 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Flexible Job Shop Scheduling under Limited Buffers and Material Kitting Constraints
Feb 27, 2026The Flexible Job Shop Scheduling Problem (FJSP) originates from real production lines, while some practical constraints are often ignored or idealized in current FJSP studies, among which the limited buffer problem has a particular impact on production efficiency. To this end, we study an extended problem that is closer to practical scenarios--the Flexible Job Shop Scheduling Problem with Limited Buffers and Material Kitting. In recent years, deep reinforcement learning (DRL) has demonstrated considerable potential in scheduling tasks. However, its capacity for state modeling remains limited when handling complex dependencies and long-term constraints. To address this, we leverage a heterogeneous graph network within the DRL framework to model the global state. By constructing efficient message passing among machines, operations, and buffers, the network focuses on avoiding decisions that may cause frequent pallet changes during long-sequence scheduling, thereby helping improve buffer utilization and overall decision quality. Experimental results on both synthetic and real production line datasets show that the proposed method outperforms traditional heuristics and advanced DRL methods in terms of makespan and pallet changes, and also achieves a good balance between solution quality and computational cost. Furthermore, a supplementary video is provided to showcase a simulation system that effectively visualizes the progression of the production line.
Simultaneous Automatic Picking and Manual Picking Refinement for First-Break
Feb 03, 2025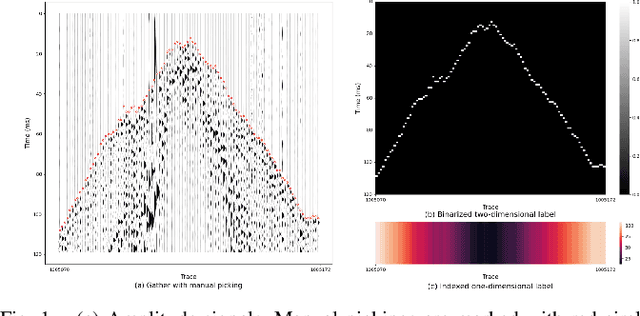
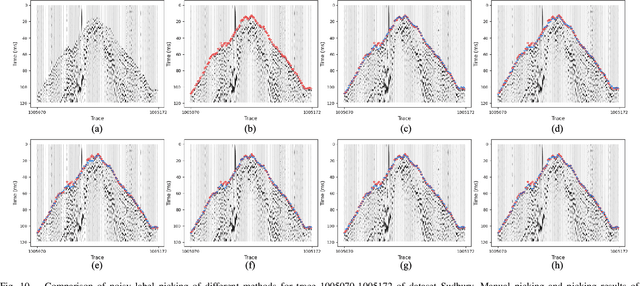
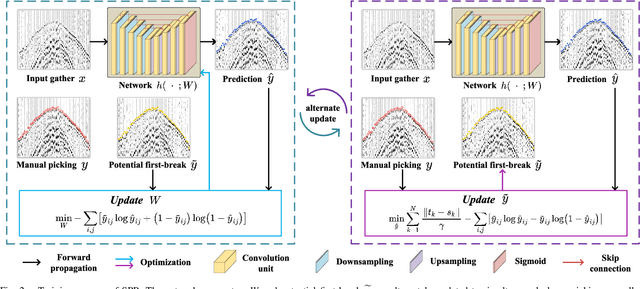
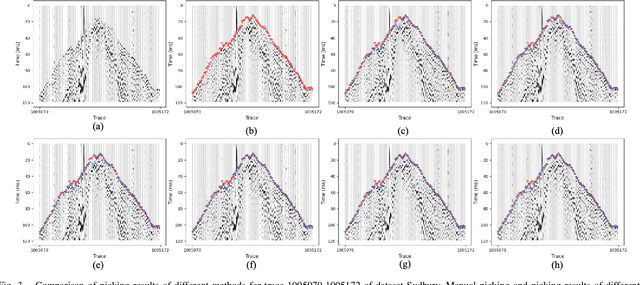
First-break picking is a pivotal procedure in processing microseismic data for geophysics and resource exploration. Recent advancements in deep learning have catalyzed the evolution of automated methods for identifying first-break. Nevertheless, the complexity of seismic data acquisition and the requirement for detailed, expert-driven labeling often result in outliers and potential mislabeling within manually labeled datasets. These issues can negatively affect the training of neural networks, necessitating algorithms that handle outliers or mislabeled data effectively. We introduce the Simultaneous Picking and Refinement (SPR) algorithm, designed to handle datasets plagued by outlier samples or even noisy labels. Unlike conventional approaches that regard manual picks as ground truth, our method treats the true first-break as a latent variable within a probabilistic model that includes a first-break labeling prior. SPR aims to uncover this variable, enabling dynamic adjustments and improved accuracy across the dataset. This strategy mitigates the impact of outliers or inaccuracies in manual labels. Intra-site picking experiments and cross-site generalization experiments on publicly available data confirm our method's performance in identifying first-break and its generalization across different sites. Additionally, our investigations into noisy signals and labels underscore SPR's resilience to both types of noise and its capability to refine misaligned manual annotations. Moreover, the flexibility of SPR, not being limited to any single network architecture, enhances its adaptability across various deep learning-based picking methods. Focusing on learning from data that may contain outliers or partial inaccuracies, SPR provides a robust solution to some of the principal obstacles in automatic first-break picking.
NeRF-Guided Unsupervised Learning of RGB-D Registration
May 01, 2024



This paper focuses on training a robust RGB-D registration model without ground-truth pose supervision. Existing methods usually adopt a pairwise training strategy based on differentiable rendering, which enforces the photometric and the geometric consistency between the two registered frames as supervision. However, this frame-to-frame framework suffers from poor multi-view consistency due to factors such as lighting changes, geometry occlusion and reflective materials. In this paper, we present NeRF-UR, a novel frame-to-model optimization framework for unsupervised RGB-D registration. Instead of frame-to-frame consistency, we leverage the neural radiance field (NeRF) as a global model of the scene and use the consistency between the input and the NeRF-rerendered frames for pose optimization. This design can significantly improve the robustness in scenarios with poor multi-view consistency and provides better learning signal for the registration model. Furthermore, to bootstrap the NeRF optimization, we create a synthetic dataset, Sim-RGBD, through a photo-realistic simulator to warm up the registration model. By first training the registration model on Sim-RGBD and later unsupervisedly fine-tuning on real data, our framework enables distilling the capability of feature extraction and registration from simulation to reality. Our method outperforms the state-of-the-art counterparts on two popular indoor RGB-D datasets, ScanNet and 3DMatch. Code and models will be released for paper reproduction.
Learning Dual-arm Object Rearrangement for Cartesian Robots
Feb 21, 2024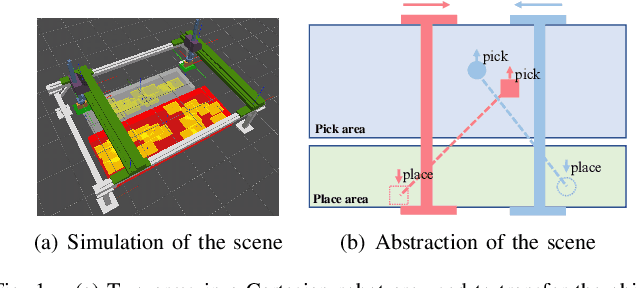
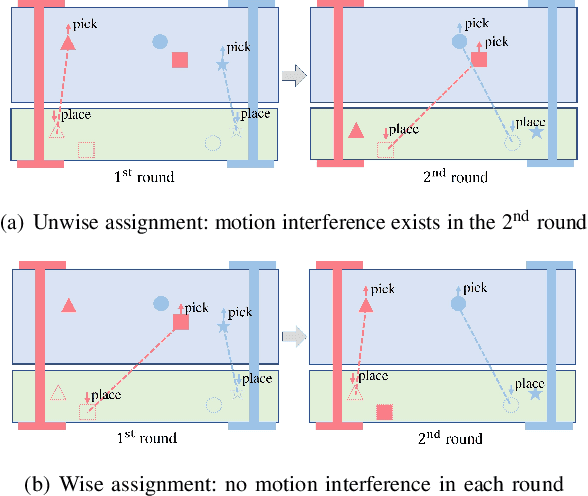
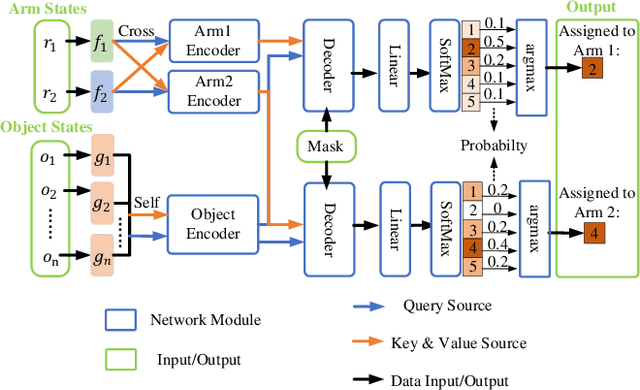
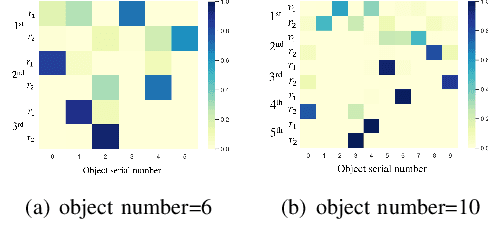
This work focuses on the dual-arm object rearrangement problem abstracted from a realistic industrial scenario of Cartesian robots. The goal of this problem is to transfer all the objects from sources to targets with the minimum total completion time. To achieve the goal, the core idea is to develop an effective object-to-arm task assignment strategy for minimizing the cumulative task execution time and maximizing the dual-arm cooperation efficiency. One of the difficulties in the task assignment is the scalability problem. As the number of objects increases, the computation time of traditional offline-search-based methods grows strongly for computational complexity. Encouraged by the adaptability of reinforcement learning (RL) in long-sequence task decisions, we propose an online task assignment decision method based on RL, and the computation time of our method only increases linearly with the number of objects. Further, we design an attention-based network to model the dependencies between the input states during the whole task execution process to help find the most reasonable object-to-arm correspondence in each task assignment round. In the experimental part, we adapt some search-based methods to this specific setting and compare our method with them. Experimental result shows that our approach achieves outperformance over search-based methods in total execution time and computational efficiency, and also verifies the generalization of our method to different numbers of objects. In addition, we show the effectiveness of our method deployed on the real robot in the supplementary video.
RoSAS: Deep Semi-Supervised Anomaly Detection with Contamination-Resilient Continuous Supervision
Jul 25, 2023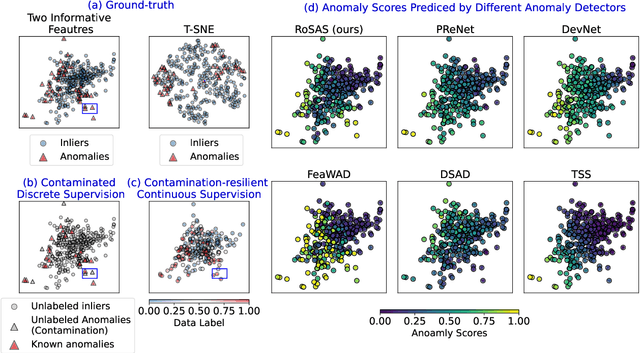

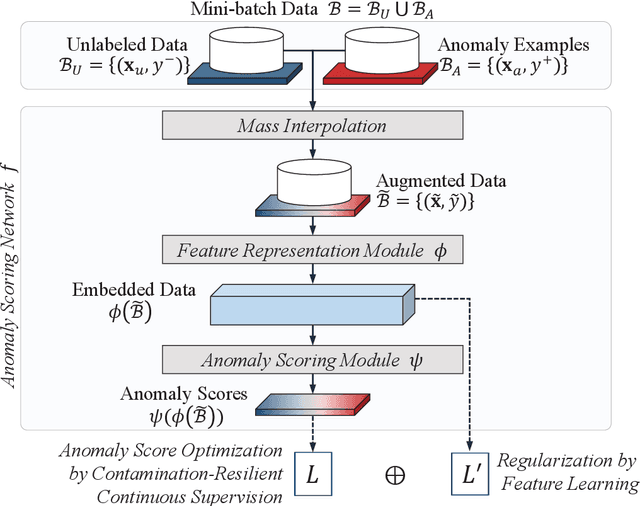
Semi-supervised anomaly detection methods leverage a few anomaly examples to yield drastically improved performance compared to unsupervised models. However, they still suffer from two limitations: 1) unlabeled anomalies (i.e., anomaly contamination) may mislead the learning process when all the unlabeled data are employed as inliers for model training; 2) only discrete supervision information (such as binary or ordinal data labels) is exploited, which leads to suboptimal learning of anomaly scores that essentially take on a continuous distribution. Therefore, this paper proposes a novel semi-supervised anomaly detection method, which devises \textit{contamination-resilient continuous supervisory signals}. Specifically, we propose a mass interpolation method to diffuse the abnormality of labeled anomalies, thereby creating new data samples labeled with continuous abnormal degrees. Meanwhile, the contaminated area can be covered by new data samples generated via combinations of data with correct labels. A feature learning-based objective is added to serve as an optimization constraint to regularize the network and further enhance the robustness w.r.t. anomaly contamination. Extensive experiments on 11 real-world datasets show that our approach significantly outperforms state-of-the-art competitors by 20%-30% in AUC-PR and obtains more robust and superior performance in settings with different anomaly contamination levels and varying numbers of labeled anomalies. The source code is available at https://github.com/xuhongzuo/rosas/.
Calibrated One-class Classification for Unsupervised Time Series Anomaly Detection
Jul 25, 2022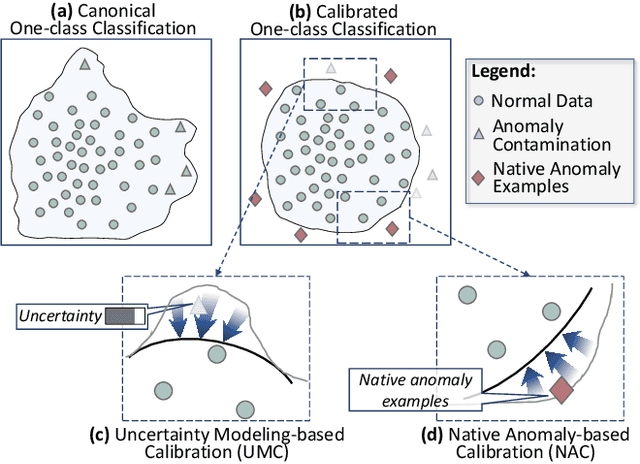
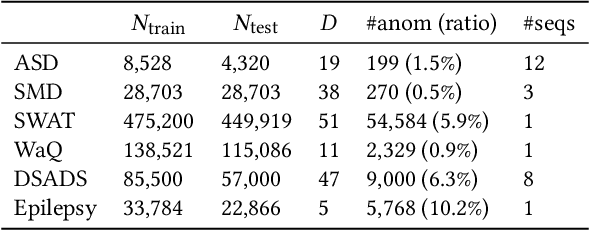
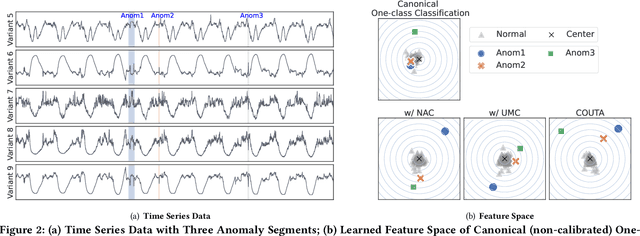
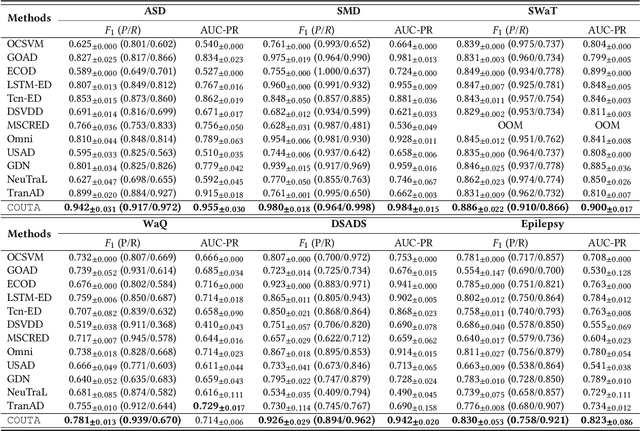
Unsupervised time series anomaly detection is instrumental in monitoring and alarming potential faults of target systems in various domains. Current state-of-the-art time series anomaly detectors mainly focus on devising advanced neural network structures and new reconstruction/prediction learning objectives to learn data normality (normal patterns and behaviors) as accurately as possible. However, these one-class learning methods can be deceived by unknown anomalies in the training data (i.e., anomaly contamination). Further, their normality learning also lacks knowledge about the anomalies of interest. Consequently, they often learn a biased, inaccurate normality boundary. This paper proposes a novel one-class learning approach, named calibrated one-class classification, to tackle this problem. Our one-class classifier is calibrated in two ways: (1) by adaptively penalizing uncertain predictions, which helps eliminate the impact of anomaly contamination while accentuating the predictions that the one-class model is confident in, and (2) by discriminating the normal samples from native anomaly examples that are generated to simulate genuine time series abnormal behaviors on the basis of original data. These two calibrations result in contamination-tolerant, anomaly-informed one-class learning, yielding a significantly improved normality modeling. Extensive experiments on six real-world datasets show that our model substantially outperforms twelve state-of-the-art competitors and obtains 6% - 31% F1 score improvement. The source code is available at \url{https://github.com/xuhongzuo/couta}.
Deep Isolation Forest for Anomaly Detection
Jun 14, 2022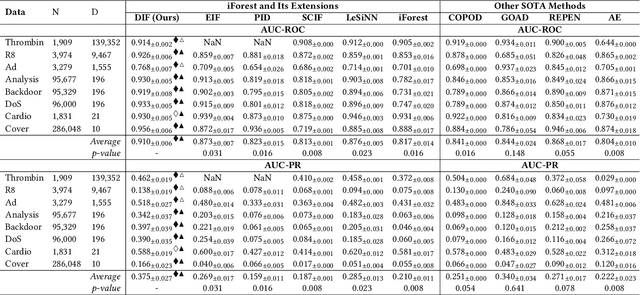
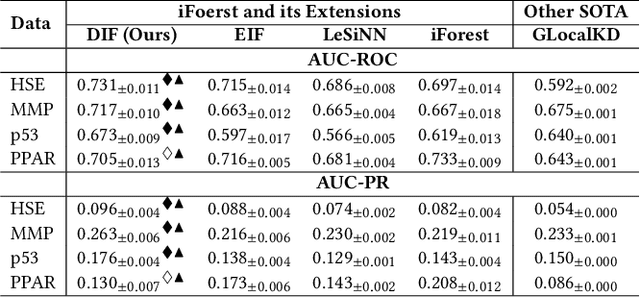
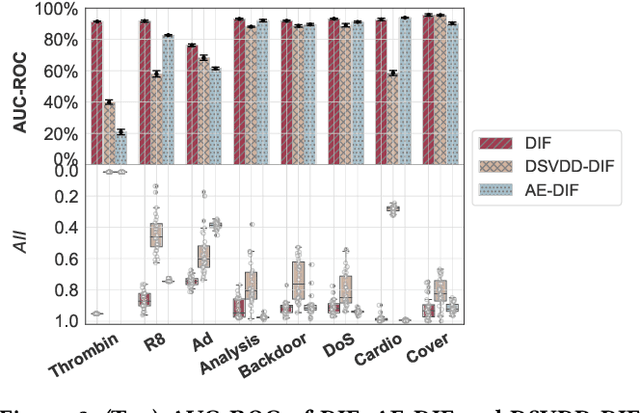
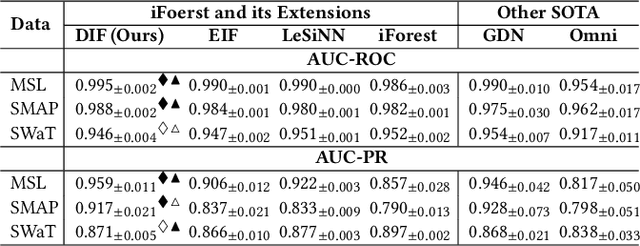
Isolation forest (iForest) has been emerging as arguably the most popular anomaly detector in recent years. It iteratively performs axis-parallel data space partition in a tree structure to isolate deviated data objects from the other data, with the isolation difficulty of the objects defined as anomaly scores. iForest shows effective performance across popular dataset benchmarks, but its axis-parallel-based linear data partition is ineffective in handling hard anomalies in high-dimensional/non-linear-separable data space, and even worse, it leads to a notorious algorithmic bias that assigns unexpectedly large anomaly scores to artefact regions. There have been several extensions of iForest, but they still focus on linear data partition, failing to effectively isolate those hard anomalies. This paper introduces a novel extension of iForest, deep isolation forest. Our method offers a comprehensive isolation method that can arbitrarily partition the data at any random direction and angle on subspaces of any size, effectively avoiding the algorithmic bias in the linear partition. Further, it requires only randomly initialised neural networks (i.e., no optimisation is required in our method) to ensure the freedom of the partition. In doing so, desired randomness and diversity in both random network-based representations and random partition-based isolation can be fully leveraged to significantly enhance the isolation ensemble-based anomaly detection. Also, our approach offers a data-type-agnostic anomaly detection solution. It is versatile to detect anomalies in different types of data by simply plugging in corresponding randomly initialised neural networks in the feature mapping. Extensive empirical results on a large collection of real-world datasets show that our model achieves substantial improvement over state-of-the-art isolation-based and non-isolation-based anomaly detection models.
DRAM Failure Prediction in AIOps: Empirical Evaluation, Challenges and Opportunities
May 04, 2021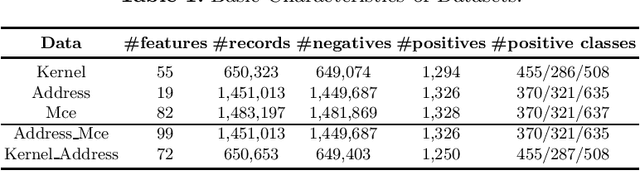
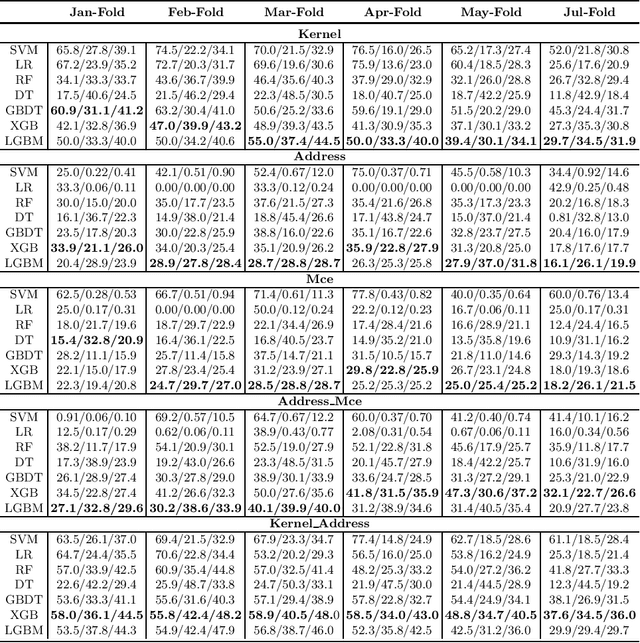
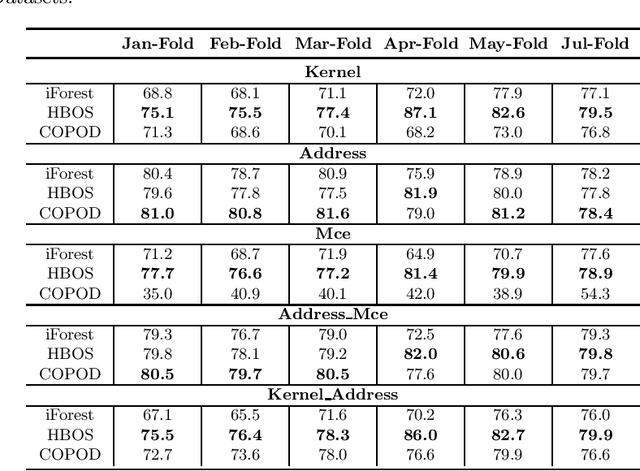
DRAM failure prediction is a vital task in AIOps, which is crucial to maintain the reliability and sustainable service of large-scale data centers. However, limited work has been done on DRAM failure prediction mainly due to the lack of public available datasets. This paper presents a comprehensive empirical evaluation of diverse machine learning techniques for DRAM failure prediction using a large-scale multi-source dataset, including more than three millions of records of kernel, address, and mcelog data, provided by Alibaba Cloud through PAKDD 2021 competition. Particularly, we first formulate the problem as a multi-class classification task and exhaustively evaluate seven popular/state-of-the-art classifiers on both the individual and multiple data sources. We then formulate the problem as an unsupervised anomaly detection task and evaluate three state-of-the-art anomaly detectors. Further, based on the empirical results and our experience of attending this competition, we discuss major challenges and present future research opportunities in this task.
Linearly Supporting Feature Extraction For Automated Estimation Of Stellar Atmospheric Parameters
Apr 10, 2015
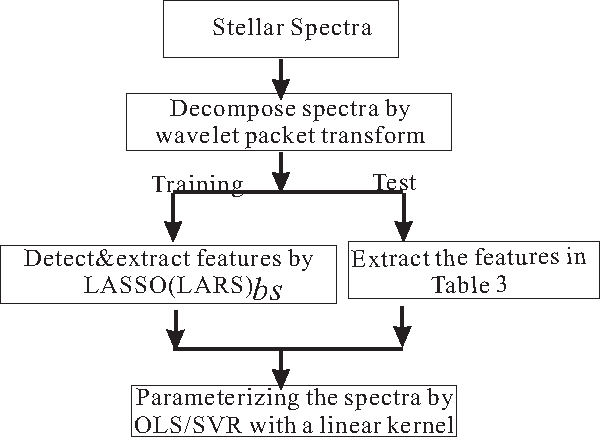
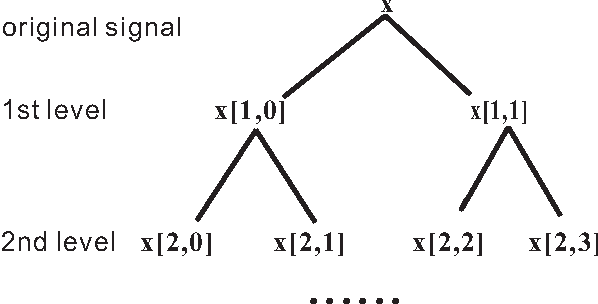
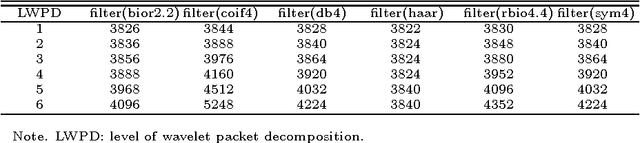
We describe a scheme to extract linearly supporting (LSU) features from stellar spectra to automatically estimate the atmospheric parameters $T_{eff}$, log$~g$, and [Fe/H]. "Linearly supporting" means that the atmospheric parameters can be accurately estimated from the extracted features through a linear model. The successive steps of the process are as follow: first, decompose the spectrum using a wavelet packet (WP) and represent it by the derived decomposition coefficients; second, detect representative spectral features from the decomposition coefficients using the proposed method Least Absolute Shrinkage and Selection Operator (LARS)$_{bs}$; third, estimate the atmospheric parameters $T_{eff}$, log$~g$, and [Fe/H] from the detected features using a linear regression method. One prominent characteristic of this scheme is its ability to evaluate quantitatively the contribution of each detected feature to the atmospheric parameter estimate and also to trace back the physical significance of that feature. This work also shows that the usefulness of a component depends on both wavelength and frequency. The proposed scheme has been evaluated on both real spectra from the Sloan Digital Sky Survey (SDSS)/SEGUE and synthetic spectra calculated from Kurucz's NEWODF models. On real spectra, we extracted 23 features to estimate $T_{eff}$, 62 features for log$~g$, and 68 features for [Fe/H]. Test consistencies between our estimates and those provided by the Spectroscopic Sarameter Pipeline of SDSS show that the mean absolute errors (MAEs) are 0.0062 dex for log$~T_{eff}$ (83 K for $T_{eff}$), 0.2345 dex for log$~g$, and 0.1564 dex for [Fe/H]. For the synthetic spectra, the MAE test accuracies are 0.0022 dex for log$~T_{eff}$ (32 K for $T_{eff}$), 0.0337 dex for log$~g$, and 0.0268 dex for [Fe/H].