 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Flexible Job Shop Scheduling under Limited Buffers and Material Kitting Constraints
Feb 27, 2026The Flexible Job Shop Scheduling Problem (FJSP) originates from real production lines, while some practical constraints are often ignored or idealized in current FJSP studies, among which the limited buffer problem has a particular impact on production efficiency. To this end, we study an extended problem that is closer to practical scenarios--the Flexible Job Shop Scheduling Problem with Limited Buffers and Material Kitting. In recent years, deep reinforcement learning (DRL) has demonstrated considerable potential in scheduling tasks. However, its capacity for state modeling remains limited when handling complex dependencies and long-term constraints. To address this, we leverage a heterogeneous graph network within the DRL framework to model the global state. By constructing efficient message passing among machines, operations, and buffers, the network focuses on avoiding decisions that may cause frequent pallet changes during long-sequence scheduling, thereby helping improve buffer utilization and overall decision quality. Experimental results on both synthetic and real production line datasets show that the proposed method outperforms traditional heuristics and advanced DRL methods in terms of makespan and pallet changes, and also achieves a good balance between solution quality and computational cost. Furthermore, a supplementary video is provided to showcase a simulation system that effectively visualizes the progression of the production line.
Learning Cross-hand Policies for High-DOF Reaching and Grasping
Apr 14, 2024
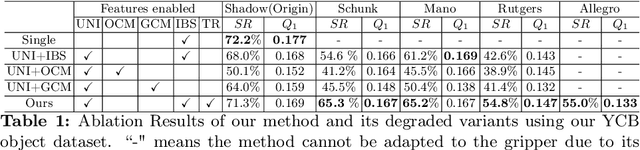


Reaching-and-grasping is a fundamental skill for robotic manipulation, but existing methods usually train models on a specific gripper and cannot be reused on another gripper without retraining. In this paper, we propose a novel method that can learn a unified policy model that can be easily transferred to different dexterous grippers. Our method consists of two stages: a gripper-agnostic policy model that predicts the displacements of predefined key points on the gripper, and a gripper specific adaptation model that translates these displacements into adjustments for controlling the grippers' joints. The gripper state and interactions with objects are captured at the finger level using robust geometric representations, integrated with a transformer-based network to address variations in gripper morphology and geometry. In the experimental part, we evaluate our method on several dexterous grippers and objects of diverse shapes, and the result shows that our method significantly outperforms the baseline methods. Pioneering the transfer of grasp policies across different dexterous grippers, our method effectively demonstrates its potential for learning generalizable and transferable manipulation skills for various robotic hands
Synchronized Dual-arm Rearrangement via Cooperative mTSP
Mar 13, 2024Synchronized dual-arm rearrangement is widely studied as a common scenario in industrial applications. It often faces scalability challenges due to the computational complexity of robotic arm rearrangement and the high-dimensional nature of dual-arm planning. To address these challenges, we formulated the problem as cooperative mTSP, a variant of mTSP where agents share cooperative costs, and utilized reinforcement learning for its solution. Our approach involved representing rearrangement tasks using a task state graph that captured spatial relationships and a cooperative cost matrix that provided details about action costs. Taking these representations as observations, we designed an attention-based network to effectively combine them and provide rational task scheduling. Furthermore, a cost predictor is also introduced to directly evaluate actions during both training and planning, significantly expediting the planning process. Our experimental results demonstrate that our approach outperforms existing methods in terms of both performance and planning efficiency.
Learning Dual-arm Object Rearrangement for Cartesian Robots
Feb 21, 2024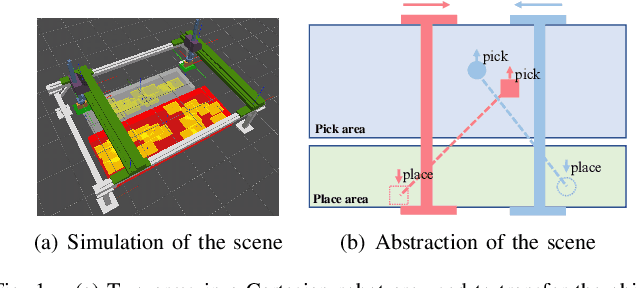
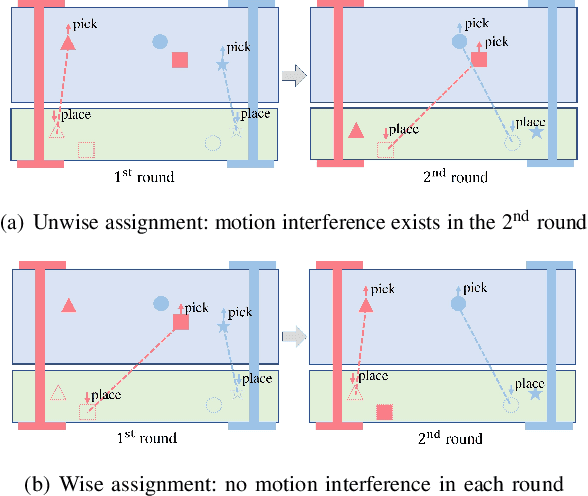
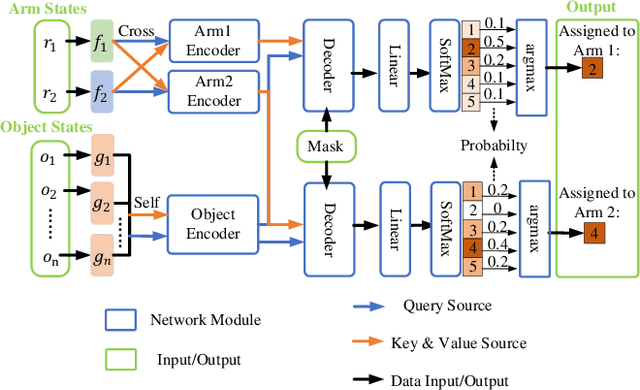
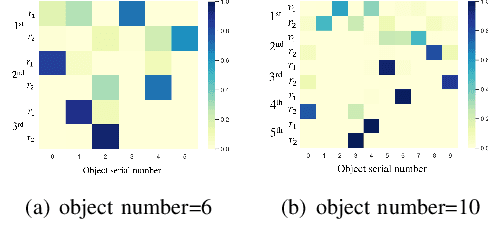
This work focuses on the dual-arm object rearrangement problem abstracted from a realistic industrial scenario of Cartesian robots. The goal of this problem is to transfer all the objects from sources to targets with the minimum total completion time. To achieve the goal, the core idea is to develop an effective object-to-arm task assignment strategy for minimizing the cumulative task execution time and maximizing the dual-arm cooperation efficiency. One of the difficulties in the task assignment is the scalability problem. As the number of objects increases, the computation time of traditional offline-search-based methods grows strongly for computational complexity. Encouraged by the adaptability of reinforcement learning (RL) in long-sequence task decisions, we propose an online task assignment decision method based on RL, and the computation time of our method only increases linearly with the number of objects. Further, we design an attention-based network to model the dependencies between the input states during the whole task execution process to help find the most reasonable object-to-arm correspondence in each task assignment round. In the experimental part, we adapt some search-based methods to this specific setting and compare our method with them. Experimental result shows that our approach achieves outperformance over search-based methods in total execution time and computational efficiency, and also verifies the generalization of our method to different numbers of objects. In addition, we show the effectiveness of our method deployed on the real robot in the supplementary video.