 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotionHallucer: Evaluating Emotion Hallucinations in Multimodal Large Language Models
May 16, 2025Emotion understanding is a critical yet challenging task. Recent advances in Multimodal Large Language Models (MLLMs) have significantly enhanced their capabilities in this area. However, MLLMs often suffer from hallucinations, generating irrelevant or nonsensical content. To the best of our knowledge, despite the importance of this issue, there has been no dedicated effort to evaluate emotion-related hallucinations in MLLMs. In this work, we introduce EmotionHallucer, the first benchmark for detecting and analyzing emotion hallucinations in MLLMs. Unlike humans, whose emotion understanding stems from the interplay of biology and social learning, MLLMs rely solely on data-driven learning and lack innate emotional instincts. Fortunately, emotion psychology provides a solid foundation of knowledge about human emotions. Building on this, we assess emotion hallucinations from two dimensions: emotion psychology knowledge and real-world multimodal perception. To support robust evaluation, we utilize an adversarial binary question-answer (QA) framework, which employs carefully crafted basic and hallucinated pairs to assess the emotion hallucination tendencies of MLLMs. By evaluating 38 LLMs and MLLMs on EmotionHallucer, we reveal that: i) most current models exhibit substantial issues with emotion hallucinations; ii) closed-source models outperform open-source ones in detecting emotion hallucinations, and reasoning capability provides additional advantages; iii) existing models perform better in emotion psychology knowledge than in multimodal emotion perception. As a byproduct, these findings inspire us to propose the PEP-MEK framework, which yields an average improvement of 9.90% in emotion hallucination detection across selected models. Resources will be available at https://github.com/xxtars/EmotionHallucer.
FSBench: A Figure Skating Benchmark for Advancing Artistic Sports Understanding
Apr 28, 2025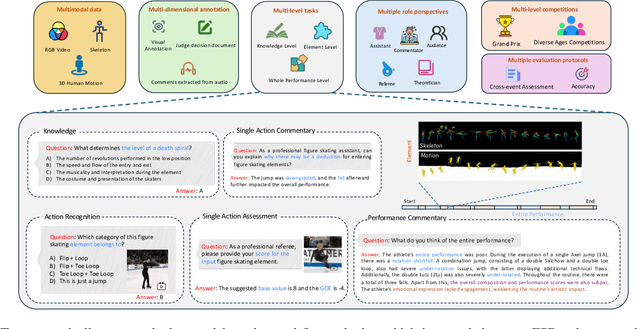
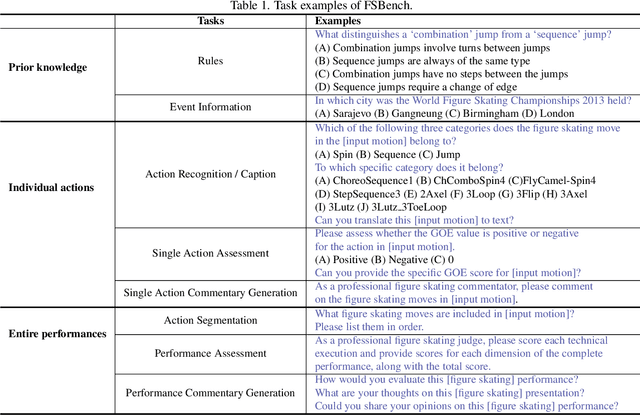
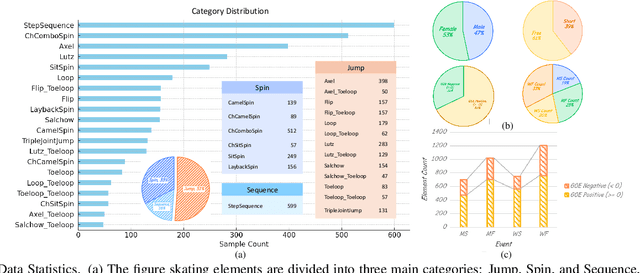
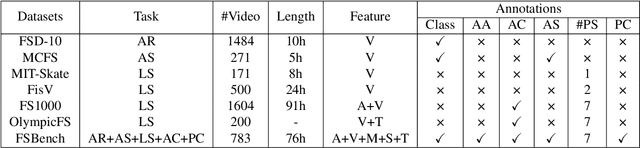
Figure skating, known as the "Art on Ice," is among the most artistic sports, challenging to understand due to its blend of technical elements (like jumps and spins) and overall artistic expression. Existing figure skating datasets mainly focus on single tasks, such as action recognition or scoring, lacking comprehensive annotations for both technical and artistic evaluation. Current sports research is largely centered on ball games, with limited relevance to artistic sports like figure skating. To address this, we introduce FSAnno, a large-scale dataset advancing artistic sports understanding through figure skating. FSAnno includes an open-access training and test dataset, alongside a benchmark dataset, FSBench, for fair model evaluation. FSBench consists of FSBench-Text, with multiple-choice questions and explanations, and FSBench-Motion, containing multimodal data and Question and Answer (QA) pairs, supporting tasks from technical analysis to performance commentary. Initial tests on FSBench reveal significant limitations in existing models' understanding of artistic sports. We hope FSBench will become a key tool for evaluating and enhancing model comprehension of figure skating.
DEEMO: De-identity Multimodal Emotion Recognition and Reasoning
Apr 28, 2025Emotion understanding is a critical yet challenging task. Most existing approaches rely heavily on identity-sensitive information, such as facial expressions and speech, which raises concerns about personal privacy. To address this, we introduce the De-identity Multimodal Emotion Recognition and Reasoning (DEEMO), a novel task designed to enable emotion understanding using de-identified video and audio inputs. The DEEMO dataset consists of two subsets: DEEMO-NFBL, which includes rich annotations of Non-Facial Body Language (NFBL), and DEEMO-MER, an instruction dataset for Multimodal Emotion Recognition and Reasoning using identity-free cues. This design supports emotion understanding without compromising identity privacy. In addition, we propose DEEMO-LLaMA, a Multimodal Large Language Model (MLLM) that integrates de-identified audio, video, and textual information to enhance both emotion recognition and reasoning. Extensive experiments show that DEEMO-LLaMA achieves state-of-the-art performance on both tasks, outperforming existing MLLMs by a significant margin, achieving 74.49% accuracy and 74.45% F1-score in de-identity emotion recognition, and 6.20 clue overlap and 7.66 label overlap in de-identity emotion reasoning. Our work contributes to ethical AI by advancing privacy-preserving emotion understanding and promoting responsible affective computing.
AU-TTT: Vision Test-Time Training model for Facial Action Unit Detection
Mar 30, 2025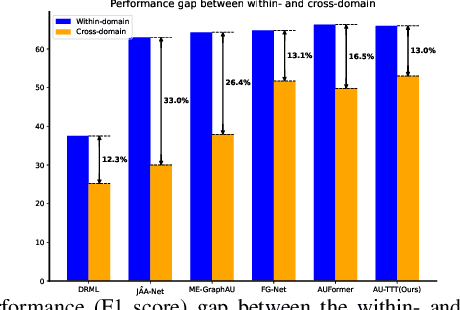
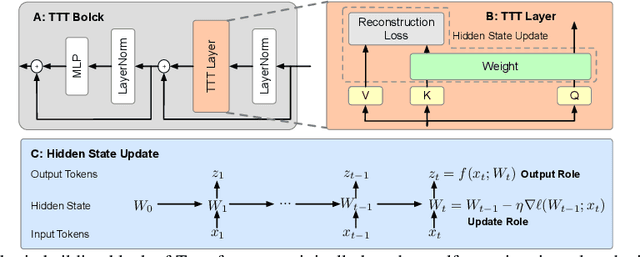
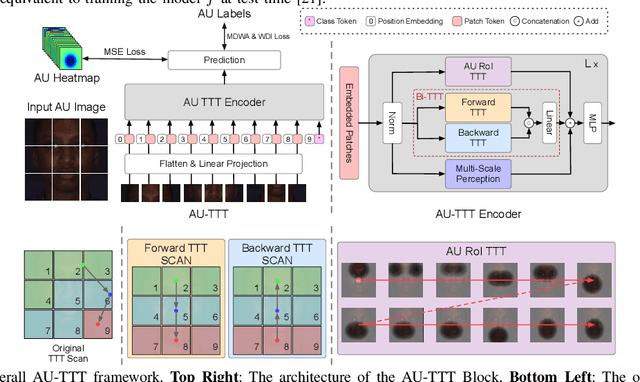
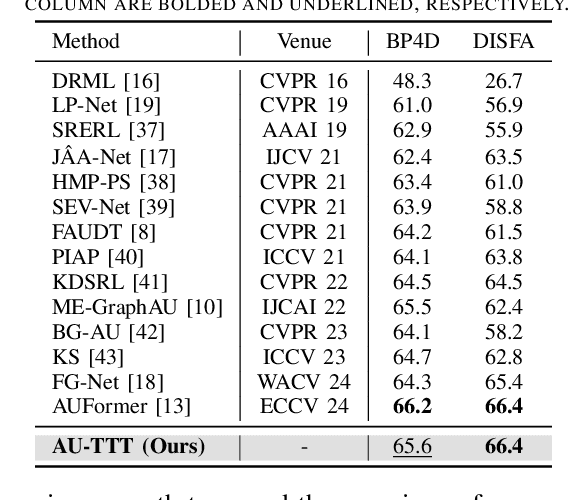
Facial Action Units (AUs) detection is a cornerstone of objective facial expression analysis and a critical focus in affective computing. Despite its importance, AU detection faces significant challenges, such as the high cost of AU annotation and the limited availability of datasets. These constraints often lead to overfitting in existing methods, resulting in substantial performance degradation when applied across diverse datasets. Addressing these issues is essential for improving the reliability and generalizability of AU detection methods. Moreover, many current approaches leverage Transformers for their effectiveness in long-context modeling, but they are hindered by the quadratic complexity of self-attention. Recently, Test-Time Training (TTT) layers have emerged as a promising solution for long-sequence modeling. Additionally, TTT applies self-supervised learning for iterative updates during both training and inference, offering a potential pathway to mitigate the generalization challenges inherent in AU detection tasks. In this paper, we propose a novel vision backbone tailored for AU detection, incorporating bidirectional TTT blocks, named AU-TTT. Our approach introduces TTT Linear to the AU detection task and optimizes image scanning mechanisms for enhanced performance. Additionally, we design an AU-specific Region of Interest (RoI) scanning mechanism to capture fine-grained facial features critical for AU detection. Experimental results demonstrate that our method achieves competitive performance in both within-domain and cross-domain scenarios.
scFusionTTT: Single-cell transcriptomics and proteomics fusion with Test-Time Training layers
Oct 17, 2024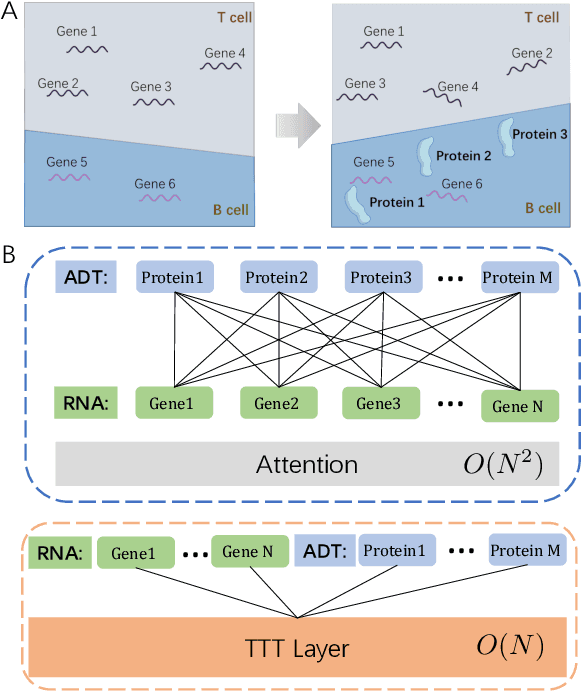
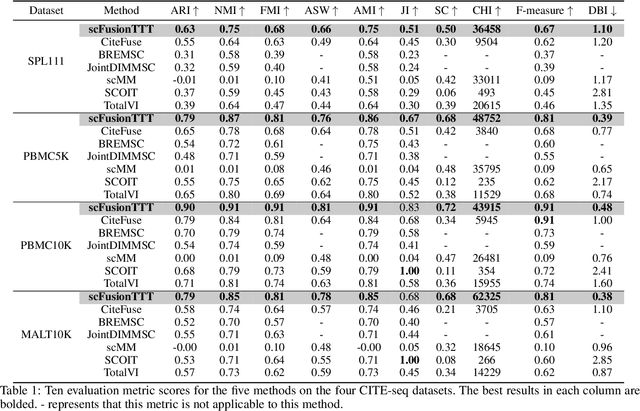
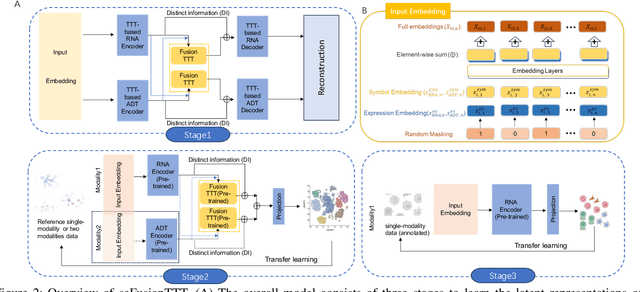
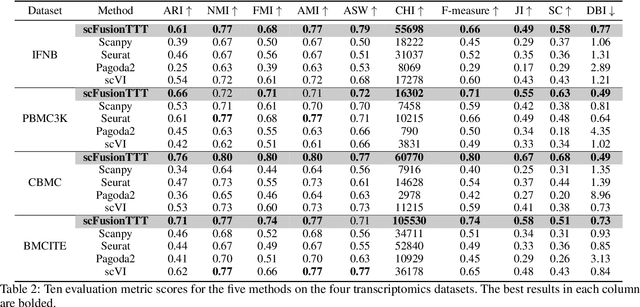
Single-cell multi-omics (scMulti-omics) refers to the paired multimodal data, such as Cellular Indexing of Transcriptomes and Epitopes by Sequencing (CITE-seq), where the regulation of each cell was measured from different modalities, i.e. genes and proteins. scMulti-omics can reveal heterogeneity inside tumors and understand the distinct genetic properties of diverse cell types, which is crucial to targeted therapy. Currently, deep learning methods based on attention structures in the bioinformatics area face two challenges. The first challenge is the vast number of genes in a single cell. Traditional attention-based modules struggled to effectively leverage all gene information due to their limited capacity for long-context learning and high-complexity computing. The second challenge is that genes in the human genome are ordered and influence each other's expression. Most of the methods ignored this sequential information. The recently introduced Test-Time Training (TTT) layer is a novel sequence modeling approach, particularly suitable for handling long contexts like genomics data because TTT layer is a linear complexity sequence modeling structure and is better suited to data with sequential relationships. In this paper, we propose scFusionTTT, a novel method for Single-Cell multimodal omics Fusion with TTT-based masked autoencoder. Of note, we combine the order information of genes and proteins in the human genome with the TTT layer, fuse multimodal omics, and enhance unimodal omics analysis. Finally, the model employs a three-stage training strategy, which yielded the best performance across most metrics in four multimodal omics datasets and four unimodal omics datasets, demonstrating the superior performance of our model. The dataset and code will be available on https://github.com/DM0815/scFusionTTT.
EMO-LLaMA: Enhancing Facial Emotion Understanding with Instruction Tuning
Aug 21, 2024



Facial expression recognition (FER) is an important research topic in emotional artificial intelligence. In recent decades, researchers have made remarkable progress. However, current FER paradigms face challenges in generalization, lack semantic information aligned with natural language, and struggle to process both images and videos within a unified framework, making their application in multimodal emotion understanding and human-computer interaction difficult. Multimodal Large Language Models (MLLMs) have recently achieved success, offering advantages in addressing these issues and potentially overcoming the limitations of current FER paradigms. However, directly applying pre-trained MLLMs to FER still faces several challenges. Our zero-shot evaluations of existing open-source MLLMs on FER indicate a significant performance gap compared to GPT-4V and current supervised state-of-the-art (SOTA) methods. In this paper, we aim to enhance MLLMs' capabilities in understanding facial expressions. We first generate instruction data for five FER datasets with Gemini. We then propose a novel MLLM, named EMO-LLaMA, which incorporates facial priors from a pretrained facial analysis network to enhance human facial information. Specifically, we design a Face Info Mining module to extract both global and local facial information. Additionally, we utilize a handcrafted prompt to introduce age-gender-race attributes, considering the emotional differences across different human groups. Extensive experiments show that EMO-LLaMA achieves SOTA-comparable or competitive results across both static and dynamic FER datasets. The instruction dataset and code are available at https://github.com/xxtars/EMO-LLaMA.
Identity-free Artificial Emotional Intelligence via Micro-Gesture Understanding
May 21, 2024
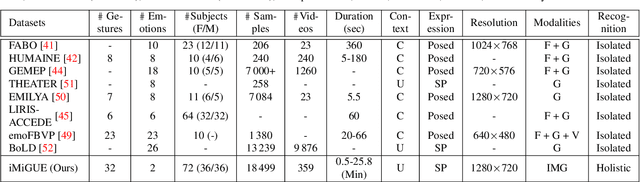
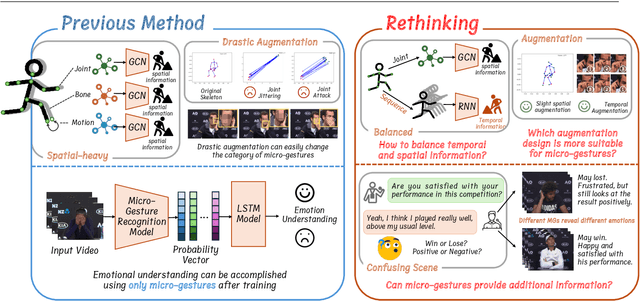
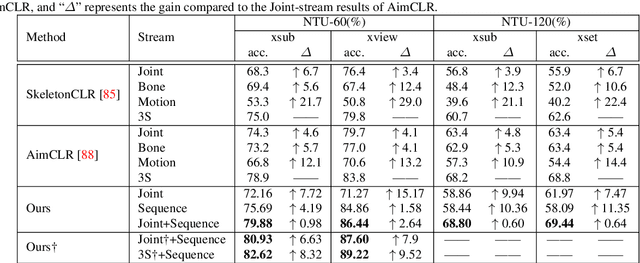
In this work, we focus on a special group of human body language -- the micro-gesture (MG), which differs from the range of ordinary illustrative gestures in that they are not intentional behaviors performed to convey information to others, but rather unintentional behaviors driven by inner feelings. This characteristic introduces two novel challenges regarding micro-gestures that are worth rethinking. The first is whether strategies designed for other action recognition are entirely applicable to micro-gestures. The second is whether micro-gestures, as supplementary data, can provide additional insights for emotional understanding. In recognizing micro-gestures, we explored various augmentation strategies that take into account the subtle spatial and brief temporal characteristics of micro-gestures, often accompanied by repetitiveness, to determine more suitable augmentation methods. Considering the significance of temporal domain information for micro-gestures, we introduce a simple and efficient plug-and-play spatiotemporal balancing fusion method. We not only studied our method on the considered micro-gesture dataset but also conducted experiments on mainstream action datasets. The results show that our approach performs well in micro-gesture recognition and on other datasets, achieving state-of-the-art performance compared to previous micro-gesture recognition methods. For emotional understanding based on micro-gestures, we construct complex emotional reasoning scenarios. Our evaluation, conducted with large language models, shows that micro-gestures play a significant and positive role in enhancing comprehensive emotional understanding. The scenarios we developed can be extended to other micro-gesture-based tasks such as deception detection and interviews. We confirm that our new insights contribute to advancing research in micro-gesture and emotional artificial intelligence.
Enhancing Micro Gesture Recognition for Emotion Understanding via Context-aware Visual-Text Contrastive Learning
May 03, 2024Psychological studies have shown that Micro Gestures (MG) are closely linked to human emotions. MG-based emotion understanding has attracted much attention because it allows for emotion understanding through nonverbal body gestures without relying on identity information (e.g., facial and electrocardiogram data). Therefore, it is essential to recognize MG effectively for advanced emotion understanding. However, existing Micro Gesture Recognition (MGR) methods utilize only a single modality (e.g., RGB or skeleton) while overlooking crucial textual information. In this letter, we propose a simple but effective visual-text contrastive learning solution that utilizes text information for MGR. In addition, instead of using handcrafted prompts for visual-text contrastive learning, we propose a novel module called Adaptive prompting to generate context-aware prompts. The experimental results show that the proposed method achieves state-of-the-art performance on two public datasets. Furthermore, based on an empirical study utilizing the results of MGR for emotion understanding, we demonstrate that using the textual results of MGR significantly improves performance by 6%+ compared to directly using video as input.
* accepted by IEEE Signal Processing Letters
EALD-MLLM: Emotion Analysis in Long-sequential and De-identity videos with Multi-modal Large Language Model
May 01, 2024Emotion AI is the ability of computers to understand human emotional states. Existing works have achieved promising progress, but two limitations remain to be solved: 1) Previous studies have been more focused on short sequential video emotion analysis while overlooking long sequential video. However, the emotions in short sequential videos only reflect instantaneous emotions, which may be deliberately guided or hidden. In contrast, long sequential videos can reveal authentic emotions; 2) Previous studies commonly utilize various signals such as facial, speech, and even sensitive biological signals (e.g., electrocardiogram). However, due to the increasing demand for privacy, developing Emotion AI without relying on sensitive signals is becoming important. To address the aforementioned limitations, in this paper, we construct a dataset for Emotion Analysis in Long-sequential and De-identity videos called EALD by collecting and processing the sequences of athletes' post-match interviews. In addition to providing annotations of the overall emotional state of each video, we also provide the Non-Facial Body Language (NFBL) annotations for each player. NFBL is an inner-driven emotional expression and can serve as an identity-free clue to understanding the emotional state. Moreover, we provide a simple but effective baseline for further research. More precisely, we evaluate the Multimodal Large Language Models (MLLMs) with de-identification signals (e.g., visual, speech, and NFBLs) to perform emotion analysis. Our experimental results demonstrate that: 1) MLLMs can achieve comparable, even better performance than the supervised single-modal models, even in a zero-shot scenario; 2) NFBL is an important cue in long sequential emotion analysis. EALD will be available on the open-source platform.