 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking Constraints via Topological Dual-Directional Search in Evolutionary Multi-Objective Optimization
Apr 06, 2026Existing evolutionary algorithms for Constrained Multi-objective Optimization Problems (CMOPs) typically treat all constraints uniformly, overlooking their distinct geometric relationships with the true Constrained Pareto Front (CPF). In reality, constraints play different roles: some directly shape the final CPF, some create infeasible obstacles, while others are irrelevant. To exploit this insight, we propose a novel algorithm named RCCMO, which sequentially performs unconstrained exploration, single-constraint exploitation, and full-constraint refinement. The core innovation of RCCMO lies in a constraint prioritization method derived from these geometric insights, seamlessly coupled with a unique dual-directional search mechanism. Specifically, RCCMO first prioritizes constraints that constitute the final CPF, approaching them from the evolutionary direction (optimizing objectives) to locate the CPF directly shaped by single-constraint boundaries. Subsequently, for constraints that merely hinder the population's progress, RCCMO searches from the anti-evolutionary direction (targeting the infeasible boundaries where hindering constraints intersect with the CPF) to effectively discover how these constraints obstruct and form the final CPF. Meanwhile, irrelevant constraints are intentionally bypassed. Furthermore, a series of specialized mechanisms are proposed to accelerate the algorithm's execution, reduce heuristic misjudgments, and dynamically adjust search directions in real time. Extensive experiments on 5 benchmark test suites and 29 real-world CMOPs demonstrate that RCCMO significantly outperforms seven state-of-the-art algorithms.
IMPACT: Influence Modeling for Open-Set Time Series Anomaly Detection
Mar 31, 2026Open-set anomaly detection (OSAD) is an emerging paradigm designed to utilize limited labeled data from anomaly classes seen in training to identify both seen and unseen anomalies during testing. Current approaches rely on simple augmentation methods to generate pseudo anomalies that replicate unseen anomalies. Despite being promising in image data, these methods are found to be ineffective in time series data due to the failure to preserve its sequential nature, resulting in trivial or unrealistic anomaly patterns. They are further plagued when the training data is contaminated with unlabeled anomalies. This work introduces $\textbf{IMPACT}$, a novel framework that leverages $\underline{\textbf{i}}$nfluence $\underline{\textbf{m}}$odeling for o$\underline{\textbf{p}}$en-set time series $\underline{\textbf{a}}$nomaly dete$\underline{\textbf{ct}}$ion, to tackle these challenges. The key insight is to $\textbf{i)}$ learn an influence function that can accurately estimate the impact of individual training samples on the modeling, and then $\textbf{ii)}$ leverage these influence scores to generate semantically divergent yet realistic unseen anomalies for time series while repurposing high-influential samples as supervised anomalies for anomaly decontamination. Extensive experiments show that IMPACT significantly outperforms existing state-of-the-art methods, showing superior accuracy under varying OSAD settings and contamination rates.
MATTERIX: toward a digital twin for robotics-assisted chemistry laboratory automation
Jan 19, 2026Accelerated materials discovery is critical for addressing global challenges. However, developing new laboratory workflows relies heavily on real-world experimental trials, and this can hinder scalability because of the need for numerous physical make-and-test iterations. Here we present MATTERIX, a multiscale, graphics processing unit-accelerated robotic simulation framework designed to create high-fidelity digital twins of chemistry laboratories, thus accelerating workflow development. This multiscale digital twin simulates robotic physical manipulation, powder and liquid dynamics, device functionalities, heat transfer and basic chemical reaction kinetics. This is enabled by integrating realistic physics simulation and photorealistic rendering with a modular graphics processing unit-accelerated semantics engine, which models logical states and continuous behaviors to simulate chemistry workflows across different levels of abstraction. MATTERIX streamlines the creation of digital twin environments through open-source asset libraries and interfaces, while enabling flexible workflow design via hierarchical plan definition and a modular skill library that incorporates learning-based methods. Our approach demonstrates sim-to-real transfer in robotic chemistry setups, reducing reliance on costly real-world experiments and enabling the testing of hypothetical automated workflows in silico. The project website is available at https://accelerationconsortium.github.io/Matterix/ .
Decoupling Constraint from Two Direction in Evolutionary Constrained Multi-objective Optimization
Dec 30, 2025Real-world Constrained Multi-objective Optimization Problems (CMOPs) often contain multiple constraints, and understanding and utilizing the coupling between these constraints is crucial for solving CMOPs. However, existing Constrained Multi-objective Evolutionary Algorithms (CMOEAs) typically ignore these couplings and treat all constraints as a single aggregate, which lacks interpretability regarding the specific geometric roles of constraints. To address this limitation, we first analyze how different constraints interact and show that the final Constrained Pareto Front (CPF) depends not only on the Pareto fronts of individual constraints but also on the boundaries of infeasible regions. This insight implies that CMOPs with different coupling types must be solved from different search directions. Accordingly, we propose a novel algorithm named Decoupling Constraint from Two Directions (DCF2D). This method periodically detects constraint couplings and spawns an auxiliary population for each relevant constraint with an appropriate search direction. Extensive experiments on seven challenging CMOP benchmark suites and on a collection of real-world CMOPs demonstrate that DCF2D outperforms five state-of-the-art CMOEAs, including existing decoupling-based methods.
See the Forest and the Trees: A Synergistic Reasoning Framework for Knowledge-Based Visual Question Answering
Jul 23, 2025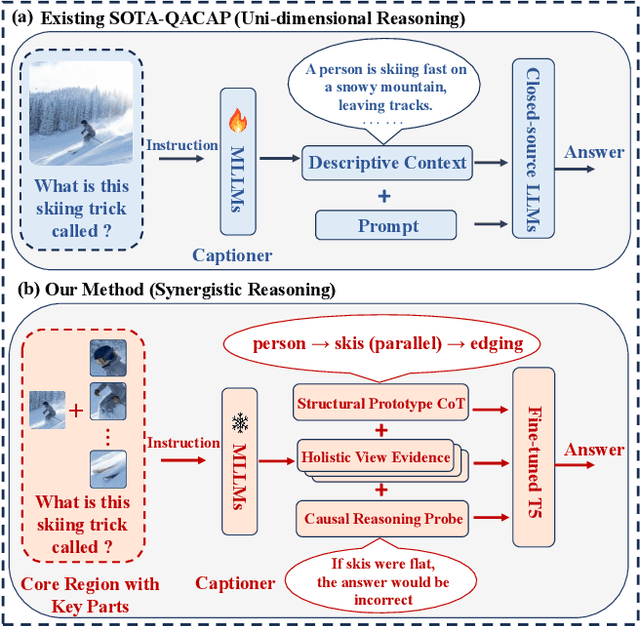



Multimodal Large Language Models (MLLMs) have pushed the frontiers of Knowledge-Based Visual Question Answering (KBVQA), yet their reasoning is fundamentally bottlenecked by a reliance on uni-dimensional evidence. This "seeing only the trees, but not the forest" approach prevents robust, multi-faceted understanding. Inspired by the principle of seeing both the forest and trees, we propose Synergos-VQA, a novel synergistic reasoning framework. At its core, Synergos-VQA concurrently generates and fuses three complementary evidence streams at inference time: (1) Holistic Evidence to perceive the entire scene (the "forest"), (2) Structural Evidence from a prototype-driven module to identify key objects (the "trees"), and (3) Causal Evidence from a counterfactual probe to ensure the reasoning is robustly grounded. By synergistically fusing this multi-faceted evidence, our framework achieves a more comprehensive and reliable reasoning process. Extensive experiments show that Synergos-VQA decisively establishes a new state-of-the-art on three challenging benchmarks, including OK-VQA and A-OKVQA. Furthermore, our approach demonstrates strong plug-and-play capabilities, significantly boosting various open-source MLLMs and proving that superior methodological design can outperform sheer model scale.
RemixFusion: Residual-based Mixed Representation for Large-scale Online RGB-D Reconstruction
Jul 23, 2025The introduction of the neural implicit representation has notably propelled the advancement of online dense reconstruction techniques. Compared to traditional explicit representations, such as TSDF, it improves the mapping completeness and memory efficiency. However, the lack of reconstruction details and the time-consuming learning of neural representations hinder the widespread application of neural-based methods to large-scale online reconstruction. We introduce RemixFusion, a novel residual-based mixed representation for scene reconstruction and camera pose estimation dedicated to high-quality and large-scale online RGB-D reconstruction. In particular, we propose a residual-based map representation comprised of an explicit coarse TSDF grid and an implicit neural module that produces residuals representing fine-grained details to be added to the coarse grid. Such mixed representation allows for detail-rich reconstruction with bounded time and memory budget, contrasting with the overly-smoothed results by the purely implicit representations, thus paving the way for high-quality camera tracking. Furthermore, we extend the residual-based representation to handle multi-frame joint pose optimization via bundle adjustment (BA). In contrast to the existing methods, which optimize poses directly, we opt to optimize pose changes. Combined with a novel technique for adaptive gradient amplification, our method attains better optimization convergence and global optimality. Furthermore, we adopt a local moving volume to factorize the mixed scene representation with a divide-and-conquer design to facilitate efficient online learning in our residual-based framework. Extensive experiments demonstrate that our method surpasses all state-of-the-art ones, including those based either on explicit or implicit representations, in terms of the accuracy of both mapping and tracking on large-scale scenes.
BoxFusion: Reconstruction-Free Open-Vocabulary 3D Object Detection via Real-Time Multi-View Box Fusion
Jun 18, 2025Open-vocabulary 3D object detection has gained significant interest due to its critical applications in autonomous driving and embodied AI. Existing detection methods, whether offline or online, typically rely on dense point cloud reconstruction, which imposes substantial computational overhead and memory constraints, hindering real-time deployment in downstream tasks. To address this, we propose a novel reconstruction-free online framework tailored for memory-efficient and real-time 3D detection. Specifically, given streaming posed RGB-D video input, we leverage Cubify Anything as a pre-trained visual foundation model (VFM) for single-view 3D object detection by bounding boxes, coupled with CLIP to capture open-vocabulary semantics of detected objects. To fuse all detected bounding boxes across different views into a unified one, we employ an association module for correspondences of multi-views and an optimization module to fuse the 3D bounding boxes of the same instance predicted in multi-views. The association module utilizes 3D Non-Maximum Suppression (NMS) and a box correspondence matching module, while the optimization module uses an IoU-guided efficient random optimization technique based on particle filtering to enforce multi-view consistency of the 3D bounding boxes while minimizing computational complexity. Extensive experiments on ScanNetV2 and CA-1M datasets demonstrate that our method achieves state-of-the-art performance among online methods. Benefiting from this novel reconstruction-free paradigm for 3D object detection, our method exhibits great generalization abilities in various scenarios, enabling real-time perception even in environments exceeding 1000 square meters.
Evolutionary training-free guidance in diffusion model for 3D multi-objective molecular generation
May 16, 2025Discovering novel 3D molecular structures that simultaneously satisfy multiple property targets remains a central challenge in materials and drug design. Although recent diffusion-based models can generate 3D conformations, they require expensive retraining for each new property or property-combination and lack flexibility in enforcing structural constraints. We introduce EGD (Evolutionary Guidance in Diffusion), a training-free framework that embeds evolutionary operators directly into the diffusion sampling process. By performing crossover on noise-perturbed samples and then denoising them with a pretrained Unconditional diffusion model, EGD seamlessly blends structural fragments and steers generation toward user-specified objectives without any additional model updates. On both single- and multi-target 3D conditional generation tasks-and on multi-objective optimization of quantum properties EGD outperforms state-of-the-art conditional diffusion methods in accuracy and runs up to five times faster per generation. In the single-objective optimization of protein ligands, EGD enables customized ligand generation. Moreover, EGD can embed arbitrary 3D fragments into the generated molecules while optimizing multiple conflicting properties in one unified process. This combination of efficiency, flexibility, and controllable structure makes EGD a powerful tool for rapid, guided exploration of chemical space.
Data Distribution Distilled Generative Model for Generalized Zero-Shot Recognition
Feb 18, 2024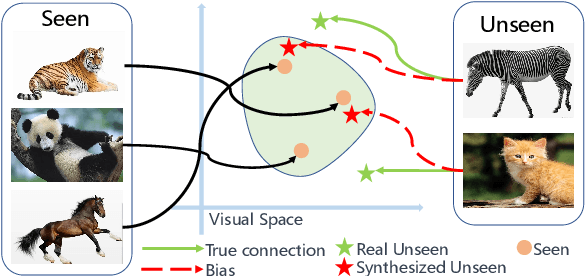
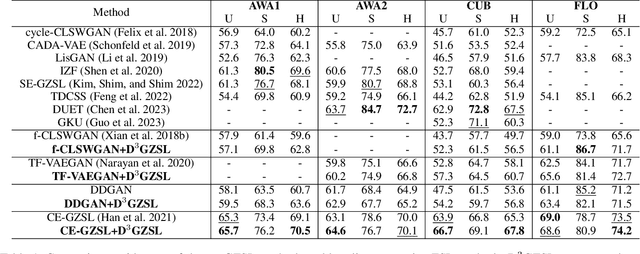
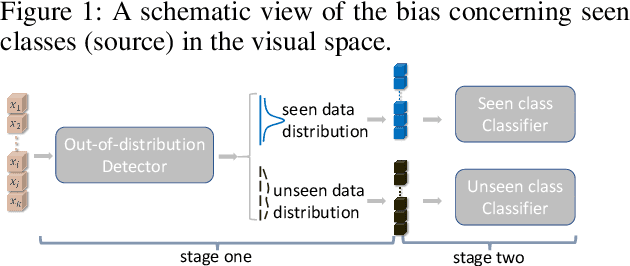

In the realm of Zero-Shot Learning (ZSL), we address biases in Generalized Zero-Shot Learning (GZSL) models, which favor seen data. To counter this, we introduce an end-to-end generative GZSL framework called D$^3$GZSL. This framework respects seen and synthesized unseen data as in-distribution and out-of-distribution data, respectively, for a more balanced model. D$^3$GZSL comprises two core modules: in-distribution dual space distillation (ID$^2$SD) and out-of-distribution batch distillation (O$^2$DBD). ID$^2$SD aligns teacher-student outcomes in embedding and label spaces, enhancing learning coherence. O$^2$DBD introduces low-dimensional out-of-distribution representations per batch sample, capturing shared structures between seen and unseen categories. Our approach demonstrates its effectiveness across established GZSL benchmarks, seamlessly integrating into mainstream generative frameworks. Extensive experiments consistently showcase that D$^3$GZSL elevates the performance of existing generative GZSL methods, underscoring its potential to refine zero-shot learning practices.The code is available at: https://github.com/PJBQ/D3GZSL.git
YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction
Jan 08, 2024



The difficulty of the information extraction task lies in dealing with the task-specific label schemas and heterogeneous data structures. Recent work has proposed methods based on large language models to uniformly model different information extraction tasks. However, these existing methods are deficient in their information extraction capabilities for Chinese languages other than English. In this paper, we propose an end-to-end chat-enhanced instruction tuning framework for universal information extraction (YAYI-UIE), which supports both Chinese and English. Specifically, we utilize dialogue data and information extraction data to enhance the information extraction performance jointly. Experimental results show that our proposed framework achieves state-of-the-art performance on Chinese datasets while also achieving comparable performance on English datasets under both supervised settings and zero-shot settings.