 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Isolation Forest for Anomaly Detection
Paper and Code
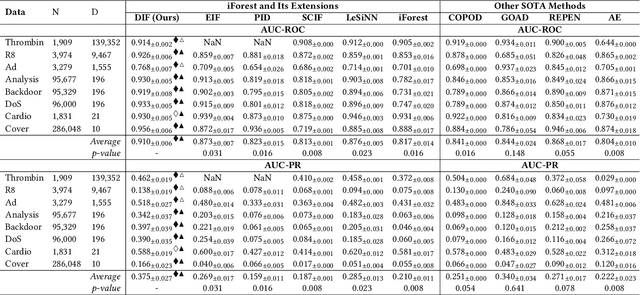
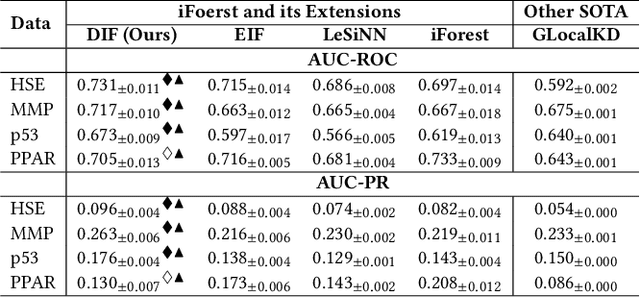
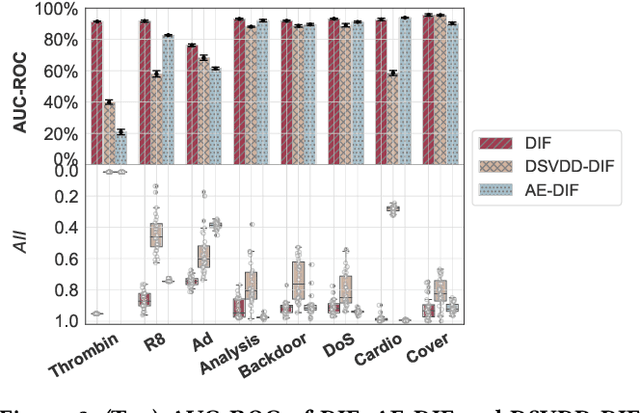
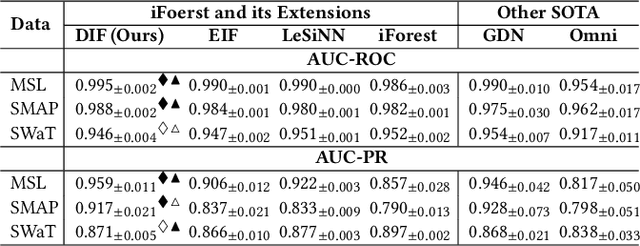
Isolation forest (iForest) has been emerging as arguably the most popular anomaly detector in recent years. It iteratively performs axis-parallel data space partition in a tree structure to isolate deviated data objects from the other data, with the isolation difficulty of the objects defined as anomaly scores. iForest shows effective performance across popular dataset benchmarks, but its axis-parallel-based linear data partition is ineffective in handling hard anomalies in high-dimensional/non-linear-separable data space, and even worse, it leads to a notorious algorithmic bias that assigns unexpectedly large anomaly scores to artefact regions. There have been several extensions of iForest, but they still focus on linear data partition, failing to effectively isolate those hard anomalies. This paper introduces a novel extension of iForest, deep isolation forest. Our method offers a comprehensive isolation method that can arbitrarily partition the data at any random direction and angle on subspaces of any size, effectively avoiding the algorithmic bias in the linear partition. Further, it requires only randomly initialised neural networks (i.e., no optimisation is required in our method) to ensure the freedom of the partition. In doing so, desired randomness and diversity in both random network-based representations and random partition-based isolation can be fully leveraged to significantly enhance the isolation ensemble-based anomaly detection. Also, our approach offers a data-type-agnostic anomaly detection solution. It is versatile to detect anomalies in different types of data by simply plugging in corresponding randomly initialised neural networks in the feature mapping. Extensive empirical results on a large collection of real-world datasets show that our model achieves substantial improvement over state-of-the-art isolation-based and non-isolation-based anomaly detection models.