 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Causal Decision Making
Feb 22, 2025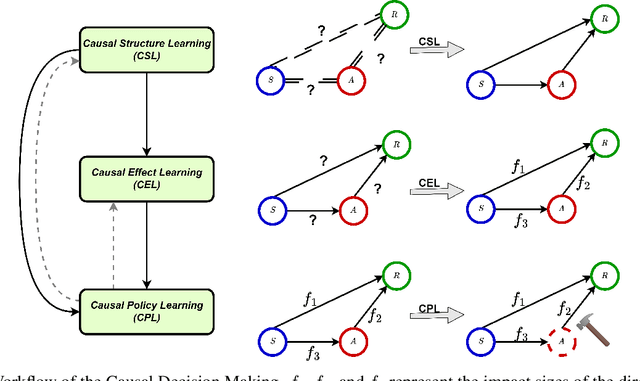

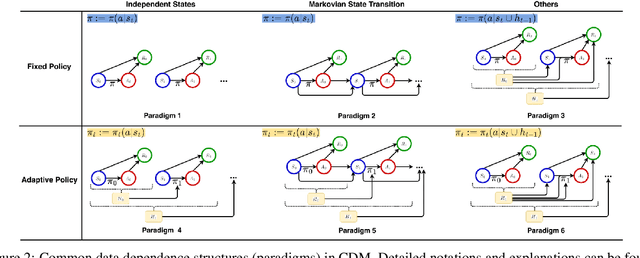
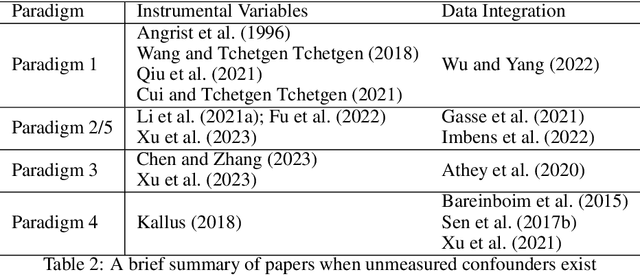
To make effective decisions, it is important to have a thorough understanding of the causal relationships among actions, environments, and outcomes. This review aims to surface three crucial aspects of decision-making through a causal lens: 1) the discovery of causal relationships through causal structure learning, 2) understanding the impacts of these relationships through causal effect learning, and 3) applying the knowledge gained from the first two aspects to support decision making via causal policy learning. Moreover, we identify challenges that hinder the broader utilization of causal decision-making and discuss recent advances in overcoming these challenges. Finally, we provide future research directions to address these challenges and to further enhance the implementation of causal decision-making in practice, with real-world applications illustrated based on the proposed causal decision-making. We aim to offer a comprehensive methodology and practical implementation framework by consolidating various methods in this area into a Python-based collection. URL: https://causaldm.github.io/Causal-Decision-Making.
Zero-Inflated Bandits
Dec 25, 2023



Many real applications of bandits have sparse non-zero rewards, leading to slow learning rates. A careful distribution modeling that utilizes problem-specific structures is known as critical to estimation efficiency in the statistics literature, yet is under-explored in bandits. To fill the gap, we initiate the study of zero-inflated bandits, where the reward is modeled as a classic semi-parametric distribution called zero-inflated distribution. We carefully design Upper Confidence Bound (UCB) and Thompson Sampling (TS) algorithms for this specific structure. Our algorithms are suitable for a very general class of reward distributions, operating under tail assumptions that are considerably less stringent than the typical sub-Gaussian requirements. Theoretically, we derive the regret bounds for both the UCB and TS algorithms for multi-armed bandit, showing that they can achieve rate-optimal regret when the reward distribution is sub-Gaussian. The superior empirical performance of the proposed methods is shown via extensive numerical studies.
Effect Size Estimation for Duration Recommendation in Online Experiments: Leveraging Hierarchical Models and Objective Utility Approaches
Dec 20, 2023The selection of the assumed effect size (AES) critically determines the duration of an experiment, and hence its accuracy and efficiency. Traditionally, experimenters determine AES based on domain knowledge. However, this method becomes impractical for online experimentation services managing numerous experiments, and a more automated approach is hence of great demand. We initiate the study of data-driven AES selection in for online experimentation services by introducing two solutions. The first employs a three-layer Gaussian Mixture Model considering the heteroskedasticity across experiments, and it seeks to estimate the true expected effect size among positive experiments. The second method, grounded in utility theory, aims to determine the optimal effect size by striking a balance between the experiment's cost and the precision of decision-making. Through comparisons with baseline methods using both simulated and real data, we showcase the superior performance of the proposed approaches.
Robust Offline Policy Evaluation and Optimization with Heavy-Tailed Rewards
Oct 28, 2023This paper endeavors to augment the robustness of offline reinforcement learning (RL) in scenarios laden with heavy-tailed rewards, a prevalent circumstance in real-world applications. We propose two algorithmic frameworks, ROAM and ROOM, for robust off-policy evaluation (OPE) and offline policy optimization (OPO), respectively. Central to our frameworks is the strategic incorporation of the median-of-means method with offline RL, enabling straightforward uncertainty estimation for the value function estimator. This not only adheres to the principle of pessimism in OPO but also adeptly manages heavy-tailed rewards. Theoretical results and extensive experiments demonstrate that our two frameworks outperform existing methods on the logged dataset exhibits heavy-tailed reward distributions.
Experimentation Platforms Meet Reinforcement Learning: Bayesian Sequential Decision-Making for Continuous Monitoring
Apr 02, 2023With the growing needs of online A/B testing to support the innovation in industry, the opportunity cost of running an experiment becomes non-negligible. Therefore, there is an increasing demand for an efficient continuous monitoring service that allows early stopping when appropriate. Classic statistical methods focus on hypothesis testing and are mostly developed for traditional high-stake problems such as clinical trials, while experiments at online service companies typically have very different features and focuses. Motivated by the real needs, in this paper, we introduce a novel framework that we developed in Amazon to maximize customer experience and control opportunity cost. We formulate the problem as a Bayesian optimal sequential decision making problem that has a unified utility function. We discuss extensively practical design choices and considerations. We further introduce how to solve the optimal decision rule via Reinforcement Learning and scale the solution. We show the effectiveness of this novel approach compared with existing methods via a large-scale meta-analysis on experiments in Amazon.
Multiplier Bootstrap-based Exploration
Feb 03, 2023Despite the great interest in the bandit problem, designing efficient algorithms for complex models remains challenging, as there is typically no analytical way to quantify uncertainty. In this paper, we propose Multiplier Bootstrap-based Exploration (MBE), a novel exploration strategy that is applicable to any reward model amenable to weighted loss minimization. We prove both instance-dependent and instance-independent rate-optimal regret bounds for MBE in sub-Gaussian multi-armed bandits. With extensive simulation and real data experiments, we show the generality and adaptivity of MBE.
STEEL: Singularity-aware Reinforcement Learning
Jan 31, 2023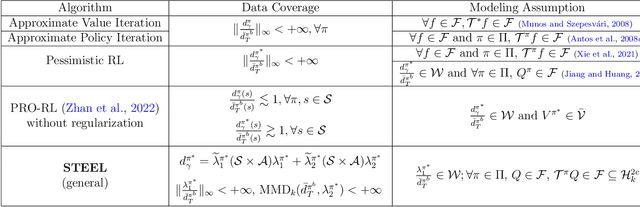
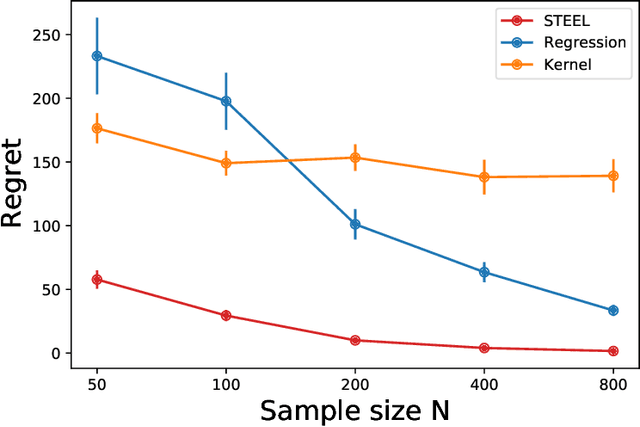
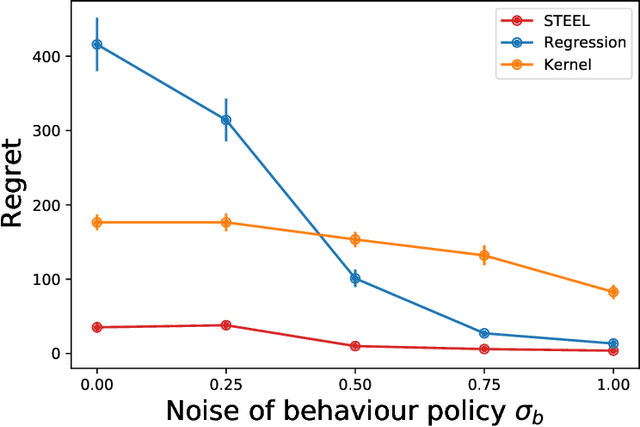

Batch reinforcement learning (RL) aims at finding an optimal policy in a dynamic environment in order to maximize the expected total rewards by leveraging pre-collected data. A fundamental challenge behind this task is the distributional mismatch between the batch data generating process and the distribution induced by target policies. Nearly all existing algorithms rely on the absolutely continuous assumption on the distribution induced by target policies with respect to the data distribution so that the batch data can be used to calibrate target policies via the change of measure. However, the absolute continuity assumption could be violated in practice, especially when the state-action space is large or continuous. In this paper, we propose a new batch RL algorithm without requiring absolute continuity in the setting of an infinite-horizon Markov decision process with continuous states and actions. We call our algorithm STEEL: SingulariTy-awarE rEinforcement Learning. Our algorithm is motivated by a new error analysis on off-policy evaluation, where we use maximum mean discrepancy, together with distributionally robust optimization, to characterize the error of off-policy evaluation caused by the possible singularity and to enable the power of model extrapolation. By leveraging the idea of pessimism and under some mild conditions, we derive a finite-sample regret guarantee for our proposed algorithm without imposing absolute continuity. Compared with existing algorithms, STEEL only requires some minimal data-coverage assumption and thus greatly enhances the applicability and robustness of batch RL. Extensive simulation studies and one real experiment on personalized pricing demonstrate the superior performance of our method when facing possible singularity in batch RL.
Mining the Factor Zoo: Estimation of Latent Factor Models with Sufficient Proxies
Jan 03, 2023Latent factor model estimation typically relies on either using domain knowledge to manually pick several observed covariates as factor proxies, or purely conducting multivariate analysis such as principal component analysis. However, the former approach may suffer from the bias while the latter can not incorporate additional information. We propose to bridge these two approaches while allowing the number of factor proxies to diverge, and hence make the latent factor model estimation robust, flexible, and statistically more accurate. As a bonus, the number of factors is also allowed to grow. At the heart of our method is a penalized reduced rank regression to combine information. To further deal with heavy-tailed data, a computationally attractive penalized robust reduced rank regression method is proposed. We establish faster rates of convergence compared with the benchmark. Extensive simulations and real examples are used to illustrate the advantages.
Heterogeneous Synthetic Learner for Panel Data
Dec 30, 2022



In the new era of personalization, learning the heterogeneous treatment effect (HTE) becomes an inevitable trend with numerous applications. Yet, most existing HTE estimation methods focus on independently and identically distributed observations and cannot handle the non-stationarity and temporal dependency in the common panel data setting. The treatment evaluators developed for panel data, on the other hand, typically ignore the individualized information. To fill the gap, in this paper, we initialize the study of HTE estimation in panel data. Under different assumptions for HTE identifiability, we propose the corresponding heterogeneous one-side and two-side synthetic learner, namely H1SL and H2SL, by leveraging the state-of-the-art HTE estimator for non-panel data and generalizing the synthetic control method that allows flexible data generating process. We establish the convergence rates of the proposed estimators. The superior performance of the proposed methods over existing ones is demonstrated by extensive numerical studies.
Safe Exploration for Efficient Policy Evaluation and Comparison
Feb 26, 2022


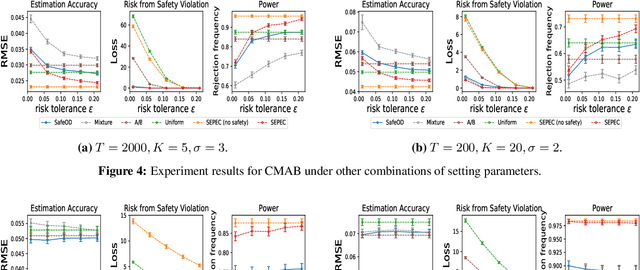
High-quality data plays a central role in ensuring the accuracy of policy evaluation. This paper initiates the study of efficient and safe data collection for bandit policy evaluation. We formulate the problem and investigate its several representative variants. For each variant, we analyze its statistical properties, derive the corresponding exploration policy, and design an efficient algorithm for computing it. Both theoretical analysis and experiments support the usefulness of the proposed methods.