 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePureCC: Pure Learning for Text-to-Image Concept Customization
Mar 08, 2026Existing concept customization methods have achieved remarkable outcomes in high-fidelity and multi-concept customization. However, they often neglect the influence on the original model's behavior and capabilities when learning new personalized concepts. To address this issue, we propose PureCC. PureCC introduces a novel decoupled learning objective for concept customization, which combines the implicit guidance of the target concept with the original conditional prediction. This separated form enables PureCC to substantially focus on the original model during training. Moreover, based on this objective, PureCC designs a dual-branch training pipeline that includes a frozen extractor providing purified target concept representations as implicit guidance and a trainable flow model producing the original conditional prediction, jointly achieving pure learning for personalized concepts. Furthermore, PureCC introduces a novel adaptive guidance scale $λ^\star$ to dynamically adjust the guidance strength of the target concept, balancing customization fidelity and model preservation. Extensive experiments show that PureCC achieves state-of-the-art performance in preserving the original behavior and capabilities while enabling high-fidelity concept customization. The code is available at https://github.com/lzc-sg/PureCC.
SPF-Portrait: Towards Pure Portrait Customization with Semantic Pollution-Free Fine-tuning
Apr 01, 2025
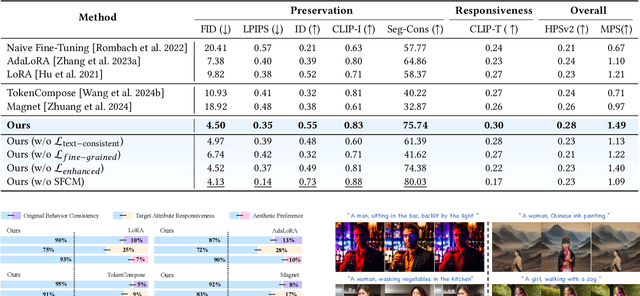


While fine-tuning pre-trained Text-to-Image (T2I) models on portrait datasets enables attribute customization, existing methods suffer from Semantic Pollution that compromises the original model's behavior and prevents incremental learning. To address this, we propose SPF-Portrait, a pioneering work to purely understand customized semantics while eliminating semantic pollution in text-driven portrait customization. In our SPF-Portrait, we propose a dual-path pipeline that introduces the original model as a reference for the conventional fine-tuning path. Through contrastive learning, we ensure adaptation to target attributes and purposefully align other unrelated attributes with the original portrait. We introduce a novel Semantic-Aware Fine Control Map, which represents the precise response regions of the target semantics, to spatially guide the alignment process between the contrastive paths. This alignment process not only effectively preserves the performance of the original model but also avoids over-alignment. Furthermore, we propose a novel response enhancement mechanism to reinforce the performance of target attributes, while mitigating representation discrepancy inherent in direct cross-modal supervision. Extensive experiments demonstrate that SPF-Portrait achieves state-of-the-art performance.
HumanAesExpert: Advancing a Multi-Modality Foundation Model for Human Image Aesthetic Assessment
Mar 31, 2025



Image Aesthetic Assessment (IAA) is a long-standing and challenging research task. However, its subset, Human Image Aesthetic Assessment (HIAA), has been scarcely explored, even though HIAA is widely used in social media, AI workflows, and related domains. To bridge this research gap, our work pioneers a holistic implementation framework tailored for HIAA. Specifically, we introduce HumanBeauty, the first dataset purpose-built for HIAA, which comprises 108k high-quality human images with manual annotations. To achieve comprehensive and fine-grained HIAA, 50K human images are manually collected through a rigorous curation process and annotated leveraging our trailblazing 12-dimensional aesthetic standard, while the remaining 58K with overall aesthetic labels are systematically filtered from public datasets. Based on the HumanBeauty database, we propose HumanAesExpert, a powerful Vision Language Model for aesthetic evaluation of human images. We innovatively design an Expert head to incorporate human knowledge of aesthetic sub-dimensions while jointly utilizing the Language Modeling (LM) and Regression head. This approach empowers our model to achieve superior proficiency in both overall and fine-grained HIAA. Furthermore, we introduce a MetaVoter, which aggregates scores from all three heads, to effectively balance the capabilities of each head, thereby realizing improved assessment precision. Extensive experiments demonstrate that our HumanAesExpert models deliver significantly better performance in HIAA than other state-of-the-art models. Our datasets, models, and codes are publicly released to advance the HIAA community. Project webpage: https://humanaesexpert.github.io/HumanAesExpert/
AnyDressing: Customizable Multi-Garment Virtual Dressing via Latent Diffusion Models
Dec 05, 2024



Recent advances in garment-centric image generation from text and image prompts based on diffusion models are impressive. However, existing methods lack support for various combinations of attire, and struggle to preserve the garment details while maintaining faithfulness to the text prompts, limiting their performance across diverse scenarios. In this paper, we focus on a new task, i.e., Multi-Garment Virtual Dressing, and we propose a novel AnyDressing method for customizing characters conditioned on any combination of garments and any personalized text prompts. AnyDressing comprises two primary networks named GarmentsNet and DressingNet, which are respectively dedicated to extracting detailed clothing features and generating customized images. Specifically, we propose an efficient and scalable module called Garment-Specific Feature Extractor in GarmentsNet to individually encode garment textures in parallel. This design prevents garment confusion while ensuring network efficiency. Meanwhile, we design an adaptive Dressing-Attention mechanism and a novel Instance-Level Garment Localization Learning strategy in DressingNet to accurately inject multi-garment features into their corresponding regions. This approach efficiently integrates multi-garment texture cues into generated images and further enhances text-image consistency. Additionally, we introduce a Garment-Enhanced Texture Learning strategy to improve the fine-grained texture details of garments. Thanks to our well-craft design, AnyDressing can serve as a plug-in module to easily integrate with any community control extensions for diffusion models, improving the diversity and controllability of synthesized images. Extensive experiments show that AnyDressing achieves state-of-the-art results.
2DGS-Room: Seed-Guided 2D Gaussian Splatting with Geometric Constrains for High-Fidelity Indoor Scene Reconstruction
Dec 04, 2024



The reconstruction of indoor scenes remains challenging due to the inherent complexity of spatial structures and the prevalence of textureless regions. Recent advancements in 3D Gaussian Splatting have improved novel view synthesis with accelerated processing but have yet to deliver comparable performance in surface reconstruction. In this paper, we introduce 2DGS-Room, a novel method leveraging 2D Gaussian Splatting for high-fidelity indoor scene reconstruction. Specifically, we employ a seed-guided mechanism to control the distribution of 2D Gaussians, with the density of seed points dynamically optimized through adaptive growth and pruning mechanisms. To further improve geometric accuracy, we incorporate monocular depth and normal priors to provide constraints for details and textureless regions respectively. Additionally, multi-view consistency constraints are employed to mitigate artifacts and further enhance reconstruction quality. Extensive experiments on ScanNet and ScanNet++ datasets demonstrate that our method achieves state-of-the-art performance in indoor scene reconstruction.
Constraint Learning for Parametric Point Cloud
Nov 12, 2024



Parametric point clouds are sampled from CAD shapes, have become increasingly prevalent in industrial manufacturing. However, most existing point cloud learning methods focus on the geometric features, such as local and global features or developing efficient convolution operations, overlooking the important attribute of constraints inherent in CAD shapes, which limits these methods' ability to fully comprehend CAD shapes. To address this issue, we analyzed the effect of constraints, and proposed its deep learning-friendly representation, after that, the Constraint Feature Learning Network (CstNet) is developed to extract and leverage constraints. Our CstNet includes two stages. The Stage 1 extracts constraints from B-Rep data or point cloud. The Stage 2 leverages coordinates and constraints to enhance the comprehend of CAD shapes. Additionally, we built up the Parametric 20,000 Multi-modal Dataset for the scarcity of labeled B-Rep datasets. Experiments demonstrate that our CstNet achieved state-of-the-art performance on both public and proposed CAD shapes datasets. To the best of our knowledge, CstNet is the first constraint-based learning method tailored for CAD shapes analysis.
Training-Free Point Cloud Recognition Based on Geometric and Semantic Information Fusion
Sep 11, 2024



The trend of employing training-free methods for point cloud recognition is becoming increasingly popular due to its significant reduction in computational resources and time costs. However, existing approaches are limited as they typically extract either geometric or semantic features. To address this limitation, we are the first to propose a novel training-free method that integrates both geometric and semantic features. For the geometric branch, we adopt a non-parametric strategy to extract geometric features. In the semantic branch, we leverage a model aligned with text features to obtain semantic features. Additionally, we introduce the GFE module to complement the geometric information of point clouds and the MFF module to improve performance in few-shot settings. Experimental results demonstrate that our method outperforms existing state-of-the-art training-free approaches on mainstream benchmark datasets, including ModelNet and ScanObiectNN.
Freehand Sketch Generation from Mechanical Components
Aug 12, 2024



Drawing freehand sketches of mechanical components on multimedia devices for AI-based engineering modeling has become a new trend. However, its development is being impeded because existing works cannot produce suitable sketches for data-driven research. These works either generate sketches lacking a freehand style or utilize generative models not originally designed for this task resulting in poor effectiveness. To address this issue, we design a two-stage generative framework mimicking the human sketching behavior pattern, called MSFormer, which is the first time to produce humanoid freehand sketches tailored for mechanical components. The first stage employs Open CASCADE technology to obtain multi-view contour sketches from mechanical components, filtering perturbing signals for the ensuing generation process. Meanwhile, we design a view selector to simulate viewpoint selection tasks during human sketching for picking out information-rich sketches. The second stage translates contour sketches into freehand sketches by a transformer-based generator. To retain essential modeling features as much as possible and rationalize stroke distribution, we introduce a novel edge-constraint stroke initialization. Furthermore, we utilize a CLIP vision encoder and a new loss function incorporating the Hausdorff distance to enhance the generalizability and robustness of the model. Extensive experiments demonstrate that our approach achieves state-of-the-art performance for generating freehand sketches in the mechanical domain. Project page: https://mcfreeskegen.github.io .
GaussianRoom: Improving 3D Gaussian Splatting with SDF Guidance and Monocular Cues for Indoor Scene Reconstruction
May 30, 2024



Recently, 3D Gaussian Splatting(3DGS) has revolutionized neural rendering with its high-quality rendering and real-time speed. However, when it comes to indoor scenes with a significant number of textureless areas, 3DGS yields incomplete and noisy reconstruction results due to the poor initialization of the point cloud and under-constrained optimization. Inspired by the continuity of signed distance field (SDF), which naturally has advantages in modeling surfaces, we present a unified optimizing framework integrating neural SDF with 3DGS. This framework incorporates a learnable neural SDF field to guide the densification and pruning of Gaussians, enabling Gaussians to accurately model scenes even with poor initialized point clouds. At the same time, the geometry represented by Gaussians improves the efficiency of the SDF field by piloting its point sampling. Additionally, we regularize the optimization with normal and edge priors to eliminate geometry ambiguity in textureless areas and improve the details. Extensive experiments in ScanNet and ScanNet++ show that our method achieves state-of-the-art performance in both surface reconstruction and novel view synthesis.