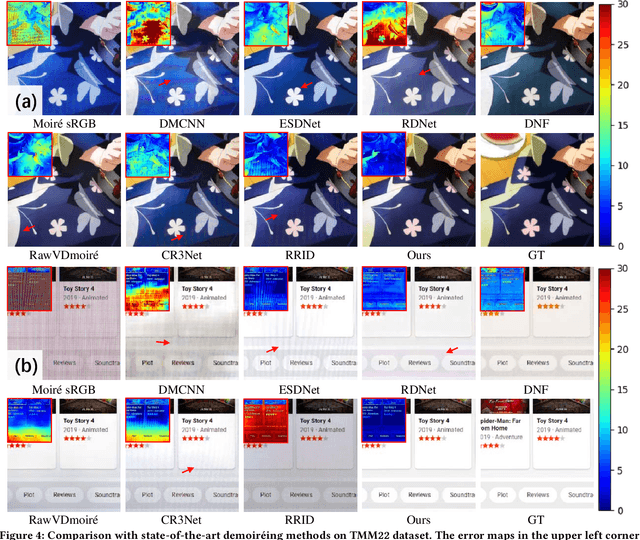
With the rapid advancement of mobile imaging, capturing screens using smartphones has become a prevalent practice in distance learning and conference recording. However, moir\'e artifacts, caused by frequency aliasing between display screens and camera sensors, are further amplified by the image signal processing pipeline, leading to severe visual degradation. Existing sRGB domain demoir\'eing methods struggle with irreversible information loss, while recent two-stage raw domain approaches suffer from information bottlenecks and inference inefficiency. To address these limitations, we propose a single-stage raw domain demoir\'eing framework, Dual-Stream Demoir\'eing Network (DSDNet), which leverages the synergy of raw and YCbCr images to remove moir\'e while preserving luminance and color fidelity. Specifically, to guide luminance correction and moir\'e removal, we design a raw-to-YCbCr mapping pipeline and introduce the Synergic Attention with Dynamic Modulation (SADM) module. This module enriches the raw-to-sRGB conversion with cross-domain contextual features. Furthermore, to better guide color fidelity, we develop a Luminance-Chrominance Adaptive Transformer (LCAT), which decouples luminance and chrominance representations. Extensive experiments demonstrate that DSDNet outperforms state-of-the-art methods in both visual quality and quantitative evaluation, and achieves an inference speed $\mathrm{\textbf{2.4x}}$ faster than the second-best method, highlighting its practical advantages. We provide an anonymous online demo at https://xxxxxxxxdsdnet.github.io/DSDNet/.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
FOF-X: Towards Real-time Detailed Human Reconstruction from a Single Image
Dec 08, 2024We introduce FOF-X for real-time reconstruction of detailed human geometry from a single image. Balancing real-time speed against high-quality results is a persistent challenge, mainly due to the high computational demands of existing 3D representations. To address this, we propose Fourier Occupancy Field (FOF), an efficient 3D representation by learning the Fourier series. The core of FOF is to factorize a 3D occupancy field into a 2D vector field, retaining topology and spatial relationships within the 3D domain while facilitating compatibility with 2D convolutional neural networks. Such a representation bridges the gap between 3D and 2D domains, enabling the integration of human parametric models as priors and enhancing the reconstruction robustness. Based on FOF, we design a new reconstruction framework, FOF-X, to avoid the performance degradation caused by texture and lighting. This enables our real-time reconstruction system to better handle the domain gap between training images and real images. Additionally, in FOF-X, we enhance the inter-conversion algorithms between FOF and mesh representations with a Laplacian constraint and an automaton-based discontinuity matcher, improving both quality and robustness. We validate the strengths of our approach on different datasets and real-captured data, where FOF-X achieves new state-of-the-art results. The code will be released for research purposes.