 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Video Generation with Human Feedback
Jan 23, 2025



Video generation has achieved significant advances through rectified flow techniques, but issues like unsmooth motion and misalignment between videos and prompts persist. In this work, we develop a systematic pipeline that harnesses human feedback to mitigate these problems and refine the video generation model. Specifically, we begin by constructing a large-scale human preference dataset focused on modern video generation models, incorporating pairwise annotations across multi-dimensions. We then introduce VideoReward, a multi-dimensional video reward model, and examine how annotations and various design choices impact its rewarding efficacy. From a unified reinforcement learning perspective aimed at maximizing reward with KL regularization, we introduce three alignment algorithms for flow-based models by extending those from diffusion models. These include two training-time strategies: direct preference optimization for flow (Flow-DPO) and reward weighted regression for flow (Flow-RWR), and an inference-time technique, Flow-NRG, which applies reward guidance directly to noisy videos. Experimental results indicate that VideoReward significantly outperforms existing reward models, and Flow-DPO demonstrates superior performance compared to both Flow-RWR and standard supervised fine-tuning methods. Additionally, Flow-NRG lets users assign custom weights to multiple objectives during inference, meeting personalized video quality needs. Project page: https://gongyeliu.github.io/videoalign.
CMC-Bench: Towards a New Paradigm of Visual Signal Compression
Jun 13, 2024



Ultra-low bitrate image compression is a challenging and demanding topic. With the development of Large Multimodal Models (LMMs), a Cross Modality Compression (CMC) paradigm of Image-Text-Image has emerged. Compared with traditional codecs, this semantic-level compression can reduce image data size to 0.1\% or even lower, which has strong potential applications. However, CMC has certain defects in consistency with the original image and perceptual quality. To address this problem, we introduce CMC-Bench, a benchmark of the cooperative performance of Image-to-Text (I2T) and Text-to-Image (T2I) models for image compression. This benchmark covers 18,000 and 40,000 images respectively to verify 6 mainstream I2T and 12 T2I models, including 160,000 subjective preference scores annotated by human experts. At ultra-low bitrates, this paper proves that the combination of some I2T and T2I models has surpassed the most advanced visual signal codecs; meanwhile, it highlights where LMMs can be further optimized toward the compression task. We encourage LMM developers to participate in this test to promote the evolution of visual signal codec protocols.
NTIRE 2024 Quality Assessment of AI-Generated Content Challenge
Apr 25, 2024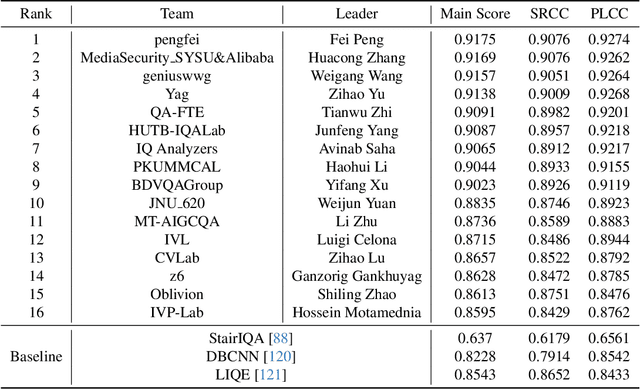
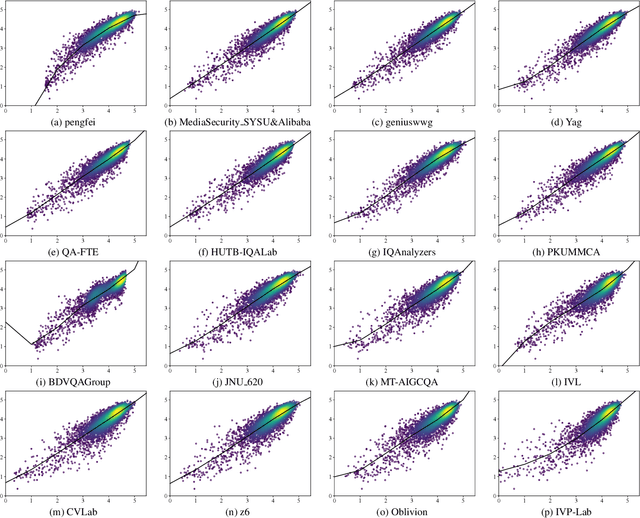
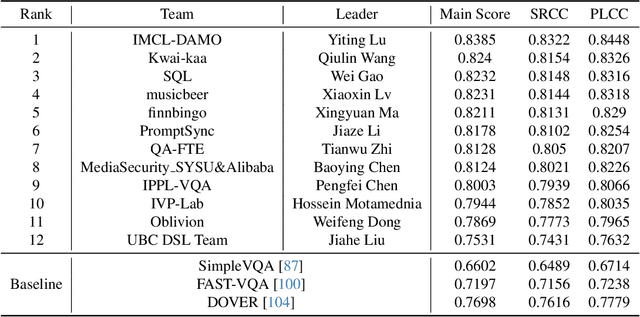
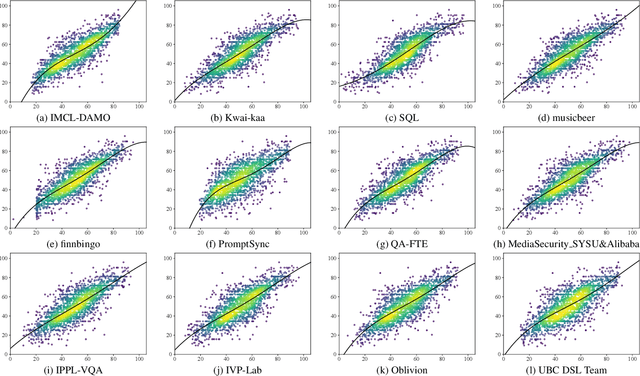
This paper reports on the NTIRE 2024 Quality Assessment of AI-Generated Content Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2024. This challenge is to address a major challenge in the field of image and video processing, namely, Image Quality Assessment (IQA) and Video Quality Assessment (VQA) for AI-Generated Content (AIGC). The challenge is divided into the image track and the video track. The image track uses the AIGIQA-20K, which contains 20,000 AI-Generated Images (AIGIs) generated by 15 popular generative models. The image track has a total of 318 registered participants. A total of 1,646 submissions are received in the development phase, and 221 submissions are received in the test phase. Finally, 16 participating teams submitted their models and fact sheets. The video track uses the T2VQA-DB, which contains 10,000 AI-Generated Videos (AIGVs) generated by 9 popular Text-to-Video (T2V) models. A total of 196 participants have registered in the video track. A total of 991 submissions are received in the development phase, and 185 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. Some methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on AIGC.