 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolMem: A Cognitive-Driven Benchmark for Multi-Session Dialogue Memory
Jan 07, 2026Despite recent advances in understanding and leveraging long-range conversational memory, existing benchmarks still lack systematic evaluation of large language models(LLMs) across diverse memory dimensions, particularly in multi-session settings. In this work, we propose EvolMem, a new benchmark for assessing multi-session memory capabilities of LLMs and agent systems. EvolMem is grounded in cognitive psychology and encompasses both declarative and non-declarative memory, further decomposed into multiple fine-grained abilities. To construct the benchmark, we introduce a hybrid data synthesis framework that consists of topic-initiated generation and narrative-inspired transformations. This framework enables scalable generation of multi-session conversations with controllable complexity, accompanied by sample-specific evaluation guidelines. Extensive evaluation reveals that no LLM consistently outperforms others across all memory dimensions. Moreover, agent memory mechanisms do not necessarily enhance LLMs' capabilities and often exhibit notable efficiency limitations. Data and code will be released at https://github.com/shenye7436/EvolMem.
One Battle After Another: Probing LLMs' Limits on Multi-Turn Instruction Following with a Benchmark Evolving Framework
Nov 05, 2025Understanding how well large language models can follow users' instructions throughout a dialogue spanning multiple topics is of great importance for data-intensive conversational applications. Existing benchmarks are often limited to a fixed number of turns, making them susceptible to saturation and failing to account for the user's interactive experience. In this work, we propose an extensible framework for assessing multi-turn instruction-following ability. At its core, our framework decouples linguistic surface forms from user intent simulation through a three-layer mechanism that tracks constraints, instructions, and topics. This framework mimics User-LLM interaction by enabling the dynamic construction of benchmarks with state changes and tracebacks, terminating a conversation only when the model exhausts a simulated user's patience. We define a suite of metrics capturing the quality of the interaction process. Using this framework, we construct EvolIF, an evolving instruction-following benchmark incorporating nine distinct constraint types. Our results indicate that GPT-5 exhibits superior instruction-following performance. It sustains an average of 18.54 conversational turns and demonstrates 70.31% robustness, outperforming Gemini-2.5-Pro by a significant margin of 11.41%, while other models lag far behind. All of the data and code will be made publicly available online.
Efficiently Learning Synthetic Control Models for High-dimensional Disaggregated Data
Oct 26, 2025The Synthetic Control method (SC) has become a valuable tool for estimating causal effects. Originally designed for single-treated unit scenarios, it has recently found applications in high-dimensional disaggregated settings with multiple treated units. However, challenges in practical implementation and computational efficiency arise in such scenarios. To tackle these challenges, we propose a novel approach that integrates the Multivariate Square-root Lasso method into the synthetic control framework. We rigorously establish the estimation error bounds for fitting the Synthetic Control weights using Multivariate Square-root Lasso, accommodating high-dimensionality and time series dependencies. Additionally, we quantify the estimation error for the Average Treatment Effect on the Treated (ATT). Through simulation studies, we demonstrate that our method offers superior computational efficiency without compromising estimation accuracy. We apply our method to assess the causal impact of COVID-19 Stay-at-Home Orders on the monthly unemployment rate in the United States at the county level.
A Multi-To-One Interview Paradigm for Efficient MLLM Evaluation
Sep 18, 2025The rapid progress of Multi-Modal Large Language Models (MLLMs) has spurred the creation of numerous benchmarks. However, conventional full-coverage Question-Answering evaluations suffer from high redundancy and low efficiency. Inspired by human interview processes, we propose a multi-to-one interview paradigm for efficient MLLM evaluation. Our framework consists of (i) a two-stage interview strategy with pre-interview and formal interview phases, (ii) dynamic adjustment of interviewer weights to ensure fairness, and (iii) an adaptive mechanism for question difficulty-level chosen. Experiments on different benchmarks show that the proposed paradigm achieves significantly higher correlation with full-coverage results than random sampling, with improvements of up to 17.6% in PLCC and 16.7% in SRCC, while reducing the number of required questions. These findings demonstrate that the proposed paradigm provides a reliable and efficient alternative for large-scale MLLM benchmarking.
The Ever-Evolving Science Exam
Jul 22, 2025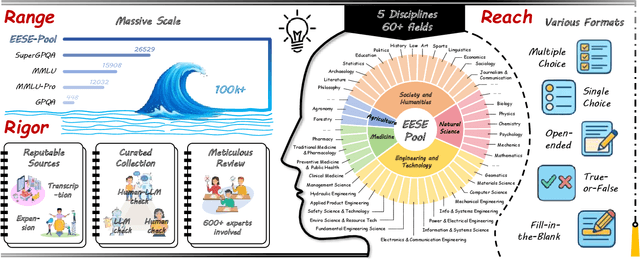
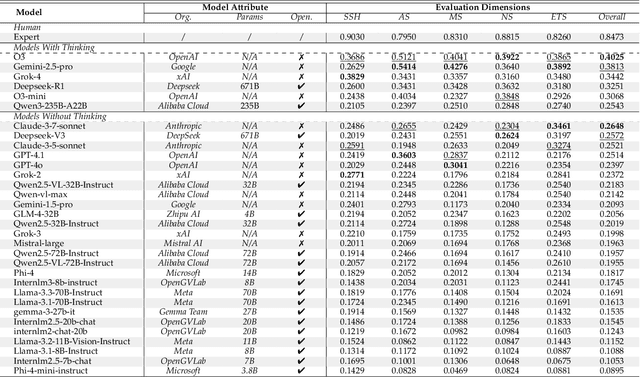
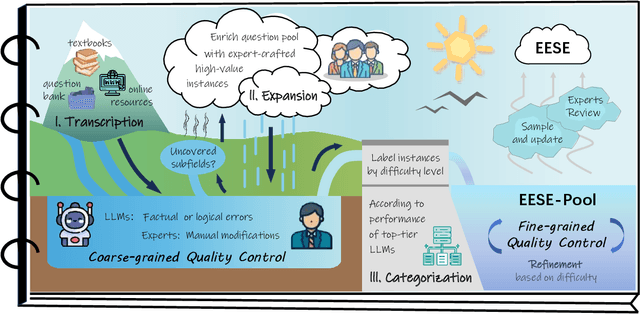
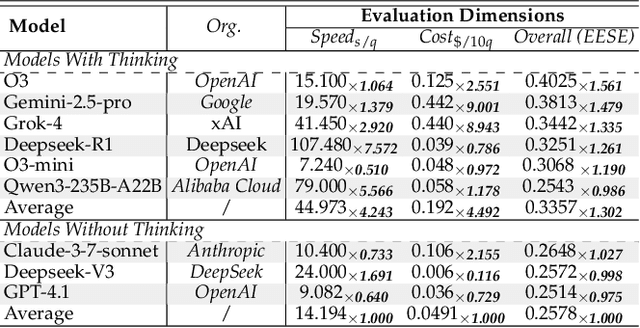
As foundation models grow rapidly in capability and deployment, evaluating their scientific understanding becomes increasingly critical. Existing science benchmarks have made progress towards broad **Range**, wide **Reach**, and high **Rigor**, yet they often face two major challenges: **data leakage risks** that compromise benchmarking validity, and **evaluation inefficiency** due to large-scale testing. To address these issues, we introduce the **Ever-Evolving Science Exam (EESE)**, a dynamic benchmark designed to reliably assess scientific capabilities in foundation models. Our approach consists of two components: 1) a non-public **EESE-Pool** with over 100K expertly constructed science instances (question-answer pairs) across 5 disciplines and 500+ subfields, built through a multi-stage pipeline ensuring **Range**, **Reach**, and **Rigor**, 2) a periodically updated 500-instance subset **EESE**, sampled and validated to enable leakage-resilient, low-overhead evaluations. Experiments on 32 open- and closed-source models demonstrate that EESE effectively differentiates the strengths and weaknesses of models in scientific fields and cognitive dimensions. Overall, EESE provides a robust, scalable, and forward-compatible solution for science benchmark design, offering a realistic measure of how well foundation models handle science questions. The project page is at: https://github.com/aiben-ch/EESE.
When Life Gives You Samples: The Benefits of Scaling up Inference Compute for Multilingual LLMs
Jun 25, 2025Recent advancements in large language models (LLMs) have shifted focus toward scaling inference-time compute, improving performance without retraining the model. A common approach is to sample multiple outputs in parallel, and select one of these as the final output. However, work to date has focused on English and a handful of domains such as math and code. In contrast, we are most interested in techniques that generalize across open-ended tasks, formally verifiable tasks, and across languages. In this work, we study how to robustly scale inference-time compute for open-ended generative tasks in a multilingual, multi-task setting. Our findings show that both sampling strategy based on temperature variation and selection strategy must be adapted to account for diverse domains and varied language settings. We evaluate existing selection methods, revealing that strategies effective in English often fail to generalize across languages. We propose novel sampling and selection strategies specifically adapted for multilingual and multi-task inference scenarios, and show they yield notable gains across languages and tasks. In particular, our combined sampling and selection methods lead to an average +6.8 jump in win-rates for our 8B models on m-ArenaHard-v2.0 prompts, against proprietary models such as Gemini. At larger scale, Command-A (111B model) equipped with our methods, shows +9.0 improvement in win-rates on the same benchmark with just five samples against single-sample decoding, a substantial increase at minimal cost. Our results underscore the need for language- and task-aware approaches to inference-time compute, aiming to democratize performance improvements in underrepresented languages.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Large Language Models for Bioinformatics
Jan 10, 2025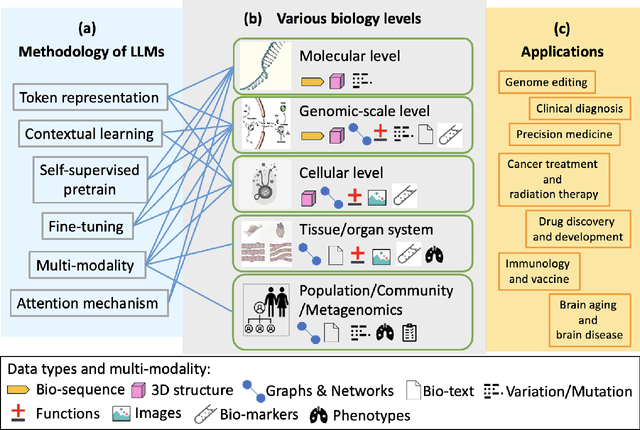
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.
PharmacyGPT: The AI Pharmacist
Jul 21, 2023In this study, we introduce PharmacyGPT, a novel framework to assess the capabilities of large language models (LLMs) such as ChatGPT and GPT-4 in emulating the role of clinical pharmacists. Our methodology encompasses the utilization of LLMs to generate comprehensible patient clusters, formulate medication plans, and forecast patient outcomes. We conduct our investigation using real data acquired from the intensive care unit (ICU) at the University of North Carolina Chapel Hill (UNC) Hospital. Our analysis offers valuable insights into the potential applications and limitations of LLMs in the field of clinical pharmacy, with implications for both patient care and the development of future AI-driven healthcare solutions. By evaluating the performance of PharmacyGPT, we aim to contribute to the ongoing discourse surrounding the integration of artificial intelligence in healthcare settings, ultimately promoting the responsible and efficacious use of such technologies.
AD-AutoGPT: An Autonomous GPT for Alzheimer's Disease Infodemiology
Jun 16, 2023



In this pioneering study, inspired by AutoGPT, the state-of-the-art open-source application based on the GPT-4 large language model, we develop a novel tool called AD-AutoGPT which can conduct data collection, processing, and analysis about complex health narratives of Alzheimer's Disease in an autonomous manner via users' textual prompts. We collated comprehensive data from a variety of news sources, including the Alzheimer's Association, BBC, Mayo Clinic, and the National Institute on Aging since June 2022, leading to the autonomous execution of robust trend analyses, intertopic distance maps visualization, and identification of salient terms pertinent to Alzheimer's Disease. This approach has yielded not only a quantifiable metric of relevant discourse but also valuable insights into public focus on Alzheimer's Disease. This application of AD-AutoGPT in public health signifies the transformative potential of AI in facilitating a data-rich understanding of complex health narratives like Alzheimer's Disease in an autonomous manner, setting the groundwork for future AI-driven investigations in global health landscapes.