 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
FilmWeaver: Weaving Consistent Multi-Shot Videos with Cache-Guided Autoregressive Diffusion
Dec 12, 2025Current video generation models perform well at single-shot synthesis but struggle with multi-shot videos, facing critical challenges in maintaining character and background consistency across shots and flexibly generating videos of arbitrary length and shot count. To address these limitations, we introduce \textbf{FilmWeaver}, a novel framework designed to generate consistent, multi-shot videos of arbitrary length. First, it employs an autoregressive diffusion paradigm to achieve arbitrary-length video generation. To address the challenge of consistency, our key insight is to decouple the problem into inter-shot consistency and intra-shot coherence. We achieve this through a dual-level cache mechanism: a shot memory caches keyframes from preceding shots to maintain character and scene identity, while a temporal memory retains a history of frames from the current shot to ensure smooth, continuous motion. The proposed framework allows for flexible, multi-round user interaction to create multi-shot videos. Furthermore, due to this decoupled design, our method demonstrates high versatility by supporting downstream tasks such as multi-concept injection and video extension. To facilitate the training of our consistency-aware method, we also developed a comprehensive pipeline to construct a high-quality multi-shot video dataset. Extensive experimental results demonstrate that our method surpasses existing approaches on metrics for both consistency and aesthetic quality, opening up new possibilities for creating more consistent, controllable, and narrative-driven video content. Project Page: https://filmweaver.github.io
SPF-Portrait: Towards Pure Portrait Customization with Semantic Pollution-Free Fine-tuning
Apr 01, 2025
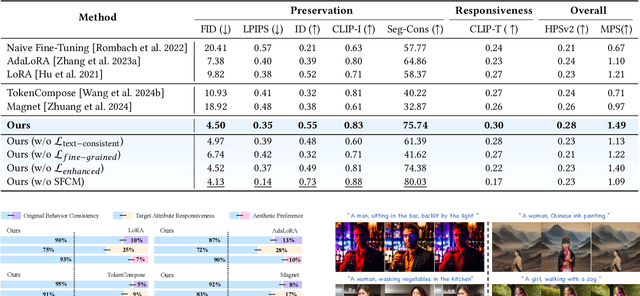


While fine-tuning pre-trained Text-to-Image (T2I) models on portrait datasets enables attribute customization, existing methods suffer from Semantic Pollution that compromises the original model's behavior and prevents incremental learning. To address this, we propose SPF-Portrait, a pioneering work to purely understand customized semantics while eliminating semantic pollution in text-driven portrait customization. In our SPF-Portrait, we propose a dual-path pipeline that introduces the original model as a reference for the conventional fine-tuning path. Through contrastive learning, we ensure adaptation to target attributes and purposefully align other unrelated attributes with the original portrait. We introduce a novel Semantic-Aware Fine Control Map, which represents the precise response regions of the target semantics, to spatially guide the alignment process between the contrastive paths. This alignment process not only effectively preserves the performance of the original model but also avoids over-alignment. Furthermore, we propose a novel response enhancement mechanism to reinforce the performance of target attributes, while mitigating representation discrepancy inherent in direct cross-modal supervision. Extensive experiments demonstrate that SPF-Portrait achieves state-of-the-art performance.
HumanAesExpert: Advancing a Multi-Modality Foundation Model for Human Image Aesthetic Assessment
Mar 31, 2025



Image Aesthetic Assessment (IAA) is a long-standing and challenging research task. However, its subset, Human Image Aesthetic Assessment (HIAA), has been scarcely explored, even though HIAA is widely used in social media, AI workflows, and related domains. To bridge this research gap, our work pioneers a holistic implementation framework tailored for HIAA. Specifically, we introduce HumanBeauty, the first dataset purpose-built for HIAA, which comprises 108k high-quality human images with manual annotations. To achieve comprehensive and fine-grained HIAA, 50K human images are manually collected through a rigorous curation process and annotated leveraging our trailblazing 12-dimensional aesthetic standard, while the remaining 58K with overall aesthetic labels are systematically filtered from public datasets. Based on the HumanBeauty database, we propose HumanAesExpert, a powerful Vision Language Model for aesthetic evaluation of human images. We innovatively design an Expert head to incorporate human knowledge of aesthetic sub-dimensions while jointly utilizing the Language Modeling (LM) and Regression head. This approach empowers our model to achieve superior proficiency in both overall and fine-grained HIAA. Furthermore, we introduce a MetaVoter, which aggregates scores from all three heads, to effectively balance the capabilities of each head, thereby realizing improved assessment precision. Extensive experiments demonstrate that our HumanAesExpert models deliver significantly better performance in HIAA than other state-of-the-art models. Our datasets, models, and codes are publicly released to advance the HIAA community. Project webpage: https://humanaesexpert.github.io/HumanAesExpert/
Improving Video Generation with Human Feedback
Jan 23, 2025



Video generation has achieved significant advances through rectified flow techniques, but issues like unsmooth motion and misalignment between videos and prompts persist. In this work, we develop a systematic pipeline that harnesses human feedback to mitigate these problems and refine the video generation model. Specifically, we begin by constructing a large-scale human preference dataset focused on modern video generation models, incorporating pairwise annotations across multi-dimensions. We then introduce VideoReward, a multi-dimensional video reward model, and examine how annotations and various design choices impact its rewarding efficacy. From a unified reinforcement learning perspective aimed at maximizing reward with KL regularization, we introduce three alignment algorithms for flow-based models by extending those from diffusion models. These include two training-time strategies: direct preference optimization for flow (Flow-DPO) and reward weighted regression for flow (Flow-RWR), and an inference-time technique, Flow-NRG, which applies reward guidance directly to noisy videos. Experimental results indicate that VideoReward significantly outperforms existing reward models, and Flow-DPO demonstrates superior performance compared to both Flow-RWR and standard supervised fine-tuning methods. Additionally, Flow-NRG lets users assign custom weights to multiple objectives during inference, meeting personalized video quality needs. Project page: https://gongyeliu.github.io/videoalign.
Adaptive Finite-Time Model Estimation and Control for Manipulator Visual Servoing using Sliding Mode Control and Neural Networks
Nov 21, 2022The image-based visual servoing without models of system is challenging since it is hard to fetch an accurate estimation of hand-eye relationship via merely visual measurement. Whereas, the accuracy of estimated hand-eye relationship expressed in local linear format with Jacobian matrix is important to whole system's performance. In this article, we proposed a finite-time controller as well as a Jacobian matrix estimator in a combination of online and offline way. The local linear formulation is formulated first. Then, we use a combination of online and offline method to boost the estimation of the highly coupled and nonlinear hand-eye relationship with data collected via depth camera. A neural network (NN) is pre-trained to give a relative reasonable initial estimation of Jacobian matrix. Then, an online updating method is carried out to modify the offline trained NN for a more accurate estimation. Moreover, sliding mode control algorithm is introduced to realize a finite-time controller. Compared with previous methods, our algorithm possesses better convergence speed. The proposed estimator possesses excellent performance in the accuracy of initial estimation and powerful tracking capabilities for time-varying estimation for Jacobian matrix compared with other data-driven estimators. The proposed scheme acquires the combination of neural network and finite-time control effect which drives a faster convergence speed compared with the exponentially converge ones. Another main feature of our algorithm is that the state signals in system is proved to be semi-global practical finite-time stable. Several experiments are carried out to validate proposed algorithm's performance.
A Novel Uncalibrated Visual Servoing Controller Baesd on Model-Free Adaptive Control Method with Neural Network
Nov 21, 2022



Nowadays, with the continuous expansion of application scenarios of robotic arms, there are more and more scenarios where nonspecialist come into contact with robotic arms. However, in terms of robotic arm visual servoing, traditional Position-based Visual Servoing (PBVS) requires a lot of calibration work, which is challenging for the nonspecialist to cope with. To cope with this situation, Uncalibrated Image-Based Visual Servoing (UIBVS) frees people from tedious calibration work. This work applied a model-free adaptive control (MFAC) method which means that the parameters of controller are updated in real time, bringing better ability of suppression changes of system and environment. An artificial intelligent neural network is applied in designs of controller and estimator for hand-eye relationship. The neural network is updated with the knowledge of the system input and output information in MFAC method. Inspired by "predictive model" and "receding-horizon" in Model Predictive Control (MPC) method and introducing similar structures into our algorithm, we realizes the uncalibrated visual servoing for both stationary targets and moving trajectories. Simulated experiments with a robotic manipulator will be carried out to validate the proposed algorithm.