 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemixFusion: Residual-based Mixed Representation for Large-scale Online RGB-D Reconstruction
Jul 23, 2025The introduction of the neural implicit representation has notably propelled the advancement of online dense reconstruction techniques. Compared to traditional explicit representations, such as TSDF, it improves the mapping completeness and memory efficiency. However, the lack of reconstruction details and the time-consuming learning of neural representations hinder the widespread application of neural-based methods to large-scale online reconstruction. We introduce RemixFusion, a novel residual-based mixed representation for scene reconstruction and camera pose estimation dedicated to high-quality and large-scale online RGB-D reconstruction. In particular, we propose a residual-based map representation comprised of an explicit coarse TSDF grid and an implicit neural module that produces residuals representing fine-grained details to be added to the coarse grid. Such mixed representation allows for detail-rich reconstruction with bounded time and memory budget, contrasting with the overly-smoothed results by the purely implicit representations, thus paving the way for high-quality camera tracking. Furthermore, we extend the residual-based representation to handle multi-frame joint pose optimization via bundle adjustment (BA). In contrast to the existing methods, which optimize poses directly, we opt to optimize pose changes. Combined with a novel technique for adaptive gradient amplification, our method attains better optimization convergence and global optimality. Furthermore, we adopt a local moving volume to factorize the mixed scene representation with a divide-and-conquer design to facilitate efficient online learning in our residual-based framework. Extensive experiments demonstrate that our method surpasses all state-of-the-art ones, including those based either on explicit or implicit representations, in terms of the accuracy of both mapping and tracking on large-scale scenes.
Angio-Diff: Learning a Self-Supervised Adversarial Diffusion Model for Angiographic Geometry Generation
Jun 24, 2025Vascular diseases pose a significant threat to human health, with X-ray angiography established as the gold standard for diagnosis, allowing for detailed observation of blood vessels. However, angiographic X-rays expose personnel and patients to higher radiation levels than non-angiographic X-rays, which are unwanted. Thus, modality translation from non-angiographic to angiographic X-rays is desirable. Data-driven deep approaches are hindered by the lack of paired large-scale X-ray angiography datasets. While making high-quality vascular angiography synthesis crucial, it remains challenging. We find that current medical image synthesis primarily operates at pixel level and struggles to adapt to the complex geometric structure of blood vessels, resulting in unsatisfactory quality of blood vessel image synthesis, such as disconnections or unnatural curvatures. To overcome this issue, we propose a self-supervised method via diffusion models to transform non-angiographic X-rays into angiographic X-rays, mitigating data shortages for data-driven approaches. Our model comprises a diffusion model that learns the distribution of vascular data from diffusion latent, a generator for vessel synthesis, and a mask-based adversarial module. To enhance geometric accuracy, we propose a parametric vascular model to fit the shape and distribution of blood vessels. The proposed method contributes a pipeline and a synthetic dataset for X-ray angiography. We conducted extensive comparative and ablation experiments to evaluate the Angio-Diff. The results demonstrate that our method achieves state-of-the-art performance in synthetic angiography image quality and more accurately synthesizes the geometric structure of blood vessels. The code is available at https://github.com/zfw-cv/AngioDiff.
BoxFusion: Reconstruction-Free Open-Vocabulary 3D Object Detection via Real-Time Multi-View Box Fusion
Jun 18, 2025Open-vocabulary 3D object detection has gained significant interest due to its critical applications in autonomous driving and embodied AI. Existing detection methods, whether offline or online, typically rely on dense point cloud reconstruction, which imposes substantial computational overhead and memory constraints, hindering real-time deployment in downstream tasks. To address this, we propose a novel reconstruction-free online framework tailored for memory-efficient and real-time 3D detection. Specifically, given streaming posed RGB-D video input, we leverage Cubify Anything as a pre-trained visual foundation model (VFM) for single-view 3D object detection by bounding boxes, coupled with CLIP to capture open-vocabulary semantics of detected objects. To fuse all detected bounding boxes across different views into a unified one, we employ an association module for correspondences of multi-views and an optimization module to fuse the 3D bounding boxes of the same instance predicted in multi-views. The association module utilizes 3D Non-Maximum Suppression (NMS) and a box correspondence matching module, while the optimization module uses an IoU-guided efficient random optimization technique based on particle filtering to enforce multi-view consistency of the 3D bounding boxes while minimizing computational complexity. Extensive experiments on ScanNetV2 and CA-1M datasets demonstrate that our method achieves state-of-the-art performance among online methods. Benefiting from this novel reconstruction-free paradigm for 3D object detection, our method exhibits great generalization abilities in various scenarios, enabling real-time perception even in environments exceeding 1000 square meters.
VasTSD: Learning 3D Vascular Tree-state Space Diffusion Model for Angiography Synthesis
Mar 17, 2025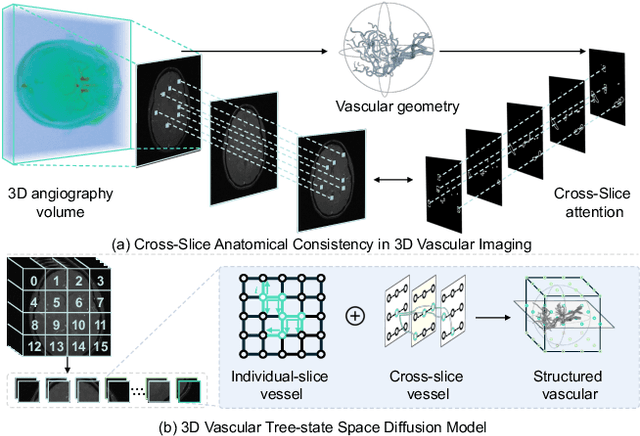



Angiography imaging is a medical imaging technique that enhances the visibility of blood vessels within the body by using contrast agents. Angiographic images can effectively assist in the diagnosis of vascular diseases. However, contrast agents may bring extra radiation exposure which is harmful to patients with health risks. To mitigate these concerns, in this paper, we aim to automatically generate angiography from non-angiographic inputs, by leveraging and enhancing the inherent physical properties of vascular structures. Previous methods relying on 2D slice-based angiography synthesis struggle with maintaining continuity in 3D vascular structures and exhibit limited effectiveness across different imaging modalities. We propose VasTSD, a 3D vascular tree-state space diffusion model to synthesize angiography from 3D non-angiographic volumes, with a novel state space serialization approach that dynamically constructs vascular tree topologies, integrating these with a diffusion-based generative model to ensure the generation of anatomically continuous vasculature in 3D volumes. A pre-trained vision embedder is employed to construct vascular state space representations, enabling consistent modeling of vascular structures across multiple modalities. Extensive experiments on various angiographic datasets demonstrate the superiority of VasTSD over prior works, achieving enhanced continuity of blood vessels in synthesized angiographic synthesis for multiple modalities and anatomical regions.
CAD-NeRF: Learning NeRFs from Uncalibrated Few-view Images by CAD Model Retrieval
Nov 05, 2024Reconstructing from multi-view images is a longstanding problem in 3D vision, where neural radiance fields (NeRFs) have shown great potential and get realistic rendered images of novel views. Currently, most NeRF methods either require accurate camera poses or a large number of input images, or even both. Reconstructing NeRF from few-view images without poses is challenging and highly ill-posed. To address this problem, we propose CAD-NeRF, a method reconstructed from less than 10 images without any known poses. Specifically, we build a mini library of several CAD models from ShapeNet and render them from many random views. Given sparse-view input images, we run a model and pose retrieval from the library, to get a model with similar shapes, serving as the density supervision and pose initializations. Here we propose a multi-view pose retrieval method to avoid pose conflicts among views, which is a new and unseen problem in uncalibrated NeRF methods. Then, the geometry of the object is trained by the CAD guidance. The deformation of the density field and camera poses are optimized jointly. Then texture and density are trained and fine-tuned as well. All training phases are in self-supervised manners. Comprehensive evaluations of synthetic and real images show that CAD-NeRF successfully learns accurate densities with a large deformation from retrieved CAD models, showing the generalization abilities.
Generic Objects as Pose Probes for Few-Shot View Synthesis
Sep 01, 2024



Radiance fields including NeRFs and 3D Gaussians demonstrate great potential in high-fidelity rendering and scene reconstruction, while they require a substantial number of posed images as inputs. COLMAP is frequently employed for preprocessing to estimate poses, while it necessitates a large number of feature matches to operate effectively, and it struggles with scenes characterized by sparse features, large baselines between images, or a limited number of input images. We aim to tackle few-view NeRF reconstruction using only 3 to 6 unposed scene images. Traditional methods often use calibration boards but they are not common in images. We propose a novel idea of utilizing everyday objects, commonly found in both images and real life, as "pose probes". The probe object is automatically segmented by SAM, whose shape is initialized from a cube. We apply a dual-branch volume rendering optimization (object NeRF and scene NeRF) to constrain the pose optimization and jointly refine the geometry. Specifically, object poses of two views are first estimated by PnP matching in an SDF representation, which serves as initial poses. PnP matching, requiring only a few features, is suitable for feature-sparse scenes. Additional views are incrementally incorporated to refine poses from preceding views. In experiments, PoseProbe achieves state-of-the-art performance in both pose estimation and novel view synthesis across multiple datasets. We demonstrate its effectiveness, particularly in few-view and large-baseline scenes where COLMAP struggles. In ablations, using different objects in a scene yields comparable performance. Our project page is available at: \href{https://zhirui-gao.github.io/PoseProbe.github.io/}{this https URL}
Learning Part-aware 3D Representations by Fusing 2D Gaussians and Superquadrics
Aug 20, 2024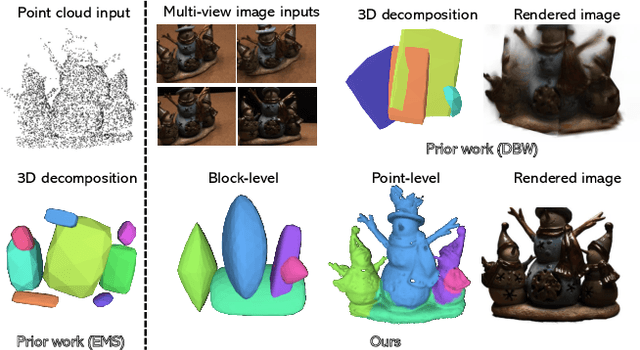

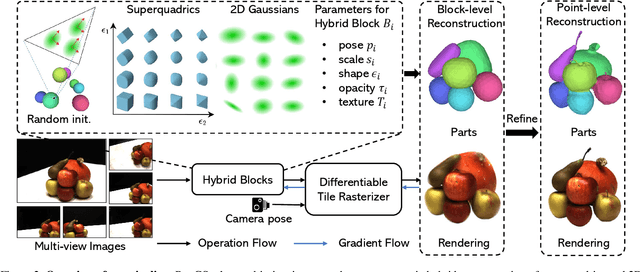
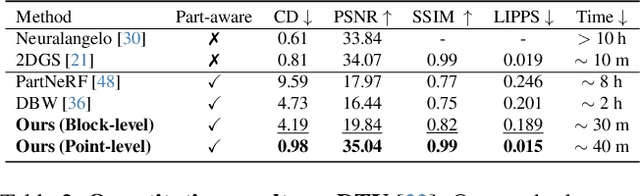
Low-level 3D representations, such as point clouds, meshes, NeRFs, and 3D Gaussians, are commonly used to represent 3D objects or scenes. However, humans usually perceive 3D objects or scenes at a higher level as a composition of parts or structures rather than points or voxels. Representing 3D as semantic parts can benefit further understanding and applications. We aim to solve part-aware 3D reconstruction, which parses objects or scenes into semantic parts. In this paper, we introduce a hybrid representation of superquadrics and 2D Gaussians, trying to dig 3D structural clues from multi-view image inputs. Accurate structured geometry reconstruction and high-quality rendering are achieved at the same time. We incorporate parametric superquadrics in mesh forms into 2D Gaussians by attaching Gaussian centers to faces in meshes. During the training, superquadrics parameters are iteratively optimized, and Gaussians are deformed accordingly, resulting in an efficient hybrid representation. On the one hand, this hybrid representation inherits the advantage of superquadrics to represent different shape primitives, supporting flexible part decomposition of scenes. On the other hand, 2D Gaussians are incorporated to model the complex texture and geometry details, ensuring high-quality rendering and geometry reconstruction. The reconstruction is fully unsupervised. We conduct extensive experiments on data from DTU and ShapeNet datasets, in which the method decomposes scenes into reasonable parts, outperforming existing state-of-the-art approaches.
DISCO: Efficient Diffusion Solver for Large-Scale Combinatorial Optimization Problems
Jun 28, 2024Combinatorial Optimization (CO) problems are fundamentally crucial in numerous practical applications across diverse industries, characterized by entailing enormous solution space and demanding time-sensitive response. Despite significant advancements made by recent neural solvers, their limited expressiveness does not conform well to the multi-modal nature of CO landscapes. While some research has pivoted towards diffusion models, they require simulating a Markov chain with many steps to produce a sample, which is time-consuming and does not meet the efficiency requirement of real applications, especially at scale. We propose DISCO, an efficient DIffusion Solver for Combinatorial Optimization problems that excels in both solution quality and inference speed. DISCO's efficacy is two-pronged: Firstly, it achieves rapid denoising of solutions through an analytically solvable form, allowing for direct sampling from the solution space with very few reverse-time steps, thereby drastically reducing inference time. Secondly, DISCO enhances solution quality by restricting the sampling space to a more constrained, meaningful domain guided by solution residues, while still preserving the inherent multi-modality of the output probabilistic distributions. DISCO achieves state-of-the-art results on very large Traveling Salesman Problems with 10000 nodes and challenging Maximal Independent Set benchmarks, with its per-instance denoising time up to 44.8 times faster. Through further combining a divide-and-conquer strategy, DISCO can be generalized to solve arbitrary-scale problem instances off the shelf, even outperforming models trained specifically on corresponding scales.
Relighting Scenes with Object Insertions in Neural Radiance Fields
Jun 21, 2024The insertion of objects into a scene and relighting are commonly utilized applications in augmented reality (AR). Previous methods focused on inserting virtual objects using CAD models or real objects from single-view images, resulting in highly limited AR application scenarios. We propose a novel NeRF-based pipeline for inserting object NeRFs into scene NeRFs, enabling novel view synthesis and realistic relighting, supporting physical interactions like casting shadows onto each other, from two sets of images depicting the object and scene. The lighting environment is in a hybrid representation of Spherical Harmonics and Spherical Gaussians, representing both high- and low-frequency lighting components very well, and supporting non-Lambertian surfaces. Specifically, we leverage the benefits of volume rendering and introduce an innovative approach for efficient shadow rendering by comparing the depth maps between the camera view and the light source view and generating vivid soft shadows. The proposed method achieves realistic relighting effects in extensive experimental evaluations.
NeRF-Guided Unsupervised Learning of RGB-D Registration
May 01, 2024



This paper focuses on training a robust RGB-D registration model without ground-truth pose supervision. Existing methods usually adopt a pairwise training strategy based on differentiable rendering, which enforces the photometric and the geometric consistency between the two registered frames as supervision. However, this frame-to-frame framework suffers from poor multi-view consistency due to factors such as lighting changes, geometry occlusion and reflective materials. In this paper, we present NeRF-UR, a novel frame-to-model optimization framework for unsupervised RGB-D registration. Instead of frame-to-frame consistency, we leverage the neural radiance field (NeRF) as a global model of the scene and use the consistency between the input and the NeRF-rerendered frames for pose optimization. This design can significantly improve the robustness in scenarios with poor multi-view consistency and provides better learning signal for the registration model. Furthermore, to bootstrap the NeRF optimization, we create a synthetic dataset, Sim-RGBD, through a photo-realistic simulator to warm up the registration model. By first training the registration model on Sim-RGBD and later unsupervisedly fine-tuning on real data, our framework enables distilling the capability of feature extraction and registration from simulation to reality. Our method outperforms the state-of-the-art counterparts on two popular indoor RGB-D datasets, ScanNet and 3DMatch. Code and models will be released for paper reproduction.