 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Intelligent Industrial Robotics: Concepts and Techniques
May 15, 2025In recent years, embodied intelligent robotics (EIR) has made significant progress in multi-modal perception, autonomous decision-making, and physical interaction. Some robots have already been tested in general-purpose scenarios such as homes and shopping malls. We aim to advance the research and application of embodied intelligence in industrial scenes. However, current EIR lacks a deep understanding of industrial environment semantics and the normative constraints between industrial operating objects. To address this gap, this paper first reviews the history of industrial robotics and the mainstream EIR frameworks. We then introduce the concept of the embodied intelligent industrial robotics (EIIR) and propose a knowledge-driven EIIR technology framework for industrial environments. The framework includes four main modules: world model, high-level task planner, low-level skill controller, and simulator. We also review the current development of technologies related to each module and highlight recent progress in adapting them to industrial applications. Finally, we summarize the key challenges EIIR faces in industrial scenarios and suggest future research directions. We believe that EIIR technology will shape the next generation of industrial robotics. Industrial systems based on embodied intelligent industrial robots offer strong potential for enabling intelligent manufacturing. We will continue to track and summarize new research in this area and hope this review will serve as a valuable reference for scholars and engineers interested in industrial embodied intelligence. Together, we can help drive the rapid advancement and application of this technology. The associated project can be found at https://github.com/jackyzengl/EIIR.
SPF-Portrait: Towards Pure Portrait Customization with Semantic Pollution-Free Fine-tuning
Apr 01, 2025
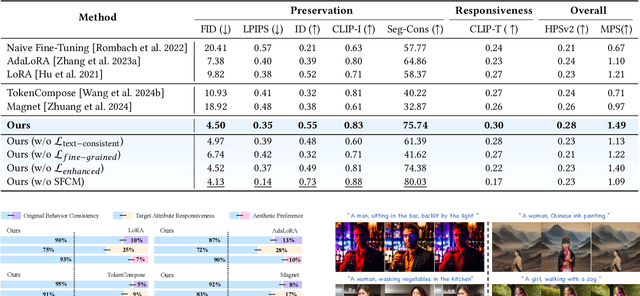


While fine-tuning pre-trained Text-to-Image (T2I) models on portrait datasets enables attribute customization, existing methods suffer from Semantic Pollution that compromises the original model's behavior and prevents incremental learning. To address this, we propose SPF-Portrait, a pioneering work to purely understand customized semantics while eliminating semantic pollution in text-driven portrait customization. In our SPF-Portrait, we propose a dual-path pipeline that introduces the original model as a reference for the conventional fine-tuning path. Through contrastive learning, we ensure adaptation to target attributes and purposefully align other unrelated attributes with the original portrait. We introduce a novel Semantic-Aware Fine Control Map, which represents the precise response regions of the target semantics, to spatially guide the alignment process between the contrastive paths. This alignment process not only effectively preserves the performance of the original model but also avoids over-alignment. Furthermore, we propose a novel response enhancement mechanism to reinforce the performance of target attributes, while mitigating representation discrepancy inherent in direct cross-modal supervision. Extensive experiments demonstrate that SPF-Portrait achieves state-of-the-art performance.
HumanAesExpert: Advancing a Multi-Modality Foundation Model for Human Image Aesthetic Assessment
Mar 31, 2025



Image Aesthetic Assessment (IAA) is a long-standing and challenging research task. However, its subset, Human Image Aesthetic Assessment (HIAA), has been scarcely explored, even though HIAA is widely used in social media, AI workflows, and related domains. To bridge this research gap, our work pioneers a holistic implementation framework tailored for HIAA. Specifically, we introduce HumanBeauty, the first dataset purpose-built for HIAA, which comprises 108k high-quality human images with manual annotations. To achieve comprehensive and fine-grained HIAA, 50K human images are manually collected through a rigorous curation process and annotated leveraging our trailblazing 12-dimensional aesthetic standard, while the remaining 58K with overall aesthetic labels are systematically filtered from public datasets. Based on the HumanBeauty database, we propose HumanAesExpert, a powerful Vision Language Model for aesthetic evaluation of human images. We innovatively design an Expert head to incorporate human knowledge of aesthetic sub-dimensions while jointly utilizing the Language Modeling (LM) and Regression head. This approach empowers our model to achieve superior proficiency in both overall and fine-grained HIAA. Furthermore, we introduce a MetaVoter, which aggregates scores from all three heads, to effectively balance the capabilities of each head, thereby realizing improved assessment precision. Extensive experiments demonstrate that our HumanAesExpert models deliver significantly better performance in HIAA than other state-of-the-art models. Our datasets, models, and codes are publicly released to advance the HIAA community. Project webpage: https://humanaesexpert.github.io/HumanAesExpert/
Constraint Learning for Parametric Point Cloud
Nov 12, 2024



Parametric point clouds are sampled from CAD shapes, have become increasingly prevalent in industrial manufacturing. However, most existing point cloud learning methods focus on the geometric features, such as local and global features or developing efficient convolution operations, overlooking the important attribute of constraints inherent in CAD shapes, which limits these methods' ability to fully comprehend CAD shapes. To address this issue, we analyzed the effect of constraints, and proposed its deep learning-friendly representation, after that, the Constraint Feature Learning Network (CstNet) is developed to extract and leverage constraints. Our CstNet includes two stages. The Stage 1 extracts constraints from B-Rep data or point cloud. The Stage 2 leverages coordinates and constraints to enhance the comprehend of CAD shapes. Additionally, we built up the Parametric 20,000 Multi-modal Dataset for the scarcity of labeled B-Rep datasets. Experiments demonstrate that our CstNet achieved state-of-the-art performance on both public and proposed CAD shapes datasets. To the best of our knowledge, CstNet is the first constraint-based learning method tailored for CAD shapes analysis.
Freehand Sketch Generation from Mechanical Components
Aug 12, 2024



Drawing freehand sketches of mechanical components on multimedia devices for AI-based engineering modeling has become a new trend. However, its development is being impeded because existing works cannot produce suitable sketches for data-driven research. These works either generate sketches lacking a freehand style or utilize generative models not originally designed for this task resulting in poor effectiveness. To address this issue, we design a two-stage generative framework mimicking the human sketching behavior pattern, called MSFormer, which is the first time to produce humanoid freehand sketches tailored for mechanical components. The first stage employs Open CASCADE technology to obtain multi-view contour sketches from mechanical components, filtering perturbing signals for the ensuing generation process. Meanwhile, we design a view selector to simulate viewpoint selection tasks during human sketching for picking out information-rich sketches. The second stage translates contour sketches into freehand sketches by a transformer-based generator. To retain essential modeling features as much as possible and rationalize stroke distribution, we introduce a novel edge-constraint stroke initialization. Furthermore, we utilize a CLIP vision encoder and a new loss function incorporating the Hausdorff distance to enhance the generalizability and robustness of the model. Extensive experiments demonstrate that our approach achieves state-of-the-art performance for generating freehand sketches in the mechanical domain. Project page: https://mcfreeskegen.github.io .
Reinforcement Learning Based Pushing and Grasping Objects from Ungraspable Poses
Feb 26, 2023Grasping an object when it is in an ungraspable pose is a challenging task, such as books or other large flat objects placed horizontally on a table. Inspired by human manipulation, we address this problem by pushing the object to the edge of the table and then grasping it from the hanging part. In this paper, we develop a model-free Deep Reinforcement Learning framework to synergize pushing and grasping actions. We first pre-train a Variational Autoencoder to extract high-dimensional features of input scenario images. One Proximal Policy Optimization algorithm with the common reward and sharing layers of Actor-Critic is employed to learn both pushing and grasping actions with high data efficiency. Experiments show that our one network policy can converge 2.5 times faster than the policy using two parallel networks. Moreover, the experiments on unseen objects show that our policy can generalize to the challenging case of objects with curved surfaces and off-center irregularly shaped objects. Lastly, our policy can be transferred to a real robot without fine-tuning by using CycleGAN for domain adaption and outperforms the push-to-wall baseline.