 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimely Machine: Awareness of Time Makes Test-Time Scaling Agentic
Jan 23, 2026As large language models (LLMs) increasingly tackle complex reasoning tasks, test-time scaling has become critical for enhancing capabilities. However, in agentic scenarios with frequent tool calls, the traditional generation-length-based definition breaks down: tool latency decouples inference time from generation length. We propose Timely Machine, redefining test-time as wall-clock time, where models dynamically adjust strategies based on time budgets. We introduce Timely-Eval, a benchmark spanning high-frequency tool calls, low-frequency tool calls, and time-constrained reasoning. By varying tool latency, we find smaller models excel with fast feedback through more interactions, while larger models dominate high-latency settings via superior interaction quality. Moreover, existing models fail to adapt reasoning to time budgets. We propose Timely-RL to address this gap. After cold-start supervised fine-tuning, we use reinforcement learning to enhance temporal planning. Timely-RL improves time budget awareness and consistently boosts performance across Timely-Eval. We hope our work offers a new perspective on test-time scaling for the agentic era.
TL-GRPO: Turn-Level RL for Reasoning-Guided Iterative Optimization
Jan 23, 2026Large language models have demonstrated strong reasoning capabilities in complex tasks through tool integration, which is typically framed as a Markov Decision Process and optimized with trajectory-level RL algorithms such as GRPO. However, a common class of reasoning tasks, iterative optimization, presents distinct challenges: the agent interacts with the same underlying environment state across turns, and the value of a trajectory is determined by the best turn-level reward rather than cumulative returns. Existing GRPO-based methods cannot perform fine-grained, turn-level optimization in such settings, while black-box optimization methods discard prior knowledge and reasoning capabilities. To address this gap, we propose Turn-Level GRPO (TL-GRPO), a lightweight RL algorithm that performs turn-level group sampling for fine-grained optimization. We evaluate TL-GRPO on analog circuit sizing (ACS), a challenging scientific optimization task requiring multiple simulations and domain expertise. Results show that TL-GRPO outperforms standard GRPO and Bayesian optimization methods across various specifications. Furthermore, our 30B model trained with TL-GRPO achieves state-of-the-art performance on ACS tasks under same simulation budget, demonstrating both strong generalization and practical utility.
OPT-BENCH: Evaluating LLM Agent on Large-Scale Search Spaces Optimization Problems
Jun 12, 2025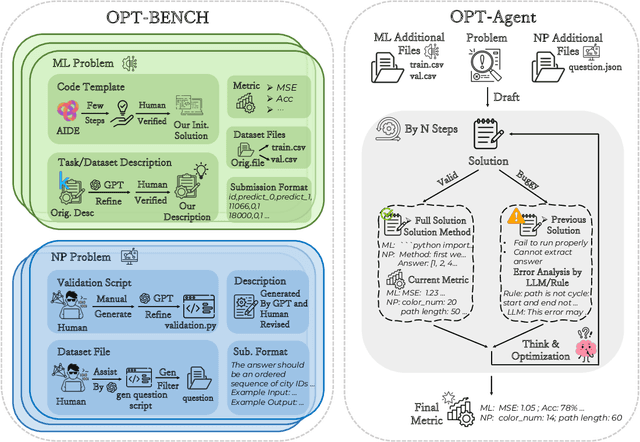


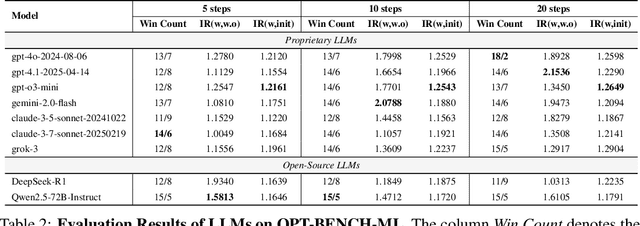
Large Language Models (LLMs) have shown remarkable capabilities in solving diverse tasks. However, their proficiency in iteratively optimizing complex solutions through learning from previous feedback remains insufficiently explored. To bridge this gap, we present OPT-BENCH, a comprehensive benchmark designed to evaluate LLM agents on large-scale search space optimization problems. OPT-BENCH includes 20 real-world machine learning tasks sourced from Kaggle and 10 classical NP problems, offering a diverse and challenging environment for assessing LLM agents on iterative reasoning and solution refinement. To enable rigorous evaluation, we introduce OPT-Agent, an end-to-end optimization framework that emulates human reasoning when tackling complex problems by generating, validating, and iteratively improving solutions through leveraging historical feedback. Through extensive experiments on 9 state-of-the-art LLMs from 6 model families, we analyze the effects of optimization iterations, temperature settings, and model architectures on solution quality and convergence. Our results demonstrate that incorporating historical context significantly enhances optimization performance across both ML and NP tasks. All datasets, code, and evaluation tools are open-sourced to promote further research in advancing LLM-driven optimization and iterative reasoning. Project page: \href{https://github.com/OliverLeeXZ/OPT-BENCH}{https://github.com/OliverLeeXZ/OPT-BENCH}.
Information Density Principle for MLLM Benchmarks
Mar 13, 2025With the emergence of Multimodal Large Language Models (MLLMs), hundreds of benchmarks have been developed to ensure the reliability of MLLMs in downstream tasks. However, the evaluation mechanism itself may not be reliable. For developers of MLLMs, questions remain about which benchmark to use and whether the test results meet their requirements. Therefore, we propose a critical principle of Information Density, which examines how much insight a benchmark can provide for the development of MLLMs. We characterize it from four key dimensions: (1) Fallacy, (2) Difficulty, (3) Redundancy, (4) Diversity. Through a comprehensive analysis of more than 10,000 samples, we measured the information density of 19 MLLM benchmarks. Experiments show that using the latest benchmarks in testing can provide more insight compared to previous ones, but there is still room for improvement in their information density. We hope this principle can promote the development and application of future MLLM benchmarks. Project page: https://github.com/lcysyzxdxc/bench4bench
Can video generation replace cinematographers? Research on the cinematic language of generated video
Dec 16, 2024



Recent advancements in text-to-video (T2V) generation have leveraged diffusion models to enhance the visual coherence of videos generated from textual descriptions. However, most research has primarily focused on object motion, with limited attention given to cinematic language in videos, which is crucial for cinematographers to convey emotion and narrative pacing. To address this limitation, we propose a threefold approach to enhance the ability of T2V models to generate controllable cinematic language. Specifically, we introduce a cinematic language dataset that encompasses shot framing, angle, and camera movement, enabling models to learn diverse cinematic styles. Building on this, to facilitate robust cinematic alignment evaluation, we present CameraCLIP, a model fine-tuned on the proposed dataset that excels in understanding complex cinematic language in generated videos and can further provide valuable guidance in the multi-shot composition process. Finally, we propose CLIPLoRA, a cost-guided dynamic LoRA composition method that facilitates smooth transitions and realistic blending of cinematic language by dynamically fusing multiple pre-trained cinematic LoRAs within a single video. Our experiments demonstrate that CameraCLIP outperforms existing models in assessing the alignment between cinematic language and video, achieving an R@1 score of 0.81. Additionally, CLIPLoRA improves the ability for multi-shot composition, potentially bridging the gap between automatically generated videos and those shot by professional cinematographers.