 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Characterizing Scientific Image Utility and Upgradability
Jun 02, 2026Scientific images function as critical evidence in research communication, yet their integrity faces unprecedented threats from AI-generated content that introduces subtle but consequential errors. Existing evaluation paradigms prove inadequate: perceptual quality metrics poorly correlate with scientific validity, while language models lack domain-specific verification capabilities. To address this gap, we propose the \textbf{S}cientific \textbf{I}mage \textbf{U}tility and \textbf{U}pgradability \textbf{A}ssessment (\textbf{SIU$^2$A}) framework, which introduces two complementary dimensions for scientific image evaluation. \textbf{Utility} encompasses \textit{error detection} (identifying scientific inaccuracies) and \textit{correction feasibility} (assessing whether errors can be reliably repaired). \textbf{Upgradability} measures the quality of correction. We categorize scientific image corruption into four fundamental types: Detail Distortion, Incompleteness, False Content, and Entity Confusion. Based on this taxonomy, we construct SIU$^2$A-Benchmark, a dataset with expert annotations for error identification and repair. The framework implements a two-stage evaluation protocol: the \textit{Utility} stage evaluates error detection capability and repair instruction generation, while the \textit{Upgradability} stage assesses whether corrections faithfully restore scientific validity without compromising existing accurate information. Experiments reveal that current multimodal systems exhibit significant limitations in both scientific error assessment and faithful correction, exposing a fundamental gap between visual perception and scientific usability.
GeoR-Bench: Evaluating Geoscience Visual Reasoning
May 12, 2026Geoscience intelligence is expected to understand, reason about, and predict earth system changes to support human decision-making in critical domains such as disaster response, climate adaptation and environmental protection. Although current research has shown promising progress on specific geoscience tasks, such as remote sensing interpretation, geographic question-answering, existing benchmarks remain largely task-specific which failing to capture the open-ended real world geoscience problems. As a result, it remains unclear how far current AI systems are from achieving genuine geoscience intelligence. To address this gap, we present \textbf{GeoR-Bench}, a \underline{Bench}mark for evaluating \underline{Geo}science visual \underline{R}easoning through reasoning informed visual editing tasks. GeoR-Bench contains 440 curated samples spanning 6 geoscience categories and 24 task types, covering earth observation imagery and structured scientific representations such as maps and diagrams. We evaluate outputs along three dimensions, including reasoning, consistency, and quality. Benchmark results of 21 closed- and open-source multimodal models reveal that geoscience reasoning remains a critical bottleneck. The highest-performing model achieves 42.7\% overall strict accuracy, while the best open-source models only get 10.3\%. Notably, the visual consistency and image quality of the outputs frequently surpass their scientific accuracy. Ultimately, these findings indicate that current models generate superficially plausible results but fail to capture underlying earth science processes.
MirrorBench: Evaluating Self-centric Intelligence in MLLMs by Introducing a Mirror
Apr 16, 2026Recent progress in Multimodal Large Language Models (MLLMs) has demonstrated remarkable advances in perception and reasoning, suggesting their potential for embodied intelligence. While recent studies have evaluated embodied MLLMs in interactive settings, current benchmarks mainly target capabilities to perceive, understand, and interact with external objects, lacking a systematic evaluation of self-centric intelligence. To address this, we introduce MirrorBench, a simulation-based benchmark inspired by the classical Mirror Self-Recognition (MSR) test in psychology. MirrorBench extends this paradigm to embodied MLLMs through a tiered framework of progressively challenging tasks, assessing agents from basic visual perception to high-level self-representation. Experiments on leading MLLMs show that even at the lowest level, their performance remains substantially inferior to human performance, revealing fundamental limitations in self-referential understanding. Our study bridges psychological paradigms and embodied intelligence, offering a principled framework for evaluating the emergence of general intelligence in large models. Project page: https://fflahm.github.io/mirror-bench-page/.
SafeSci: Safety Evaluation of Large Language Models in Science Domains and Beyond
Mar 02, 2026The success of large language models (LLMs) in scientific domains has heightened safety concerns, prompting numerous benchmarks to evaluate their scientific safety. Existing benchmarks often suffer from limited risk coverage and a reliance on subjective evaluation. To address these problems, we introduce SafeSci, a comprehensive framework for safety evaluation and enhancement in scientific contexts. SafeSci comprises SafeSciBench, a multi-disciplinary benchmark with 0.25M samples, and SafeSciTrain, a large-scale dataset containing 1.5M samples for safety enhancement. SafeSciBench distinguishes between safety knowledge and risk to cover extensive scopes and employs objective metrics such as deterministically answerable questions to mitigate evaluation bias. We evaluate 24 advanced LLMs, revealing critical vulnerabilities in current models. We also observe that LLMs exhibit varying degrees of excessive refusal behaviors on safety-related issues. For safety enhancement, we demonstrate that fine-tuning on SafeSciTrain significantly enhances the safety alignment of models. Finally, we argue that knowledge is a double-edged sword, and determining the safety of a scientific question should depend on specific context, rather than universally categorizing it as safe or unsafe. Our work provides both a diagnostic tool and a practical resource for building safer scientific AI systems.
STAR : Bridging Statistical and Agentic Reasoning for Large Model Performance Prediction
Feb 12, 2026As comprehensive large model evaluation becomes prohibitively expensive, predicting model performance from limited observations has become essential. However, existing statistical methods struggle with pattern shifts, data sparsity, and lack of explanation, while pure LLM methods remain unreliable. We propose STAR, a framework that bridges data-driven STatistical expectations with knowledge-driven Agentic Reasoning. STAR leverages specialized retrievers to gather external knowledge and embeds semantic features into Constrained Probabilistic Matrix Factorization (CPMF) to generate statistical expectations with uncertainty. A reasoning module guided by Expectation Violation Theory (EVT) then refines predictions through intra-family analysis, cross-model comparison, and credibility-aware aggregation, producing adjustments with traceable explanations. Extensive experiments show that STAR consistently outperforms all baselines on both score-based and rank-based metrics, delivering a 14.46% gain in total score over the strongest statistical method under extreme sparsity, with only 1--2 observed scores per test model.
Free-GVC: Towards Training-Free Extreme Generative Video Compression with Temporal Coherence
Feb 10, 2026Building on recent advances in video generation, generative video compression has emerged as a new paradigm for achieving visually pleasing reconstructions. However, existing methods exhibit limited exploitation of temporal correlations, causing noticeable flicker and degraded temporal coherence at ultra-low bitrates. In this paper, we propose Free-GVC, a training-free generative video compression framework that reformulates video coding as latent trajectory compression guided by a video diffusion prior. Our method operates at the group-of-pictures (GOP) level, encoding video segments into a compact latent space and progressively compressing them along the diffusion trajectory. To ensure perceptually consistent reconstruction across GOPs, we introduce an Adaptive Quality Control module that dynamically constructs an online rate-perception surrogate model to predict the optimal diffusion step for each GOP. In addition, an Inter-GOP Alignment module establishes frame overlap and performs latent fusion between adjacent groups, thereby mitigating flicker and enhancing temporal coherence. Experiments show that Free-GVC achieves an average of 93.29% BD-Rate reduction in DISTS over the latest neural codec DCVC-RT, and a user study further confirms its superior perceptual quality and temporal coherence at ultra-low bitrates.
Automated Safety Benchmarking: A Multi-agent Pipeline for LVLMs
Jan 27, 2026Large vision-language models (LVLMs) exhibit remarkable capabilities in cross-modal tasks but face significant safety challenges, which undermine their reliability in real-world applications. Efforts have been made to build LVLM safety evaluation benchmarks to uncover their vulnerability. However, existing benchmarks are hindered by their labor-intensive construction process, static complexity, and limited discriminative power. Thus, they may fail to keep pace with rapidly evolving models and emerging risks. To address these limitations, we propose VLSafetyBencher, the first automated system for LVLM safety benchmarking. VLSafetyBencher introduces four collaborative agents: Data Preprocessing, Generation, Augmentation, and Selection agents to construct and select high-quality samples. Experiments validates that VLSafetyBencher can construct high-quality safety benchmarks within one week at a minimal cost. The generated benchmark effectively distinguish safety, with a safety rate disparity of 70% between the most and least safe models.
Embodied Image Compression
Dec 12, 2025
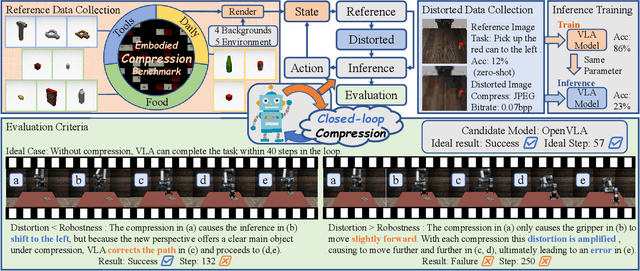
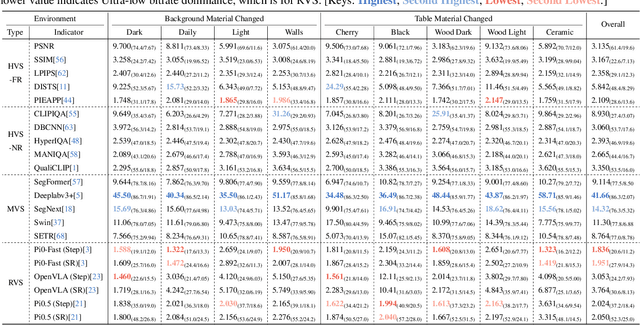
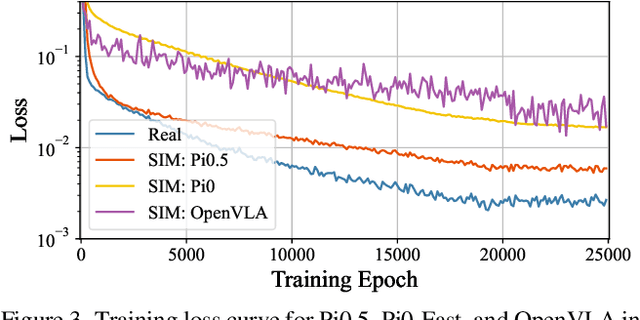
Image Compression for Machines (ICM) has emerged as a pivotal research direction in the field of visual data compression. However, with the rapid evolution of machine intelligence, the target of compression has shifted from task-specific virtual models to Embodied agents operating in real-world environments. To address the communication constraints of Embodied AI in multi-agent systems and ensure real-time task execution, this paper introduces, for the first time, the scientific problem of Embodied Image Compression. We establish a standardized benchmark, EmbodiedComp, to facilitate systematic evaluation under ultra-low bitrate conditions in a closed-loop setting. Through extensive empirical studies in both simulated and real-world settings, we demonstrate that existing Vision-Language-Action models (VLAs) fail to reliably perform even simple manipulation tasks when compressed below the Embodied bitrate threshold. We anticipate that EmbodiedComp will catalyze the development of domain-specific compression tailored for Embodied agents , thereby accelerating the Embodied AI deployment in the Real-world.
Using GUI Agent for Electronic Design Automation
Dec 12, 2025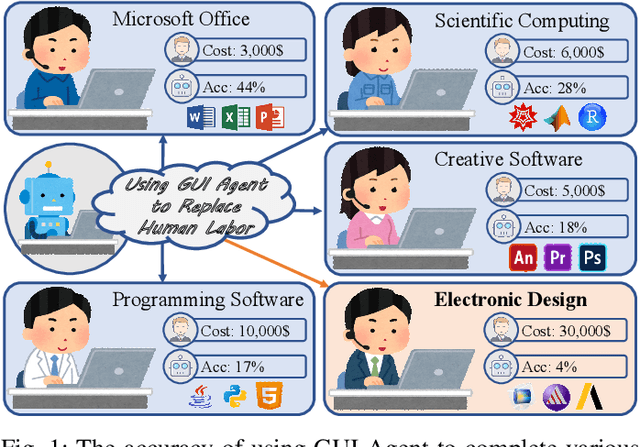
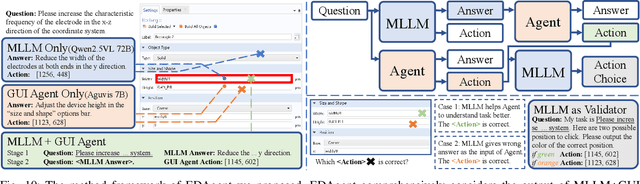
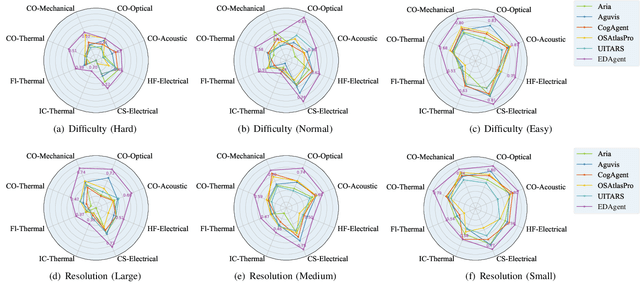
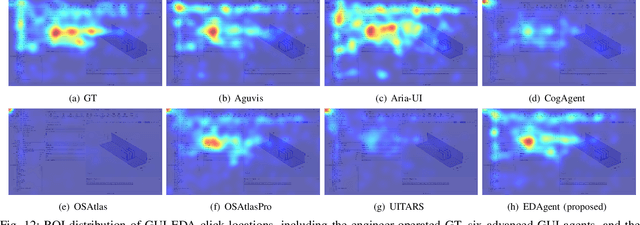
Graphical User Interface (GUI) agents adopt an end-to-end paradigm that maps a screenshot to an action sequence, thereby automating repetitive tasks in virtual environments. However, existing GUI agents are evaluated almost exclusively on commodity software such as Microsoft Word and Excel. Professional Computer-Aided Design (CAD) suites promise an order-of-magnitude higher economic return, yet remain the weakest performance domain for existing agents and are still far from replacing expert Electronic-Design-Automation (EDA) engineers. We therefore present the first systematic study that deploys GUI agents for EDA workflows. Our contributions are: (1) a large-scale dataset named GUI-EDA, including 5 CAD tools and 5 physical domains, comprising 2,000+ high-quality screenshot-answer-action pairs recorded by EDA scientists and engineers during real-world component design; (2) a comprehensive benchmark that evaluates 30+ mainstream GUI agents, demonstrating that EDA tasks constitute a major, unsolved challenge; and (3) an EDA-specialized metric named EDAgent, equipped with a reflection mechanism that achieves reliable performance on industrial CAD software and, for the first time, outperforms Ph.D. students majored in Electrical Engineering. This work extends GUI agents from generic office automation to specialized, high-value engineering domains and offers a new avenue for advancing EDA productivity. The dataset will be released at: https://github.com/aiben-ch/GUI-EDA.
GeoX-Bench: Benchmarking Cross-View Geo-Localization and Pose Estimation Capabilities of Large Multimodal Models
Nov 17, 2025Large multimodal models (LMMs) have demonstrated remarkable capabilities across a wide range of tasks, however their knowledge and abilities in the cross-view geo-localization and pose estimation domains remain unexplored, despite potential benefits for navigation, autonomous driving, outdoor robotics, \textit{etc}. To bridge this gap, we introduce \textbf{GeoX-Bench}, a comprehensive \underline{Bench}mark designed to explore and evaluate the capabilities of LMMs in \underline{cross}-view \underline{Geo}-localization and pose estimation. Specifically, GeoX-Bench contains 10,859 panoramic-satellite image pairs spanning 128 cities in 49 countries, along with corresponding 755,976 question-answering (QA) pairs. Among these, 42,900 QA pairs are designated for benchmarking, while the remaining are intended to enhance the capabilities of LMMs. Based on GeoX-Bench, we evaluate the capabilities of 25 state-of-the-art LMMs on cross-view geo-localization and pose estimation tasks, and further explore the empowered capabilities of instruction-tuning. Our benchmark demonstrate that while current LMMs achieve impressive performance in geo-localization tasks, their effectiveness declines significantly on the more complex pose estimation tasks, highlighting a critical area for future improvement, and instruction-tuning LMMs on the training data of GeoX-Bench can significantly improve the cross-view geo-sense abilities. The GeoX-Bench is available at \textcolor{magenta}{https://github.com/IntMeGroup/GeoX-Bench}.