 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoxFusion: Reconstruction-Free Open-Vocabulary 3D Object Detection via Real-Time Multi-View Box Fusion
Jun 18, 2025Open-vocabulary 3D object detection has gained significant interest due to its critical applications in autonomous driving and embodied AI. Existing detection methods, whether offline or online, typically rely on dense point cloud reconstruction, which imposes substantial computational overhead and memory constraints, hindering real-time deployment in downstream tasks. To address this, we propose a novel reconstruction-free online framework tailored for memory-efficient and real-time 3D detection. Specifically, given streaming posed RGB-D video input, we leverage Cubify Anything as a pre-trained visual foundation model (VFM) for single-view 3D object detection by bounding boxes, coupled with CLIP to capture open-vocabulary semantics of detected objects. To fuse all detected bounding boxes across different views into a unified one, we employ an association module for correspondences of multi-views and an optimization module to fuse the 3D bounding boxes of the same instance predicted in multi-views. The association module utilizes 3D Non-Maximum Suppression (NMS) and a box correspondence matching module, while the optimization module uses an IoU-guided efficient random optimization technique based on particle filtering to enforce multi-view consistency of the 3D bounding boxes while minimizing computational complexity. Extensive experiments on ScanNetV2 and CA-1M datasets demonstrate that our method achieves state-of-the-art performance among online methods. Benefiting from this novel reconstruction-free paradigm for 3D object detection, our method exhibits great generalization abilities in various scenarios, enabling real-time perception even in environments exceeding 1000 square meters.
Generic Objects as Pose Probes for Few-Shot View Synthesis
Sep 01, 2024



Radiance fields including NeRFs and 3D Gaussians demonstrate great potential in high-fidelity rendering and scene reconstruction, while they require a substantial number of posed images as inputs. COLMAP is frequently employed for preprocessing to estimate poses, while it necessitates a large number of feature matches to operate effectively, and it struggles with scenes characterized by sparse features, large baselines between images, or a limited number of input images. We aim to tackle few-view NeRF reconstruction using only 3 to 6 unposed scene images. Traditional methods often use calibration boards but they are not common in images. We propose a novel idea of utilizing everyday objects, commonly found in both images and real life, as "pose probes". The probe object is automatically segmented by SAM, whose shape is initialized from a cube. We apply a dual-branch volume rendering optimization (object NeRF and scene NeRF) to constrain the pose optimization and jointly refine the geometry. Specifically, object poses of two views are first estimated by PnP matching in an SDF representation, which serves as initial poses. PnP matching, requiring only a few features, is suitable for feature-sparse scenes. Additional views are incrementally incorporated to refine poses from preceding views. In experiments, PoseProbe achieves state-of-the-art performance in both pose estimation and novel view synthesis across multiple datasets. We demonstrate its effectiveness, particularly in few-view and large-baseline scenes where COLMAP struggles. In ablations, using different objects in a scene yields comparable performance. Our project page is available at: \href{https://zhirui-gao.github.io/PoseProbe.github.io/}{this https URL}
Learning Part-aware 3D Representations by Fusing 2D Gaussians and Superquadrics
Aug 20, 2024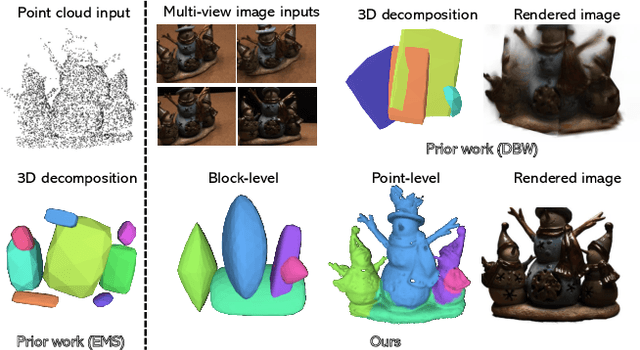

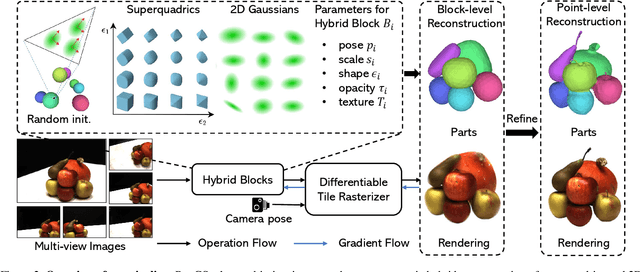
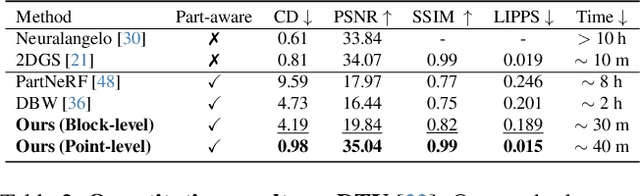
Low-level 3D representations, such as point clouds, meshes, NeRFs, and 3D Gaussians, are commonly used to represent 3D objects or scenes. However, humans usually perceive 3D objects or scenes at a higher level as a composition of parts or structures rather than points or voxels. Representing 3D as semantic parts can benefit further understanding and applications. We aim to solve part-aware 3D reconstruction, which parses objects or scenes into semantic parts. In this paper, we introduce a hybrid representation of superquadrics and 2D Gaussians, trying to dig 3D structural clues from multi-view image inputs. Accurate structured geometry reconstruction and high-quality rendering are achieved at the same time. We incorporate parametric superquadrics in mesh forms into 2D Gaussians by attaching Gaussian centers to faces in meshes. During the training, superquadrics parameters are iteratively optimized, and Gaussians are deformed accordingly, resulting in an efficient hybrid representation. On the one hand, this hybrid representation inherits the advantage of superquadrics to represent different shape primitives, supporting flexible part decomposition of scenes. On the other hand, 2D Gaussians are incorporated to model the complex texture and geometry details, ensuring high-quality rendering and geometry reconstruction. The reconstruction is fully unsupervised. We conduct extensive experiments on data from DTU and ShapeNet datasets, in which the method decomposes scenes into reasonable parts, outperforming existing state-of-the-art approaches.
2D3D-MATR: 2D-3D Matching Transformer for Detection-free Registration between Images and Point Clouds
Aug 14, 2023The commonly adopted detect-then-match approach to registration finds difficulties in the cross-modality cases due to the incompatible keypoint detection and inconsistent feature description. We propose, 2D3D-MATR, a detection-free method for accurate and robust registration between images and point clouds. Our method adopts a coarse-to-fine pipeline where it first computes coarse correspondences between downsampled patches of the input image and the point cloud and then extends them to form dense correspondences between pixels and points within the patch region. The coarse-level patch matching is based on transformer which jointly learns global contextual constraints with self-attention and cross-modality correlations with cross-attention. To resolve the scale ambiguity in patch matching, we construct a multi-scale pyramid for each image patch and learn to find for each point patch the best matching image patch at a proper resolution level. Extensive experiments on two public benchmarks demonstrate that 2D3D-MATR outperforms the previous state-of-the-art P2-Net by around $20$ percentage points on inlier ratio and over $10$ points on registration recall. Our code and models are available at https://github.com/minhaolee/2D3DMATR.
Delving into Crispness: Guided Label Refinement for Crisp Edge Detection
Jun 27, 2023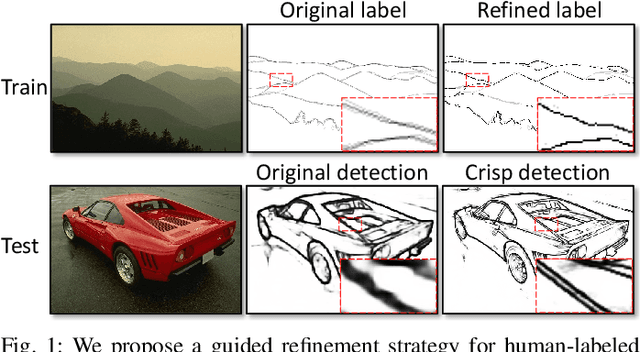
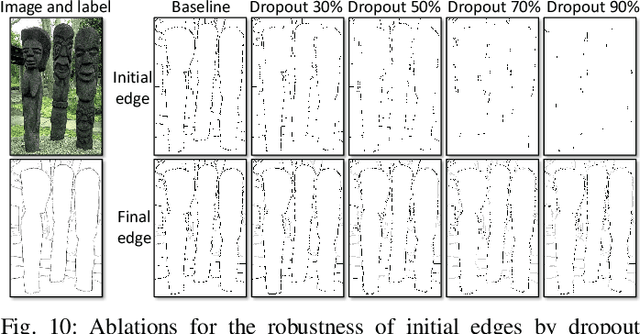


Learning-based edge detection usually suffers from predicting thick edges. Through extensive quantitative study with a new edge crispness measure, we find that noisy human-labeled edges are the main cause of thick predictions. Based on this observation, we advocate that more attention should be paid on label quality than on model design to achieve crisp edge detection. To this end, we propose an effective Canny-guided refinement of human-labeled edges whose result can be used to train crisp edge detectors. Essentially, it seeks for a subset of over-detected Canny edges that best align human labels. We show that several existing edge detectors can be turned into a crisp edge detector through training on our refined edge maps. Experiments demonstrate that deep models trained with refined edges achieve significant performance boost of crispness from 17.4% to 30.6%. With the PiDiNet backbone, our method improves ODS and OIS by 12.2% and 12.6% on the Multicue dataset, respectively, without relying on non-maximal suppression. We further conduct experiments and show the superiority of our crisp edge detection for optical flow estimation and image segmentation.
NEF: Neural Edge Fields for 3D Parametric Curve Reconstruction from Multi-view Images
Mar 16, 2023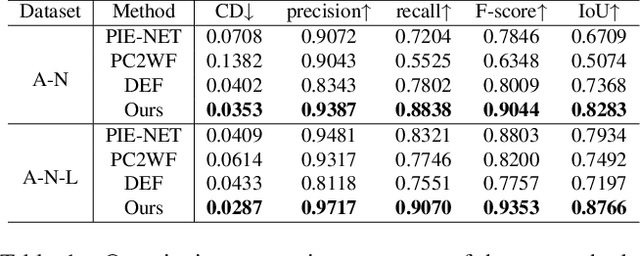
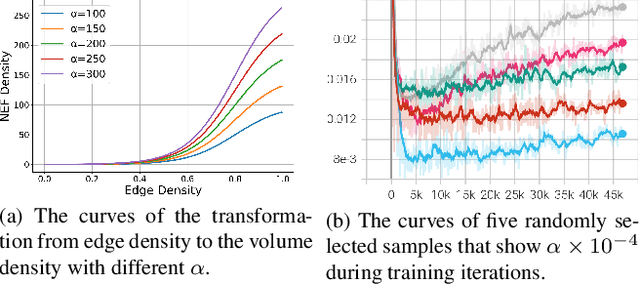
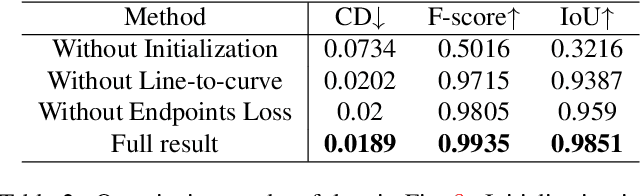
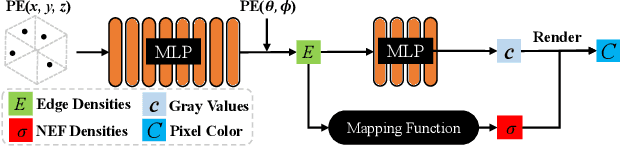
We study the problem of reconstructing 3D feature curves of an object from a set of calibrated multi-view images. To do so, we learn a neural implicit field representing the density distribution of 3D edges which we refer to as Neural Edge Field (NEF). Inspired by NeRF, NEF is optimized with a view-based rendering loss where a 2D edge map is rendered at a given view and is compared to the ground-truth edge map extracted from the image of that view. The rendering-based differentiable optimization of NEF fully exploits 2D edge detection, without needing a supervision of 3D edges, a 3D geometric operator or cross-view edge correspondence. Several technical designs are devised to ensure learning a range-limited and view-independent NEF for robust edge extraction. The final parametric 3D curves are extracted from NEF with an iterative optimization method. On our benchmark with synthetic data, we demonstrate that NEF outperforms existing state-of-the-art methods on all metrics. Project page: https://yunfan1202.github.io/NEF/.
Learning Accurate Template Matching with Differentiable Coarse-to-Fine Correspondence Refinement
Mar 15, 2023Template matching is a fundamental task in computer vision and has been studied for decades. It plays an essential role in manufacturing industry for estimating the poses of different parts, facilitating downstream tasks such as robotic grasping. Existing methods fail when the template and source images have different modalities, cluttered backgrounds or weak textures. They also rarely consider geometric transformations via homographies, which commonly exist even for planar industrial parts. To tackle the challenges, we propose an accurate template matching method based on differentiable coarse-to-fine correspondence refinement. We use an edge-aware module to overcome the domain gap between the mask template and the grayscale image, allowing robust matching. An initial warp is estimated using coarse correspondences based on novel structure-aware information provided by transformers. This initial alignment is passed to a refinement network using references and aligned images to obtain sub-pixel level correspondences which are used to give the final geometric transformation. Extensive evaluation shows that our method is significantly better than state-of-the-art methods and baselines, providing good generalization ability and visually plausible results even on unseen real data.