 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Guided Multimodal Unified Industrial Anomaly Detection
Apr 24, 2026Industrial anomaly detection based on RGB-3D multimodal data has emerged as a mainstream paradigm for intelligent quality inspection. However, existing unsupervised methods suffer from two critical limitations: ambiguous cross-modal alignment caused by the lack of high-level semantic guidance and insufficient geometric modeling for RGB-to-3D feature mapping. To address these issues, we propose a unified multimodal industrial anomaly detection framework guided by text semantics. The framework consists of two core modules: a Geometry-Aware Cross-Modal Mapper to preserve geometric structure during modality conversion, and an Object-Conditioned Textual Feature Adaptor to align multimodal features with semantic priors. Furthermore, we establish a unified learning paradigm for multimodal industrial anomaly detection, which breaks the one-model-one-class constraint and enables accurate anomaly detection across diverse classes using a single model. Extensive experiments on the MVTec 3D-AD and Eyecandies datasets demonstrate that our method achieves state-of-the-art performance in classification and localization under unsupervised settings.
PureCC: Pure Learning for Text-to-Image Concept Customization
Mar 08, 2026Existing concept customization methods have achieved remarkable outcomes in high-fidelity and multi-concept customization. However, they often neglect the influence on the original model's behavior and capabilities when learning new personalized concepts. To address this issue, we propose PureCC. PureCC introduces a novel decoupled learning objective for concept customization, which combines the implicit guidance of the target concept with the original conditional prediction. This separated form enables PureCC to substantially focus on the original model during training. Moreover, based on this objective, PureCC designs a dual-branch training pipeline that includes a frozen extractor providing purified target concept representations as implicit guidance and a trainable flow model producing the original conditional prediction, jointly achieving pure learning for personalized concepts. Furthermore, PureCC introduces a novel adaptive guidance scale $λ^\star$ to dynamically adjust the guidance strength of the target concept, balancing customization fidelity and model preservation. Extensive experiments show that PureCC achieves state-of-the-art performance in preserving the original behavior and capabilities while enabling high-fidelity concept customization. The code is available at https://github.com/lzc-sg/PureCC.
SUGAR: Learning Skeleton Representation with Visual-Motion Knowledge for Action Recognition
Nov 13, 2025Large Language Models (LLMs) hold rich implicit knowledge and powerful transferability. In this paper, we explore the combination of LLMs with the human skeleton to perform action classification and description. However, when treating LLM as a recognizer, two questions arise: 1) How can LLMs understand skeleton? 2) How can LLMs distinguish among actions? To address these problems, we introduce a novel paradigm named learning Skeleton representation with visUal-motion knowledGe for Action Recognition (SUGAR). In our pipeline, we first utilize off-the-shelf large-scale video models as a knowledge base to generate visual, motion information related to actions. Then, we propose to supervise skeleton learning through this prior knowledge to yield discrete representations. Finally, we use the LLM with untouched pre-training weights to understand these representations and generate the desired action targets and descriptions. Notably, we present a Temporal Query Projection (TQP) module to continuously model the skeleton signals with long sequences. Experiments on several skeleton-based action classification benchmarks demonstrate the efficacy of our SUGAR. Moreover, experiments on zero-shot scenarios show that SUGAR is more versatile than linear-based methods.
Distribution-Specific Learning for Joint Salient and Camouflaged Object Detection
Aug 08, 2025Salient object detection (SOD) and camouflaged object detection (COD) are two closely related but distinct computer vision tasks. Although both are class-agnostic segmentation tasks that map from RGB space to binary space, the former aims to identify the most salient objects in the image, while the latter focuses on detecting perfectly camouflaged objects that blend into the background in the image. These two tasks exhibit strong contradictory attributes. Previous works have mostly believed that joint learning of these two tasks would confuse the network, reducing its performance on both tasks. However, here we present an opposite perspective: with the correct approach to learning, the network can simultaneously possess the capability to find both salient and camouflaged objects, allowing both tasks to benefit from joint learning. We propose SCJoint, a joint learning scheme for SOD and COD tasks, assuming that the decoding processes of SOD and COD have different distribution characteristics. The key to our method is to learn the respective means and variances of the decoding processes for both tasks by inserting a minimal amount of task-specific learnable parameters within a fully shared network structure, thereby decoupling the contradictory attributes of the two tasks at a minimal cost. Furthermore, we propose a saliency-based sampling strategy (SBSS) to sample the training set of the SOD task to balance the training set sizes of the two tasks. In addition, SBSS improves the training set quality and shortens the training time. Based on the proposed SCJoint and SBSS, we train a powerful generalist network, named JoNet, which has the ability to simultaneously capture both ``salient" and ``camouflaged". Extensive experiments demonstrate the competitive performance and effectiveness of our proposed method. The code is available at https://github.com/linuxsino/JoNet.
Oral Imaging for Malocclusion Issues Assessments: OMNI Dataset, Deep Learning Baselines and Benchmarking
May 21, 2025Malocclusion is a major challenge in orthodontics, and its complex presentation and diverse clinical manifestations make accurate localization and diagnosis particularly important. Currently, one of the major shortcomings facing the field of dental image analysis is the lack of large-scale, accurately labeled datasets dedicated to malocclusion issues, which limits the development of automated diagnostics in the field of dentistry and leads to a lack of diagnostic accuracy and efficiency in clinical practice. Therefore, in this study, we propose the Oral and Maxillofacial Natural Images (OMNI) dataset, a novel and comprehensive dental image dataset aimed at advancing the study of analyzing dental images for issues of malocclusion. Specifically, the dataset contains 4166 multi-view images with 384 participants in data collection and annotated by professional dentists. In addition, we performed a comprehensive validation of the created OMNI dataset, including three CNN-based methods, two Transformer-based methods, and one GNN-based method, and conducted automated diagnostic experiments for malocclusion issues. The experimental results show that the OMNI dataset can facilitate the automated diagnosis research of malocclusion issues and provide a new benchmark for the research in this field. Our OMNI dataset and baseline code are publicly available at https://github.com/RoundFaceJ/OMNI.
Denoising and Alignment: Rethinking Domain Generalization for Multimodal Face Anti-Spoofing
May 14, 2025Face Anti-Spoofing (FAS) is essential for the security of facial recognition systems in diverse scenarios such as payment processing and surveillance. Current multimodal FAS methods often struggle with effective generalization, mainly due to modality-specific biases and domain shifts. To address these challenges, we introduce the \textbf{M}ulti\textbf{m}odal \textbf{D}enoising and \textbf{A}lignment (\textbf{MMDA}) framework. By leveraging the zero-shot generalization capability of CLIP, the MMDA framework effectively suppresses noise in multimodal data through denoising and alignment mechanisms, thereby significantly enhancing the generalization performance of cross-modal alignment. The \textbf{M}odality-\textbf{D}omain Joint \textbf{D}ifferential \textbf{A}ttention (\textbf{MD2A}) module in MMDA concurrently mitigates the impacts of domain and modality noise by refining the attention mechanism based on extracted common noise features. Furthermore, the \textbf{R}epresentation \textbf{S}pace \textbf{S}oft (\textbf{RS2}) Alignment strategy utilizes the pre-trained CLIP model to align multi-domain multimodal data into a generalized representation space in a flexible manner, preserving intricate representations and enhancing the model's adaptability to various unseen conditions. We also design a \textbf{U}-shaped \textbf{D}ual \textbf{S}pace \textbf{A}daptation (\textbf{U-DSA}) module to enhance the adaptability of representations while maintaining generalization performance. These improvements not only enhance the framework's generalization capabilities but also boost its ability to represent complex representations. Our experimental results on four benchmark datasets under different evaluation protocols demonstrate that the MMDA framework outperforms existing state-of-the-art methods in terms of cross-domain generalization and multimodal detection accuracy. The code will be released soon.
PhysLLM: Harnessing Large Language Models for Cross-Modal Remote Physiological Sensing
May 06, 2025Remote photoplethysmography (rPPG) enables non-contact physiological measurement but remains highly susceptible to illumination changes, motion artifacts, and limited temporal modeling. Large Language Models (LLMs) excel at capturing long-range dependencies, offering a potential solution but struggle with the continuous, noise-sensitive nature of rPPG signals due to their text-centric design. To bridge this gap, we introduce PhysLLM, a collaborative optimization framework that synergizes LLMs with domain-specific rPPG components. Specifically, the Text Prototype Guidance (TPG) strategy is proposed to establish cross-modal alignment by projecting hemodynamic features into LLM-interpretable semantic space, effectively bridging the representational gap between physiological signals and linguistic tokens. Besides, a novel Dual-Domain Stationary (DDS) Algorithm is proposed for resolving signal instability through adaptive time-frequency domain feature re-weighting. Finally, rPPG task-specific cues systematically inject physiological priors through physiological statistics, environmental contextual answering, and task description, leveraging cross-modal learning to integrate both visual and textual information, enabling dynamic adaptation to challenging scenarios like variable illumination and subject movements. Evaluation on four benchmark datasets, PhysLLM achieves state-of-the-art accuracy and robustness, demonstrating superior generalization across lighting variations and motion scenarios.
SPF-Portrait: Towards Pure Portrait Customization with Semantic Pollution-Free Fine-tuning
Apr 01, 2025
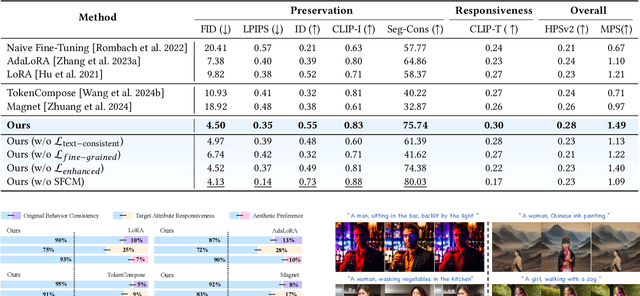


While fine-tuning pre-trained Text-to-Image (T2I) models on portrait datasets enables attribute customization, existing methods suffer from Semantic Pollution that compromises the original model's behavior and prevents incremental learning. To address this, we propose SPF-Portrait, a pioneering work to purely understand customized semantics while eliminating semantic pollution in text-driven portrait customization. In our SPF-Portrait, we propose a dual-path pipeline that introduces the original model as a reference for the conventional fine-tuning path. Through contrastive learning, we ensure adaptation to target attributes and purposefully align other unrelated attributes with the original portrait. We introduce a novel Semantic-Aware Fine Control Map, which represents the precise response regions of the target semantics, to spatially guide the alignment process between the contrastive paths. This alignment process not only effectively preserves the performance of the original model but also avoids over-alignment. Furthermore, we propose a novel response enhancement mechanism to reinforce the performance of target attributes, while mitigating representation discrepancy inherent in direct cross-modal supervision. Extensive experiments demonstrate that SPF-Portrait achieves state-of-the-art performance.
Benchmarking Graph Representations and Graph Neural Networks for Multivariate Time Series Classification
Jan 14, 2025Multivariate Time Series Classification (MTSC) enables the analysis if complex temporal data, and thus serves as a cornerstone in various real-world applications, ranging from healthcare to finance. Since the relationship among variables in MTS usually contain crucial cues, a large number of graph-based MTSC approaches have been proposed, as the graph topology and edges can explicitly represent relationships among variables (channels), where not only various MTS graph representation learning strategies but also different Graph Neural Networks (GNNs) have been explored. Despite such progresses, there is no comprehensive study that fairly benchmarks and investigates the performances of existing widely-used graph representation learning strategies/GNN classifiers in the application of different MTSC tasks. In this paper, we present the first benchmark which systematically investigates the effectiveness of the widely-used three node feature definition strategies, four edge feature learning strategies and five GNN architecture, resulting in 60 different variants for graph-based MTSC. These variants are developed and evaluated with a standardized data pipeline and training/validation/testing strategy on 26 widely-used suspensor MTSC datasets. Our experiments highlight that node features significantly influence MTSC performance, while the visualization of edge features illustrates why adaptive edge learning outperforms other edge feature learning methods. The code of the proposed benchmark is publicly available at \url{https://github.com/CVI-yangwn/Benchmark-GNN-for-Multivariate-Time-Series-Classification}.
DEGSTalk: Decomposed Per-Embedding Gaussian Fields for Hair-Preserving Talking Face Synthesis
Dec 28, 2024



Accurately synthesizing talking face videos and capturing fine facial features for individuals with long hair presents a significant challenge. To tackle these challenges in existing methods, we propose a decomposed per-embedding Gaussian fields (DEGSTalk), a 3D Gaussian Splatting (3DGS)-based talking face synthesis method for generating realistic talking faces with long hairs. Our DEGSTalk employs Deformable Pre-Embedding Gaussian Fields, which dynamically adjust pre-embedding Gaussian primitives using implicit expression coefficients. This enables precise capture of dynamic facial regions and subtle expressions. Additionally, we propose a Dynamic Hair-Preserving Portrait Rendering technique to enhance the realism of long hair motions in the synthesized videos. Results show that DEGSTalk achieves improved realism and synthesis quality compared to existing approaches, particularly in handling complex facial dynamics and hair preservation. Our code will be publicly available at https://github.com/CVI-SZU/DEGSTalk.