 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorHOI: Zero-shot Generation of 4D Human-Object Interaction via Anchor-based Prior Distillation
Dec 16, 2025



Despite significant progress in text-driven 4D human-object interaction (HOI) generation with supervised methods, the scalability remains limited by the scarcity of large-scale 4D HOI datasets. To overcome this, recent approaches attempt zero-shot 4D HOI generation with pre-trained image diffusion models. However, interaction cues are minimally distilled during the generation process, restricting their applicability across diverse scenarios. In this paper, we propose AnchorHOI, a novel framework that thoroughly exploits hybrid priors by incorporating video diffusion models beyond image diffusion models, advancing 4D HOI generation. Nevertheless, directly optimizing high-dimensional 4D HOI with such priors remains challenging, particularly for human pose and compositional motion. To address this challenge, AnchorHOI introduces an anchor-based prior distillation strategy, which constructs interaction-aware anchors and then leverages them to guide generation in a tractable two-step process. Specifically, two tailored anchors are designed for 4D HOI generation: anchor Neural Radiance Fields (NeRFs) for expressive interaction composition, and anchor keypoints for realistic motion synthesis. Extensive experiments demonstrate that AnchorHOI outperforms previous methods with superior diversity and generalization.
InterFusion: Text-Driven Generation of 3D Human-Object Interaction
Mar 22, 2024
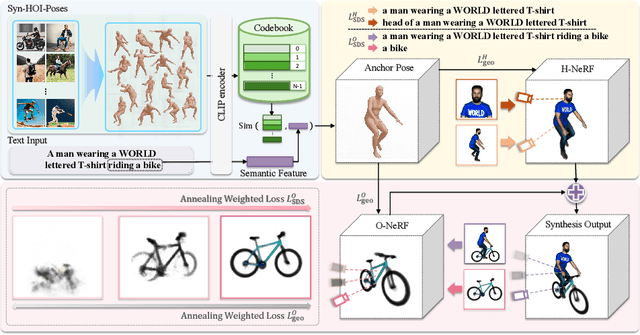


In this study, we tackle the complex task of generating 3D human-object interactions (HOI) from textual descriptions in a zero-shot text-to-3D manner. We identify and address two key challenges: the unsatisfactory outcomes of direct text-to-3D methods in HOI, largely due to the lack of paired text-interaction data, and the inherent difficulties in simultaneously generating multiple concepts with complex spatial relationships. To effectively address these issues, we present InterFusion, a two-stage framework specifically designed for HOI generation. InterFusion involves human pose estimations derived from text as geometric priors, which simplifies the text-to-3D conversion process and introduces additional constraints for accurate object generation. At the first stage, InterFusion extracts 3D human poses from a synthesized image dataset depicting a wide range of interactions, subsequently mapping these poses to interaction descriptions. The second stage of InterFusion capitalizes on the latest developments in text-to-3D generation, enabling the production of realistic and high-quality 3D HOI scenes. This is achieved through a local-global optimization process, where the generation of human body and object is optimized separately, and jointly refined with a global optimization of the entire scene, ensuring a seamless and contextually coherent integration. Our experimental results affirm that InterFusion significantly outperforms existing state-of-the-art methods in 3D HOI generation.
Synchronized Dual-arm Rearrangement via Cooperative mTSP
Mar 13, 2024Synchronized dual-arm rearrangement is widely studied as a common scenario in industrial applications. It often faces scalability challenges due to the computational complexity of robotic arm rearrangement and the high-dimensional nature of dual-arm planning. To address these challenges, we formulated the problem as cooperative mTSP, a variant of mTSP where agents share cooperative costs, and utilized reinforcement learning for its solution. Our approach involved representing rearrangement tasks using a task state graph that captured spatial relationships and a cooperative cost matrix that provided details about action costs. Taking these representations as observations, we designed an attention-based network to effectively combine them and provide rational task scheduling. Furthermore, a cost predictor is also introduced to directly evaluate actions during both training and planning, significantly expediting the planning process. Our experimental results demonstrate that our approach outperforms existing methods in terms of both performance and planning efficiency.