 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPF-Portrait: Towards Pure Portrait Customization with Semantic Pollution-Free Fine-tuning
Apr 01, 2025
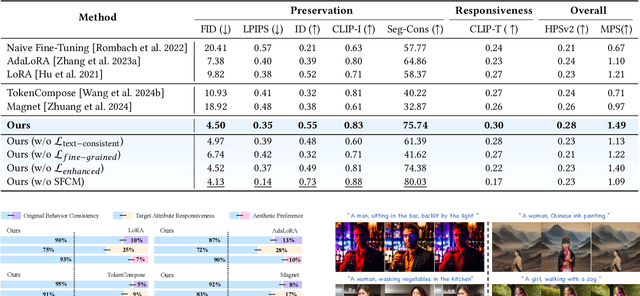


While fine-tuning pre-trained Text-to-Image (T2I) models on portrait datasets enables attribute customization, existing methods suffer from Semantic Pollution that compromises the original model's behavior and prevents incremental learning. To address this, we propose SPF-Portrait, a pioneering work to purely understand customized semantics while eliminating semantic pollution in text-driven portrait customization. In our SPF-Portrait, we propose a dual-path pipeline that introduces the original model as a reference for the conventional fine-tuning path. Through contrastive learning, we ensure adaptation to target attributes and purposefully align other unrelated attributes with the original portrait. We introduce a novel Semantic-Aware Fine Control Map, which represents the precise response regions of the target semantics, to spatially guide the alignment process between the contrastive paths. This alignment process not only effectively preserves the performance of the original model but also avoids over-alignment. Furthermore, we propose a novel response enhancement mechanism to reinforce the performance of target attributes, while mitigating representation discrepancy inherent in direct cross-modal supervision. Extensive experiments demonstrate that SPF-Portrait achieves state-of-the-art performance.
CA-Edit: Causality-Aware Condition Adapter for High-Fidelity Local Facial Attribute Editing
Dec 18, 2024



For efficient and high-fidelity local facial attribute editing, most existing editing methods either require additional fine-tuning for different editing effects or tend to affect beyond the editing regions. Alternatively, inpainting methods can edit the target image region while preserving external areas. However, current inpainting methods still suffer from the generation misalignment with facial attributes description and the loss of facial skin details. To address these challenges, (i) a novel data utilization strategy is introduced to construct datasets consisting of attribute-text-image triples from a data-driven perspective, (ii) a Causality-Aware Condition Adapter is proposed to enhance the contextual causality modeling of specific details, which encodes the skin details from the original image while preventing conflicts between these cues and textual conditions. In addition, a Skin Transition Frequency Guidance technique is introduced for the local modeling of contextual causality via sampling guidance driven by low-frequency alignment. Extensive quantitative and qualitative experiments demonstrate the effectiveness of our method in boosting both fidelity and editability for localized attribute editing. The code is available at https://github.com/connorxian/CA-Edit.
SynFER: Towards Boosting Facial Expression Recognition with Synthetic Data
Oct 13, 2024


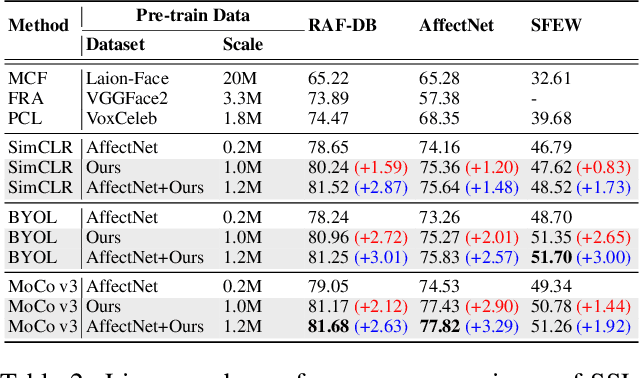
Facial expression datasets remain limited in scale due to privacy concerns, the subjectivity of annotations, and the labor-intensive nature of data collection. This limitation poses a significant challenge for developing modern deep learning-based facial expression analysis models, particularly foundation models, that rely on large-scale data for optimal performance. To tackle the overarching and complex challenge, we introduce SynFER (Synthesis of Facial Expressions with Refined Control), a novel framework for synthesizing facial expression image data based on high-level textual descriptions as well as more fine-grained and precise control through facial action units. To ensure the quality and reliability of the synthetic data, we propose a semantic guidance technique to steer the generation process and a pseudo-label generator to help rectify the facial expression labels for the synthetic images. To demonstrate the generation fidelity and the effectiveness of the synthetic data from SynFER, we conduct extensive experiments on representation learning using both synthetic data and real-world data. Experiment results validate the efficacy of the proposed approach and the synthetic data. Notably, our approach achieves a 67.23% classification accuracy on AffectNet when training solely with synthetic data equivalent to the AffectNet training set size, which increases to 69.84% when scaling up to five times the original size. Our code will be made publicly available.