 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannian Multiplicative Update for Sparse Simplex constraint using oblique rotation manifold
Mar 31, 2025We propose a new manifold optimization method to solve low-rank problems with sparse simplex constraints (variables are simultaneous nonnegativity, sparsity, and sum-to-1) that are beneficial in applications. The proposed approach exploits oblique rotation manifolds, rewrite the problem, and introduce a new Riemannian optimization method. Experiments on synthetic datasets compared to the standard Euclidean method show the effectiveness of the proposed method.
Sparse Hyperparametric Itakura-Saito NMF via Bi-Level Optimization
Feb 25, 2025The selection of penalty hyperparameters is a critical aspect in Nonnegative Matrix Factorization (NMF), since these values control the trade-off between the reconstruction accuracy and the adherence to desired constraints. In this work, we focus on an NMF problem involving the Itakura-Saito (IS) divergence, effective for extracting low spectral density components from spectrograms of mixed signals, enhanced with sparsity constraints. We propose a new algorithm called SHINBO, which introduces a bi-level optimization framework to automatically and adaptively tune the row-dependent penalty hyperparameters, enhancing the ability of IS-NMF to isolate sparse, periodic signals against noise. Experimental results showed SHINBO ensures precise spectral decomposition and demonstrates superior performance in both synthetic and real-world applications. For the latter, SHINBO is particularly useful, as noninvasive vibration-based fault detection in rolling bearings, where the desired signal components often reside in high-frequency subbands but are obscured by stronger, spectrally broader noise. By addressing the critical issue of hyperparameter selection, SHINBO advances the state-of-the-art in signal recovery for complex, noise-dominated environments.
Sum-of-norms regularized Nonnegative Matrix Factorization
Jun 30, 2024
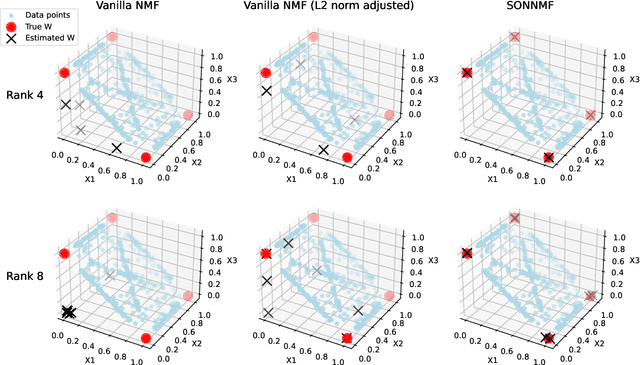

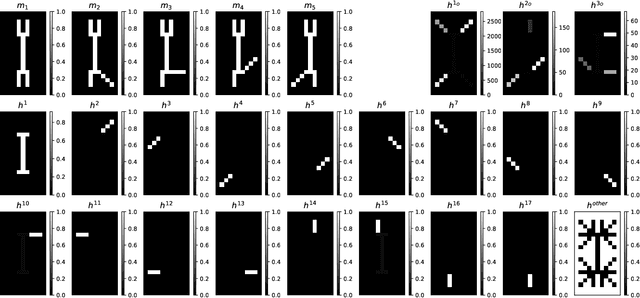
When applying nonnegative matrix factorization (NMF), generally the rank parameter is unknown. Such rank in NMF, called the nonnegative rank, is usually estimated heuristically since computing the exact value of it is NP-hard. In this work, we propose an approximation method to estimate such rank while solving NMF on-the-fly. We use sum-of-norm (SON), a group-lasso structure that encourages pairwise similarity, to reduce the rank of a factor matrix where the rank is overestimated at the beginning. On various datasets, SON-NMF is able to reveal the correct nonnegative rank of the data without any prior knowledge nor tuning. SON-NMF is a nonconvx nonsmmoth non-separable non-proximable problem, solving it is nontrivial. First, as rank estimation in NMF is NP-hard, the proposed approach does not enjoy a lower computational complexity. Using a graph-theoretic argument, we prove that the complexity of the SON-NMF is almost irreducible. Second, the per-iteration cost of any algorithm solving SON-NMF is possibly high, which motivated us to propose a first-order BCD algorithm to approximately solve SON-NMF with a low per-iteration cost, in which we do so by the proximal average operator. Lastly, we propose a simple greedy method for post-processing. SON-NMF exhibits favourable features for applications. Beside the ability to automatically estimate the rank from data, SON-NMF can deal with rank-deficient data matrix, can detect weak component with small energy. Furthermore, on the application of hyperspectral imaging, SON-NMF handle the issue of spectral variability naturally.
Inhomogeneous graph trend filtering via a l2,0 cardinality penalty
Apr 11, 2023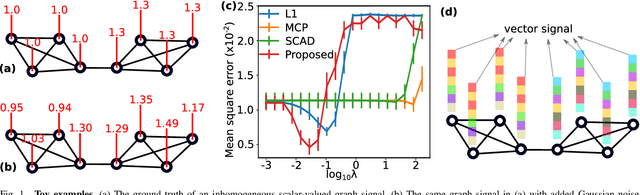
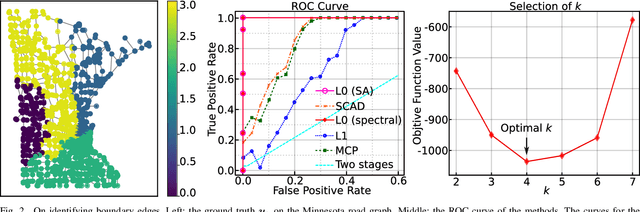
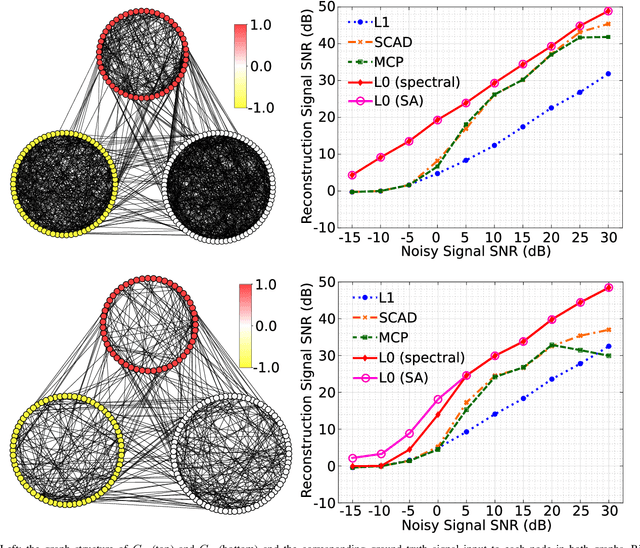

We study estimation of piecewise smooth signals over a graph. We propose a $\ell_{2,0}$-norm penalized Graph Trend Filtering (GTF) model to estimate piecewise smooth graph signals that exhibits inhomogeneous levels of smoothness across the nodes. We prove that the proposed GTF model is simultaneously a k-means clustering on the signal over the nodes and a minimum graph cut on the edges of the graph, where the clustering and the cut share the same assignment matrix. We propose two methods to solve the proposed GTF model: a spectral decomposition method and a method based on simulated annealing. In the experiment on synthetic and real-world datasets, we show that the proposed GTF model has a better performances compared with existing approaches on the tasks of denoising, support recovery and semi-supervised classification. We also show that the proposed GTF model can be solved more efficiently than existing models for the dataset with a large edge set.
Fast Projection onto the Capped Simplex with Applications to Sparse Regression in Bioinformatics
Oct 26, 2021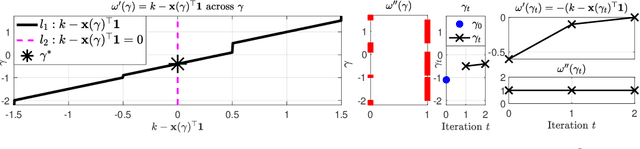
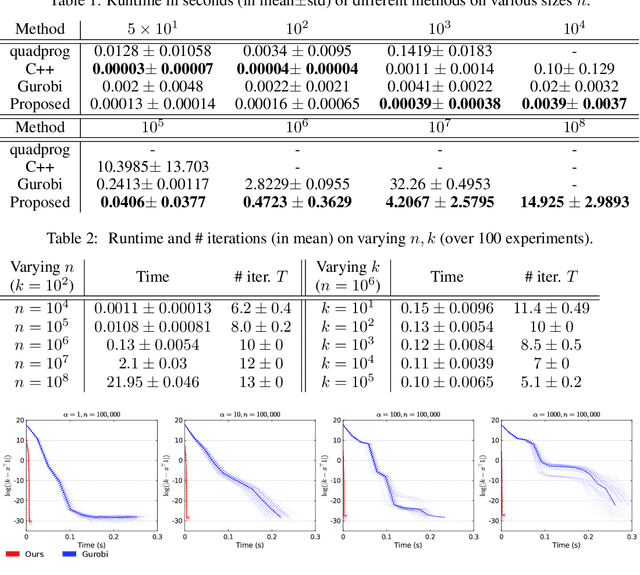
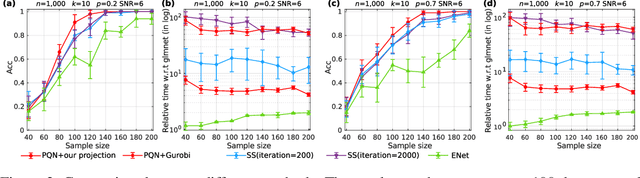
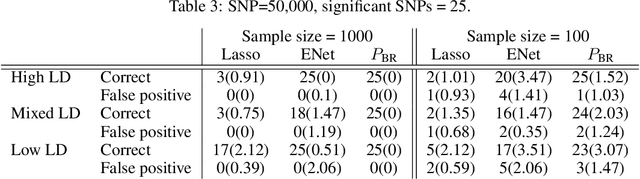
We consider the problem of projecting a vector onto the so-called k-capped simplex, which is a hyper-cube cut by a hyperplane. For an n-dimensional input vector with bounded elements, we found that a simple algorithm based on Newton's method is able to solve the projection problem to high precision with a complexity roughly about O(n), which has a much lower computational cost compared with the existing sorting-based methods proposed in the literature. We provide a theory for partial explanation and justification of the method. We demonstrate that the proposed algorithm can produce a solution of the projection problem with high precision on large scale datasets, and the algorithm is able to significantly outperform the state-of-the-art methods in terms of runtime (about 6-8 times faster than a commercial software with respect to CPU time for input vector with 1 million variables or more). We further illustrate the effectiveness of the proposed algorithm on solving sparse regression in a bioinformatics problem. Empirical results on the GWAS dataset (with 1,500,000 single-nucleotide polymorphisms) show that, when using the proposed method to accelerate the Projected Quasi-Newton (PQN) method, the accelerated PQN algorithm is able to handle huge-scale regression problem and it is more efficient (about 3-6 times faster) than the current state-of-the-art methods.