 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEEL: Singularity-aware Reinforcement Learning
Paper and Code
Jan 31, 2023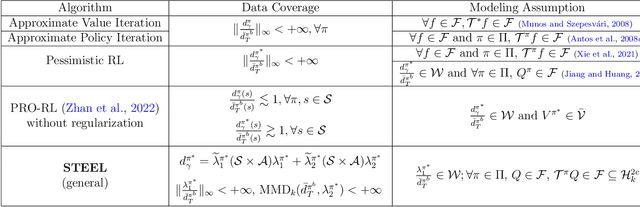
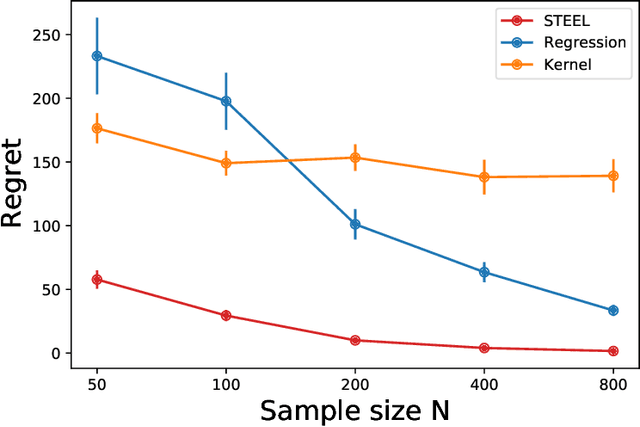
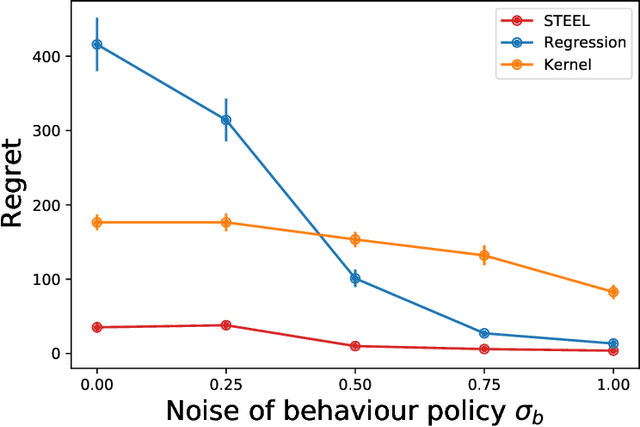

Batch reinforcement learning (RL) aims at finding an optimal policy in a dynamic environment in order to maximize the expected total rewards by leveraging pre-collected data. A fundamental challenge behind this task is the distributional mismatch between the batch data generating process and the distribution induced by target policies. Nearly all existing algorithms rely on the absolutely continuous assumption on the distribution induced by target policies with respect to the data distribution so that the batch data can be used to calibrate target policies via the change of measure. However, the absolute continuity assumption could be violated in practice, especially when the state-action space is large or continuous. In this paper, we propose a new batch RL algorithm without requiring absolute continuity in the setting of an infinite-horizon Markov decision process with continuous states and actions. We call our algorithm STEEL: SingulariTy-awarE rEinforcement Learning. Our algorithm is motivated by a new error analysis on off-policy evaluation, where we use maximum mean discrepancy, together with distributionally robust optimization, to characterize the error of off-policy evaluation caused by the possible singularity and to enable the power of model extrapolation. By leveraging the idea of pessimism and under some mild conditions, we derive a finite-sample regret guarantee for our proposed algorithm without imposing absolute continuity. Compared with existing algorithms, STEEL only requires some minimal data-coverage assumption and thus greatly enhances the applicability and robustness of batch RL. Extensive simulation studies and one real experiment on personalized pricing demonstrate the superior performance of our method when facing possible singularity in batch RL.