 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling from Constrained Gibbs Measures: with Applications to High-Dimensional Bayesian Inference
Feb 25, 2026This paper considers a non-standard problem of generating samples from a low-temperature Gibbs distribution with \emph{constrained} support, when some of the coordinates of the mode lie on the boundary. These coordinates are referred to as the non-regular part of the model. We show that in a ``pre-asymptotic'' regime in which the limiting Laplace approximation is not yet valid, the low-temperature Gibbs distribution concentrates on a neighborhood of its mode. Within this region, the distribution is a bounded perturbation of a product measure: a strongly log-concave distribution in the regular part and a one-dimensional exponential-type distribution in each coordinate of the non-regular part. Leveraging this structure, we provide a non-asymptotic sampling guarantee by analyzing the spectral gap of Langevin dynamics. Key examples of low-temperature Gibbs distributions include Bayesian posteriors, and we demonstrate our results on three canonical examples: a high-dimensional logistic regression model, a Poisson linear model, and a Gaussian mixture model.
Explicating Tacit Regulatory Knowledge from LLMs to Auto-Formalize Requirements for Compliance Test Case Generation
Jan 14, 2026Compliance testing in highly regulated domains is crucial but largely manual, requiring domain experts to translate complex regulations into executable test cases. While large language models (LLMs) show promise for automation, their susceptibility to hallucinations limits reliable application. Existing hybrid approaches mitigate this issue by constraining LLMs with formal models, but still rely on costly manual modeling. To solve this problem, this paper proposes RAFT, a framework for requirements auto-formalization and compliance test generation via explicating tacit regulatory knowledge from multiple LLMs. RAFT employs an Adaptive Purification-Aggregation strategy to explicate tacit regulatory knowledge from multiple LLMs and integrate it into three artifacts: a domain meta-model, a formal requirements representation, and testability constraints. These artifacts are then dynamically injected into prompts to guide high-precision requirement formalization and automated test generation. Experiments across financial, automotive, and power domains show that RAFT achieves expert-level performance, substantially outperforms state-of-the-art (SOTA) methods while reducing overall generation and review time.
Quantile-Optimal Policy Learning under Unmeasured Confounding
Jun 08, 2025We study quantile-optimal policy learning where the goal is to find a policy whose reward distribution has the largest $\alpha$-quantile for some $\alpha \in (0, 1)$. We focus on the offline setting whose generating process involves unobserved confounders. Such a problem suffers from three main challenges: (i) nonlinearity of the quantile objective as a functional of the reward distribution, (ii) unobserved confounding issue, and (iii) insufficient coverage of the offline dataset. To address these challenges, we propose a suite of causal-assisted policy learning methods that provably enjoy strong theoretical guarantees under mild conditions. In particular, to address (i) and (ii), using causal inference tools such as instrumental variables and negative controls, we propose to estimate the quantile objectives by solving nonlinear functional integral equations. Then we adopt a minimax estimation approach with nonparametric models to solve these integral equations, and propose to construct conservative policy estimates that address (iii). The final policy is the one that maximizes these pessimistic estimates. In addition, we propose a novel regularized policy learning method that is more amenable to computation. Finally, we prove that the policies learned by these methods are $\tilde{\mathscr{O}}(n^{-1/2})$ quantile-optimal under a mild coverage assumption on the offline dataset. Here, $\tilde{\mathscr{O}}(\cdot)$ omits poly-logarithmic factors. To the best of our knowledge, we propose the first sample-efficient policy learning algorithms for estimating the quantile-optimal policy when there exist unmeasured confounding.
Enhancing Transformation from Natural Language to Signal Temporal Logic Using LLMs with Diverse External Knowledge
May 27, 2025Temporal Logic (TL), especially Signal Temporal Logic (STL), enables precise formal specification, making it widely used in cyber-physical systems such as autonomous driving and robotics. Automatically transforming NL into STL is an attractive approach to overcome the limitations of manual transformation, which is time-consuming and error-prone. However, due to the lack of datasets, automatic transformation currently faces significant challenges and has not been fully explored. In this paper, we propose an NL-STL dataset named STL-Diversity-Enhanced (STL-DivEn), which comprises 16,000 samples enriched with diverse patterns. To develop the dataset, we first manually create a small-scale seed set of NL-STL pairs. Next, representative examples are identified through clustering and used to guide large language models (LLMs) in generating additional NL-STL pairs. Finally, diversity and accuracy are ensured through rigorous rule-based filters and human validation. Furthermore, we introduce the Knowledge-Guided STL Transformation (KGST) framework, a novel approach for transforming natural language into STL, involving a generate-then-refine process based on external knowledge. Statistical analysis shows that the STL-DivEn dataset exhibits more diversity than the existing NL-STL dataset. Moreover, both metric-based and human evaluations indicate that our KGST approach outperforms baseline models in transformation accuracy on STL-DivEn and DeepSTL datasets.
A Mean-Field Analysis of Neural Gradient Descent-Ascent: Applications to Functional Conditional Moment Equations
Apr 18, 2024We study minimax optimization problems defined over infinite-dimensional function classes. In particular, we restrict the functions to the class of overparameterized two-layer neural networks and study (i) the convergence of the gradient descent-ascent algorithm and (ii) the representation learning of the neural network. As an initial step, we consider the minimax optimization problem stemming from estimating a functional equation defined by conditional expectations via adversarial estimation, where the objective function is quadratic in the functional space. For this problem, we establish convergence under the mean-field regime by considering the continuous-time and infinite-width limit of the optimization dynamics. Under this regime, gradient descent-ascent corresponds to a Wasserstein gradient flow over the space of probability measures defined over the space of neural network parameters. We prove that the Wasserstein gradient flow converges globally to a stationary point of the minimax objective at a $\mathcal{O}(T^{-1} + \alpha^{-1} ) $ sublinear rate, and additionally finds the solution to the functional equation when the regularizer of the minimax objective is strongly convex. Here $T$ denotes the time and $\alpha$ is a scaling parameter of the neural network. In terms of representation learning, our results show that the feature representation induced by the neural networks is allowed to deviate from the initial one by the magnitude of $\mathcal{O}(\alpha^{-1})$, measured in terms of the Wasserstein distance. Finally, we apply our general results to concrete examples including policy evaluation, nonparametric instrumental variable regression, and asset pricing.
Synchronized Dual-arm Rearrangement via Cooperative mTSP
Mar 13, 2024Synchronized dual-arm rearrangement is widely studied as a common scenario in industrial applications. It often faces scalability challenges due to the computational complexity of robotic arm rearrangement and the high-dimensional nature of dual-arm planning. To address these challenges, we formulated the problem as cooperative mTSP, a variant of mTSP where agents share cooperative costs, and utilized reinforcement learning for its solution. Our approach involved representing rearrangement tasks using a task state graph that captured spatial relationships and a cooperative cost matrix that provided details about action costs. Taking these representations as observations, we designed an attention-based network to effectively combine them and provide rational task scheduling. Furthermore, a cost predictor is also introduced to directly evaluate actions during both training and planning, significantly expediting the planning process. Our experimental results demonstrate that our approach outperforms existing methods in terms of both performance and planning efficiency.
SGMM: Stochastic Approximation to Generalized Method of Moments
Aug 25, 2023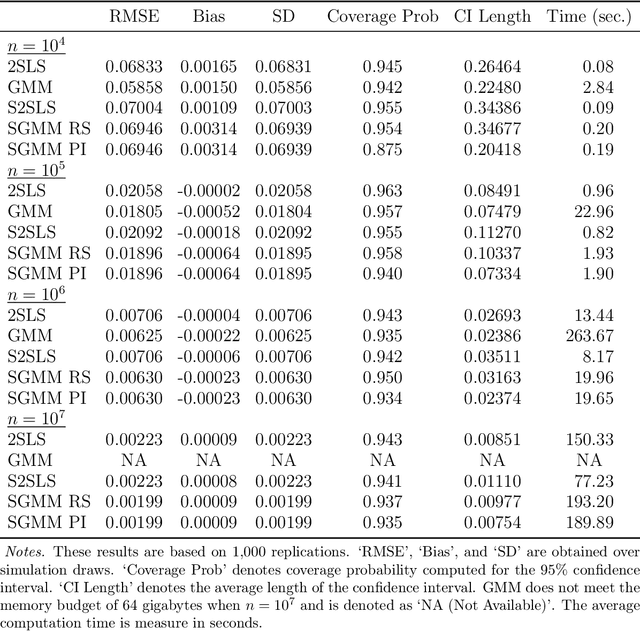
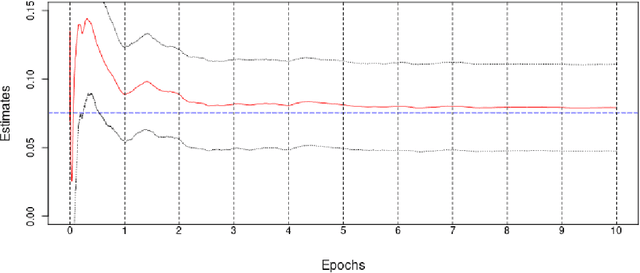
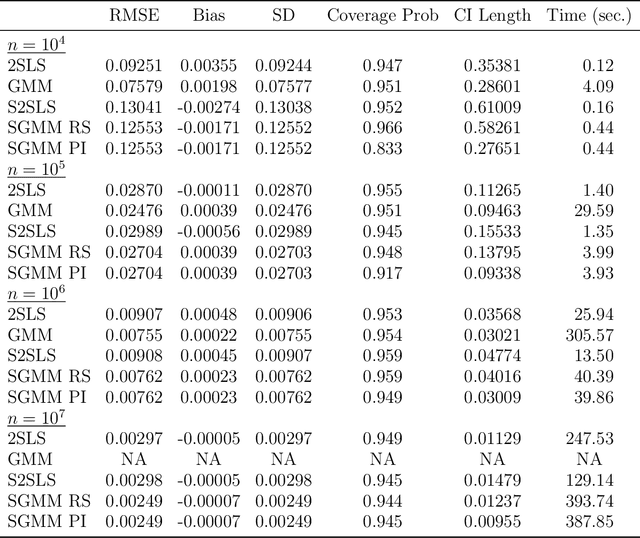
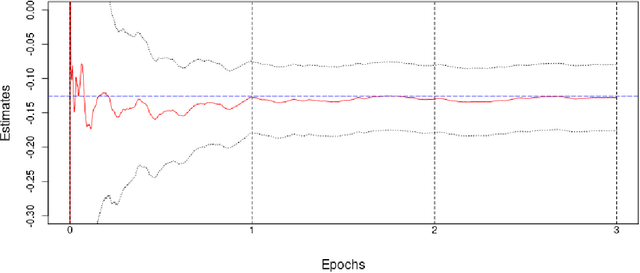
We introduce a new class of algorithms, Stochastic Generalized Method of Moments (SGMM), for estimation and inference on (overidentified) moment restriction models. Our SGMM is a novel stochastic approximation alternative to the popular Hansen (1982) (offline) GMM, and offers fast and scalable implementation with the ability to handle streaming datasets in real time. We establish the almost sure convergence, and the (functional) central limit theorem for the inefficient online 2SLS and the efficient SGMM. Moreover, we propose online versions of the Durbin-Wu-Hausman and Sargan-Hansen tests that can be seamlessly integrated within the SGMM framework. Extensive Monte Carlo simulations show that as the sample size increases, the SGMM matches the standard (offline) GMM in terms of estimation accuracy and gains over computational efficiency, indicating its practical value for both large-scale and online datasets. We demonstrate the efficacy of our approach by a proof of concept using two well known empirical examples with large sample sizes.
STEEL: Singularity-aware Reinforcement Learning
Jan 31, 2023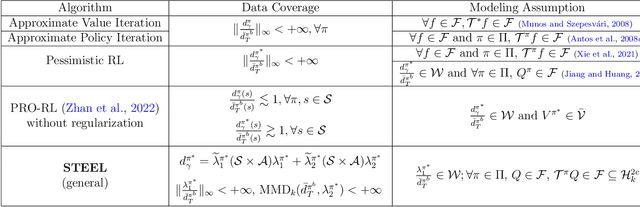
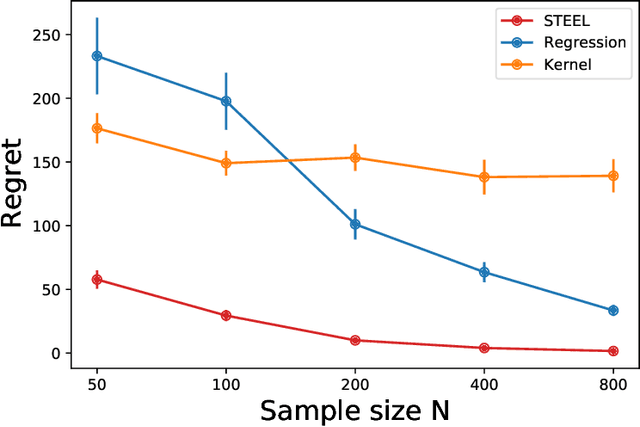
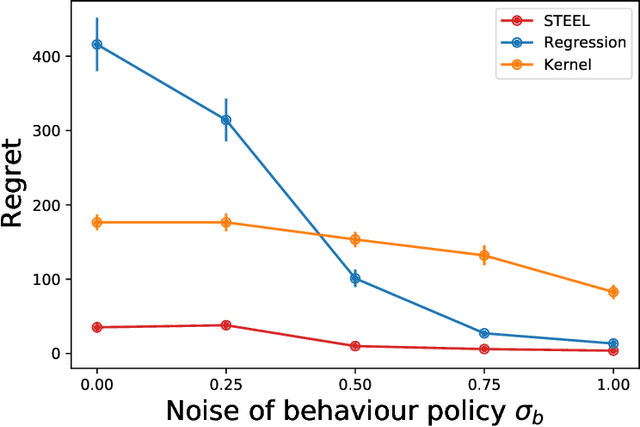

Batch reinforcement learning (RL) aims at finding an optimal policy in a dynamic environment in order to maximize the expected total rewards by leveraging pre-collected data. A fundamental challenge behind this task is the distributional mismatch between the batch data generating process and the distribution induced by target policies. Nearly all existing algorithms rely on the absolutely continuous assumption on the distribution induced by target policies with respect to the data distribution so that the batch data can be used to calibrate target policies via the change of measure. However, the absolute continuity assumption could be violated in practice, especially when the state-action space is large or continuous. In this paper, we propose a new batch RL algorithm without requiring absolute continuity in the setting of an infinite-horizon Markov decision process with continuous states and actions. We call our algorithm STEEL: SingulariTy-awarE rEinforcement Learning. Our algorithm is motivated by a new error analysis on off-policy evaluation, where we use maximum mean discrepancy, together with distributionally robust optimization, to characterize the error of off-policy evaluation caused by the possible singularity and to enable the power of model extrapolation. By leveraging the idea of pessimism and under some mild conditions, we derive a finite-sample regret guarantee for our proposed algorithm without imposing absolute continuity. Compared with existing algorithms, STEEL only requires some minimal data-coverage assumption and thus greatly enhances the applicability and robustness of batch RL. Extensive simulation studies and one real experiment on personalized pricing demonstrate the superior performance of our method when facing possible singularity in batch RL.
Inference on Time Series Nonparametric Conditional Moment Restrictions Using General Sieves
Jan 03, 2023General nonlinear sieve learnings are classes of nonlinear sieves that can approximate nonlinear functions of high dimensional variables much more flexibly than various linear sieves (or series). This paper considers general nonlinear sieve quasi-likelihood ratio (GN-QLR) based inference on expectation functionals of time series data, where the functionals of interest are based on some nonparametric function that satisfy conditional moment restrictions and are learned using multilayer neural networks. While the asymptotic normality of the estimated functionals depends on some unknown Riesz representer of the functional space, we show that the optimally weighted GN-QLR statistic is asymptotically Chi-square distributed, regardless whether the expectation functional is regular (root-$n$ estimable) or not. This holds when the data are weakly dependent beta-mixing condition. We apply our method to the off-policy evaluation in reinforcement learning, by formulating the Bellman equation into the conditional moment restriction framework, so that we can make inference about the state-specific value functional using the proposed GN-QLR method with time series data. In addition, estimating the averaged partial means and averaged partial derivatives of nonparametric instrumental variables and quantile IV models are also presented as leading examples. Finally, a Monte Carlo study shows the finite sample performance of the procedure
Adaptive incomplete multi-view learning via tensor graph completion
Aug 07, 2022
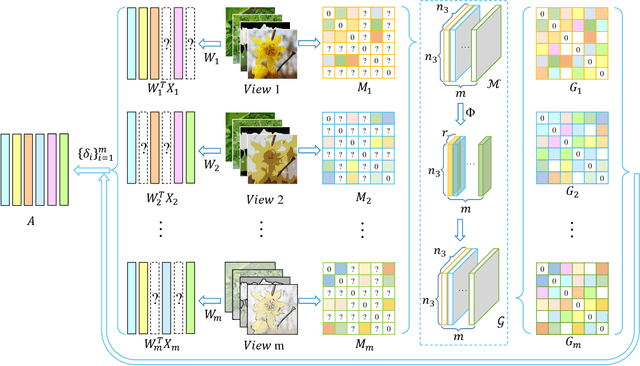
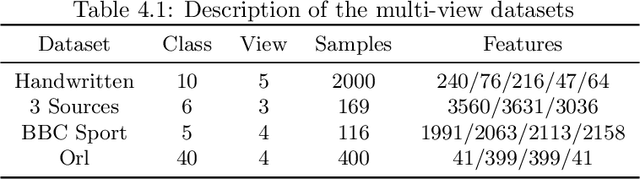
With the advancement of the data acquisition techniques, multi-view learning has become a hot topic. Some multi-view learning methods assume that the multi-view data is complete, which means that all instances are present, but this too ideal. Certain tensor-based methods for handing incomplete multi-view data have emerged and have achieved better result. However, there are still some problems, such as use of traditional tensor norm which makes the computation high and is not able to handle out-of-sample. To solve these two problems, we proposed a new incomplete multi view learning method. A new tensor norm is defined to implement graph tensor data recover. The recovered graphs are then regularized to a consistent low-dimensional representation of the samples. In addition, adaptive weights are equipped to each view to adjust the importance of different views. Compared with the existing methods, our method nor only explores the consistency among views, but also obtains the low-dimensional representation of the new samples by using the learned projection matrix. An efficient algorithm based on inexact augmented Lagrange multiplier (ALM) method are designed to solve the model and convergence is proved. Experimental results on four datasets show the effectiveness of our method.