 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Eval-100K: Evaluating Visual Quality and Alignment Level for Text-to-Vision Content
Mar 05, 2025Evaluating text-to-vision content hinges on two crucial aspects: visual quality and alignment. While significant progress has been made in developing objective models to assess these dimensions, the performance of such models heavily relies on the scale and quality of human annotations. According to Scaling Law, increasing the number of human-labeled instances follows a predictable pattern that enhances the performance of evaluation models. Therefore, we introduce a comprehensive dataset designed to Evaluate Visual quality and Alignment Level for text-to-vision content (Q-EVAL-100K), featuring the largest collection of human-labeled Mean Opinion Scores (MOS) for the mentioned two aspects. The Q-EVAL-100K dataset encompasses both text-to-image and text-to-video models, with 960K human annotations specifically focused on visual quality and alignment for 100K instances (60K images and 40K videos). Leveraging this dataset with context prompt, we propose Q-Eval-Score, a unified model capable of evaluating both visual quality and alignment with special improvements for handling long-text prompt alignment. Experimental results indicate that the proposed Q-Eval-Score achieves superior performance on both visual quality and alignment, with strong generalization capabilities across other benchmarks. These findings highlight the significant value of the Q-EVAL-100K dataset. Data and codes will be available at https://github.com/zzc-1998/Q-Eval.
Light-VQA+: A Video Quality Assessment Model for Exposure Correction with Vision-Language Guidance
May 06, 2024



Recently, User-Generated Content (UGC) videos have gained popularity in our daily lives. However, UGC videos often suffer from poor exposure due to the limitations of photographic equipment and techniques. Therefore, Video Exposure Correction (VEC) algorithms have been proposed, Low-Light Video Enhancement (LLVE) and Over-Exposed Video Recovery (OEVR) included. Equally important to the VEC is the Video Quality Assessment (VQA). Unfortunately, almost all existing VQA models are built generally, measuring the quality of a video from a comprehensive perspective. As a result, Light-VQA, trained on LLVE-QA, is proposed for assessing LLVE. We extend the work of Light-VQA by expanding the LLVE-QA dataset into Video Exposure Correction Quality Assessment (VEC-QA) dataset with over-exposed videos and their corresponding corrected versions. In addition, we propose Light-VQA+, a VQA model specialized in assessing VEC. Light-VQA+ differs from Light-VQA mainly from the usage of the CLIP model and the vision-language guidance during the feature extraction, followed by a new module referring to the Human Visual System (HVS) for more accurate assessment. Extensive experimental results show that our model achieves the best performance against the current State-Of-The-Art (SOTA) VQA models on the VEC-QA dataset and other public datasets.
NTIRE 2024 Quality Assessment of AI-Generated Content Challenge
Apr 25, 2024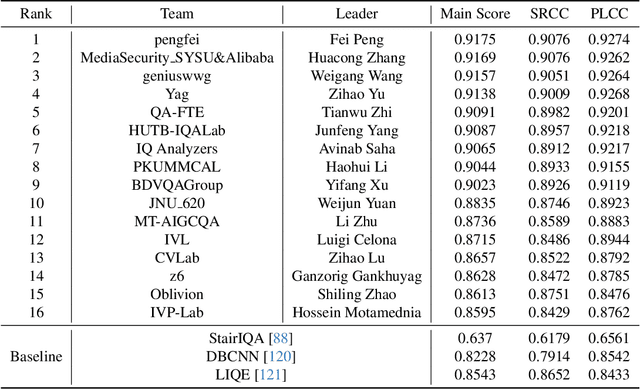
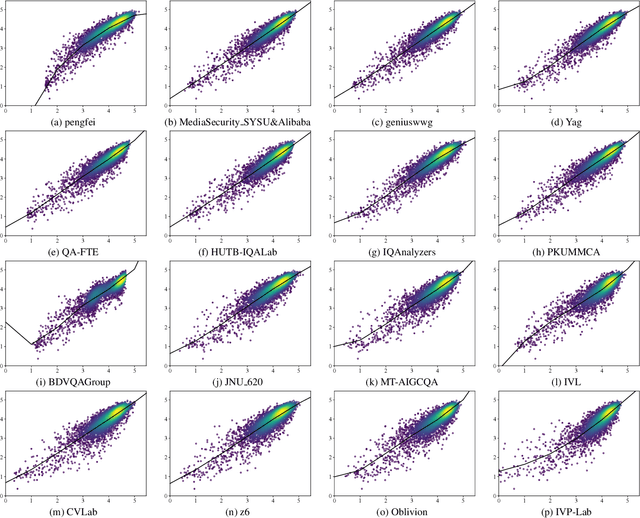
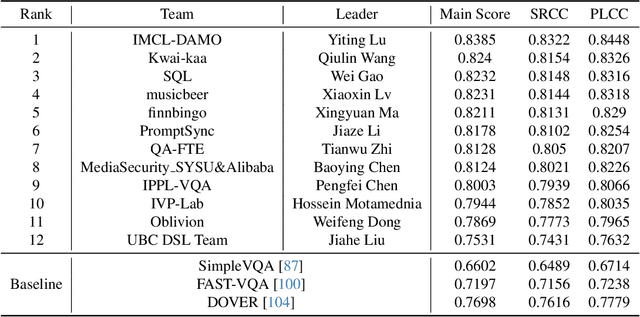
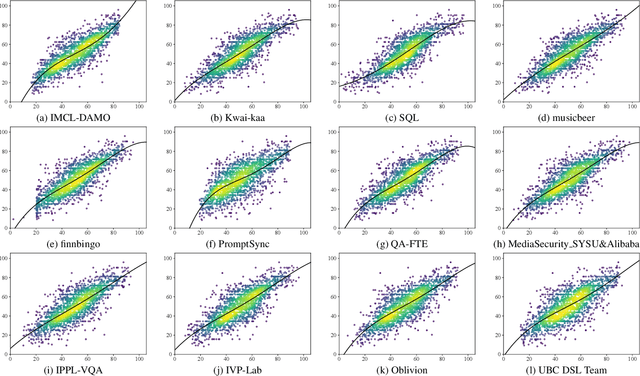
This paper reports on the NTIRE 2024 Quality Assessment of AI-Generated Content Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2024. This challenge is to address a major challenge in the field of image and video processing, namely, Image Quality Assessment (IQA) and Video Quality Assessment (VQA) for AI-Generated Content (AIGC). The challenge is divided into the image track and the video track. The image track uses the AIGIQA-20K, which contains 20,000 AI-Generated Images (AIGIs) generated by 15 popular generative models. The image track has a total of 318 registered participants. A total of 1,646 submissions are received in the development phase, and 221 submissions are received in the test phase. Finally, 16 participating teams submitted their models and fact sheets. The video track uses the T2VQA-DB, which contains 10,000 AI-Generated Videos (AIGVs) generated by 9 popular Text-to-Video (T2V) models. A total of 196 participants have registered in the video track. A total of 991 submissions are received in the development phase, and 185 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. Some methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on AIGC.
AIGIQA-20K: A Large Database for AI-Generated Image Quality Assessment
Apr 04, 2024



With the rapid advancements in AI-Generated Content (AIGC), AI-Generated Images (AIGIs) have been widely applied in entertainment, education, and social media. However, due to the significant variance in quality among different AIGIs, there is an urgent need for models that consistently match human subjective ratings. To address this issue, we organized a challenge towards AIGC quality assessment on NTIRE 2024 that extensively considers 15 popular generative models, utilizing dynamic hyper-parameters (including classifier-free guidance, iteration epochs, and output image resolution), and gather subjective scores that consider perceptual quality and text-to-image alignment altogether comprehensively involving 21 subjects. This approach culminates in the creation of the largest fine-grained AIGI subjective quality database to date with 20,000 AIGIs and 420,000 subjective ratings, known as AIGIQA-20K. Furthermore, we conduct benchmark experiments on this database to assess the correspondence between 16 mainstream AIGI quality models and human perception. We anticipate that this large-scale quality database will inspire robust quality indicators for AIGIs and propel the evolution of AIGC for vision. The database is released on https://www.modelscope.cn/datasets/lcysyzxdxc/AIGCQA-30K-Image.
Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment
Mar 28, 2024



With the rapid development of generative models, Artificial Intelligence-Generated Contents (AIGC) have exponentially increased in daily lives. Among them, Text-to-Video (T2V) generation has received widespread attention. Though many T2V models have been released for generating high perceptual quality videos, there is still lack of a method to evaluate the quality of these videos quantitatively. To solve this issue, we establish the largest-scale Text-to-Video Quality Assessment DataBase (T2VQA-DB) to date. The dataset is composed of 10,000 videos generated by 9 different T2V models. We also conduct a subjective study to obtain each video's corresponding mean opinion score. Based on T2VQA-DB, we propose a novel transformer-based model for subjective-aligned Text-to-Video Quality Assessment (T2VQA). The model extracts features from text-video alignment and video fidelity perspectives, then it leverages the ability of a large language model to give the prediction score. Experimental results show that T2VQA outperforms existing T2V metrics and SOTA video quality assessment models. Quantitative analysis indicates that T2VQA is capable of giving subjective-align predictions, validating its effectiveness. The dataset and code will be released at https://github.com/QMME/T2VQA.
StableVQA: A Deep No-Reference Quality Assessment Model for Video Stability
Aug 10, 2023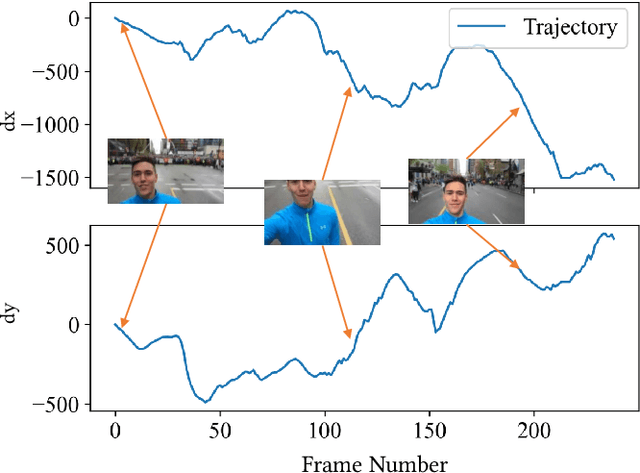
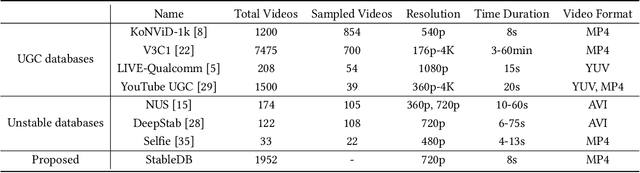

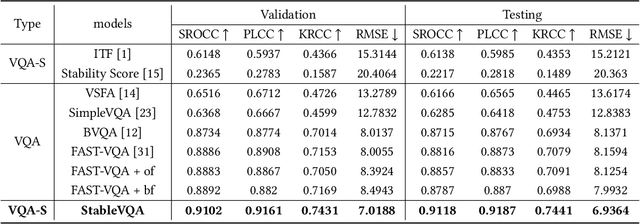
Video shakiness is an unpleasant distortion of User Generated Content (UGC) videos, which is usually caused by the unstable hold of cameras. In recent years, many video stabilization algorithms have been proposed, yet no specific and accurate metric enables comprehensively evaluating the stability of videos. Indeed, most existing quality assessment models evaluate video quality as a whole without specifically taking the subjective experience of video stability into consideration. Therefore, these models cannot measure the video stability explicitly and precisely when severe shakes are present. In addition, there is no large-scale video database in public that includes various degrees of shaky videos with the corresponding subjective scores available, which hinders the development of Video Quality Assessment for Stability (VQA-S). To this end, we build a new database named StableDB that contains 1,952 diversely-shaky UGC videos, where each video has a Mean Opinion Score (MOS) on the degree of video stability rated by 34 subjects. Moreover, we elaborately design a novel VQA-S model named StableVQA, which consists of three feature extractors to acquire the optical flow, semantic, and blur features respectively, and a regression layer to predict the final stability score. Extensive experiments demonstrate that the StableVQA achieves a higher correlation with subjective opinions than the existing VQA-S models and generic VQA models. The database and codes are available at https://github.com/QMME/StableVQA.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
VDPVE: VQA Dataset for Perceptual Video Enhancement
Mar 16, 2023


Recently, many video enhancement methods have been proposed to improve video quality from different aspects such as color, brightness, contrast, and stability. Therefore, how to evaluate the quality of the enhanced video in a way consistent with human visual perception is an important research topic. However, most video quality assessment methods mainly calculate video quality by estimating the distortion degrees of videos from an overall perspective. Few researchers have specifically proposed a video quality assessment method for video enhancement, and there is also no comprehensive video quality assessment dataset available in public. Therefore, we construct a Video quality assessment dataset for Perceptual Video Enhancement (VDPVE) in this paper. The VDPVE has 1211 videos with different enhancements, which can be divided into three sub-datasets: the first sub-dataset has 600 videos with color, brightness, and contrast enhancements; the second sub-dataset has 310 videos with deblurring; and the third sub-dataset has 301 deshaked videos. We invited 21 subjects (20 valid subjects) to rate all enhanced videos in the VDPVE. After normalizing and averaging the subjective opinion scores, the mean opinion score of each video can be obtained. Furthermore, we split the VDPVE into a training set, a validation set, and a test set, and verify the performance of several state-of-the-art video quality assessment methods on the test set of the VDPVE.