 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Efficient Membership Inference Attacks against Federated Large Language Models: A Projection Residual Approach
Apr 23, 2026Federated Large Language Models (FedLLMs) enable multiple parties to collaboratively fine-tune LLMs without sharing raw data, addressing challenges of limited resources and privacy concerns. Despite data localization, shared gradients can still expose sensitive information through membership inference attacks (MIAs). However, FedLLMs' unique properties, i.e. massive parameter scales, rapid convergence, and sparse, non-orthogonal gradients, render existing MIAs ineffective. To address this gap, we propose ProjRes, the first projection residuals-based passive MIA tailored for FedLLMs. ProjRes leverages hidden embedding vectors as sample representations and analyzes their projection residuals on the gradient subspace to uncover the intrinsic link between gradients and inputs. It requires no shadow models, auxiliary classifiers, or historical updates, ensuring efficiency and robustness. Experiments on four benchmarks and four LLMs show that ProjRes achieves near 100% accuracy, outperforming prior methods by up to 75.75%, and remains effective even under strong differential privacy defenses. Our findings reveal a previously overlooked privacy vulnerability in FedLLMs and call for a re-examination of their security assumptions. Our code and data are available at $\href{https://anonymous.4open.science/r/Passive-MIA-5268}{link}$.
StyleGallery: Training-free and Semantic-aware Personalized Style Transfer from Arbitrary Image References
Mar 12, 2026Despite the advancements in diffusion-based image style transfer, existing methods are commonly limited by 1) semantic gap: the style reference could miss proper content semantics, causing uncontrollable stylization; 2) reliance on extra constraints (e.g., semantic masks) restricting applicability; 3) rigid feature associations lacking adaptive global-local alignment, failing to balance fine-grained stylization and global content preservation. These limitations, particularly the inability to flexibly leverage style inputs, fundamentally restrict style transfer in terms of personalization, accuracy, and adaptability. To address these, we propose StyleGallery, a training-free and semantic-aware framework that supports arbitrary reference images as input and enables effective personalized customization. It comprises three core stages: semantic region segmentation (adaptive clustering on latent diffusion features to divide regions without extra inputs); clustered region matching (block filtering on extracted features for precise alignment); and style transfer optimization (energy function-guided diffusion sampling with regional style loss to optimize stylization). Experiments on our introduced benchmark demonstrate that StyleGallery outperforms state-of-the-art methods in content structure preservation, regional stylization, interpretability, and personalized customization, particularly when leveraging multiple style references.
HOCA-Bench: Beyond Semantic Perception to Predictive World Modeling via Hegelian Ontological-Causal Anomalies
Feb 23, 2026Video-LLMs have improved steadily on semantic perception, but they still fall short on predictive world modeling, which is central to physically grounded intelligence. We introduce HOCA-Bench, a benchmark that frames physical anomalies through a Hegelian lens. HOCA-Bench separates anomalies into two types: ontological anomalies, where an entity violates its own definition or persistence, and causal anomalies, where interactions violate physical relations. Using state-of-the-art generative video models as adversarial simulators, we build a testbed of 1,439 videos (3,470 QA pairs). Evaluations on 17 Video-LLMs show a clear cognitive lag: models often identify static ontological violations (e.g., shape mutations) but struggle with causal mechanisms (e.g., gravity or friction), with performance dropping by more than 20% on causal tasks. System-2 "Thinking" modes improve reasoning, but they do not close the gap, suggesting that current architectures recognize visual patterns more readily than they apply basic physical laws.
RAG-Adapter: A Plug-and-Play RAG-enhanced Framework for Long Video Understanding
Mar 11, 2025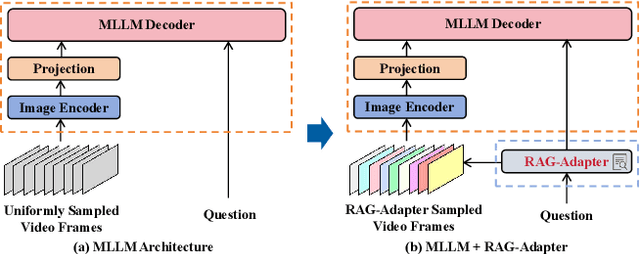
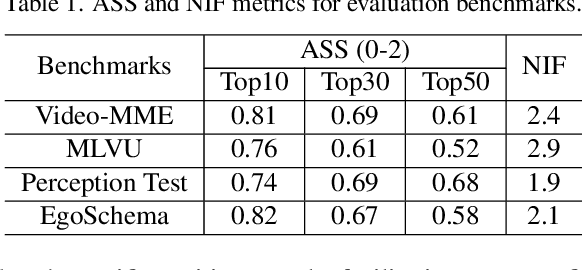
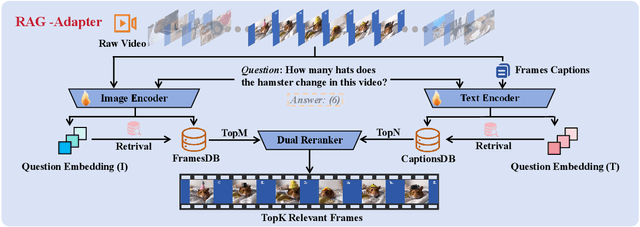
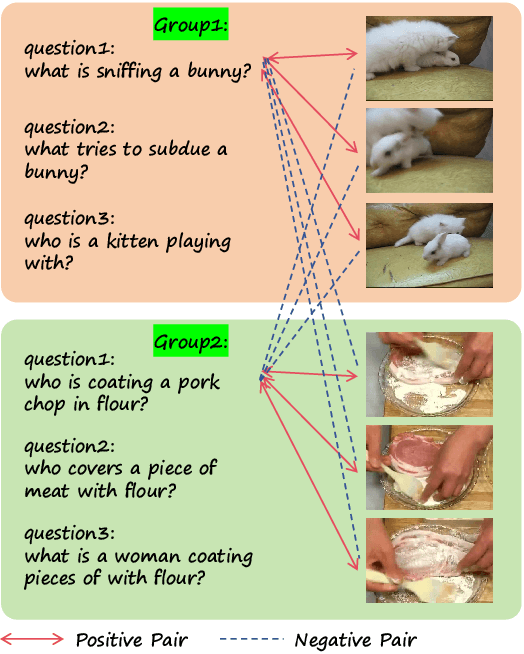
Multi-modal Large Language Models (MLLMs) capable of video understanding are advancing rapidly. To effectively assess their video comprehension capabilities, long video understanding benchmarks, such as Video-MME and MLVU, are proposed. However, these benchmarks directly use uniform frame sampling for testing, which results in significant information loss and affects the accuracy of the evaluations in reflecting the true abilities of MLLMs. To address this, we propose RAG-Adapter, a plug-and-play framework that reduces information loss during testing by sampling frames most relevant to the given question. Additionally, we introduce a Grouped-supervised Contrastive Learning (GCL) method to further enhance sampling effectiveness of RAG-Adapter through fine-tuning on our constructed MMAT dataset. Finally, we test numerous baseline MLLMs on various video understanding benchmarks, finding that RAG-Adapter sampling consistently outperforms uniform sampling (e.g., Accuracy of GPT-4o increases by 9.3 percent on Video-MME), providing a more accurate testing method for long video benchmarks.
ALLVB: All-in-One Long Video Understanding Benchmark
Mar 10, 2025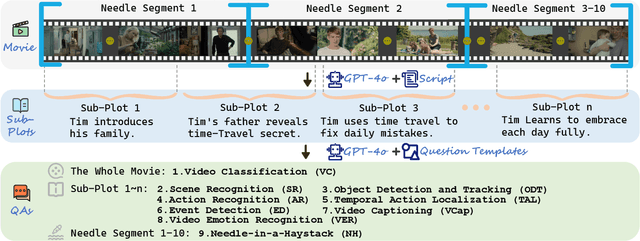
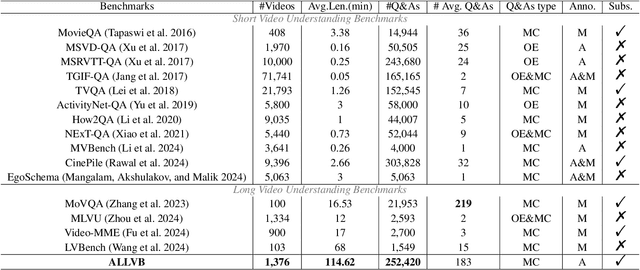
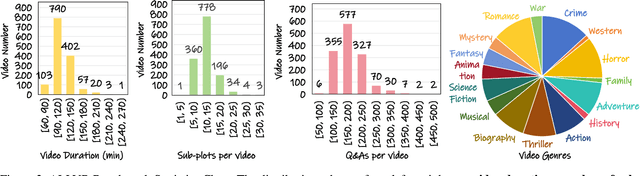
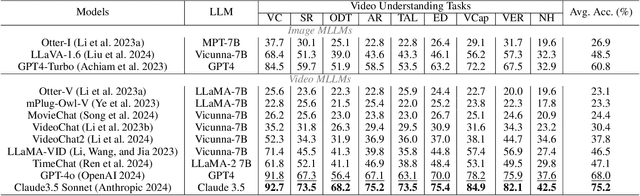
From image to video understanding, the capabilities of Multi-modal LLMs (MLLMs) are increasingly powerful. However, most existing video understanding benchmarks are relatively short, which makes them inadequate for effectively evaluating the long-sequence modeling capabilities of MLLMs. This highlights the urgent need for a comprehensive and integrated long video understanding benchmark to assess the ability of MLLMs thoroughly. To this end, we propose ALLVB (ALL-in-One Long Video Understanding Benchmark). ALLVB's main contributions include: 1) It integrates 9 major video understanding tasks. These tasks are converted into video QA formats, allowing a single benchmark to evaluate 9 different video understanding capabilities of MLLMs, highlighting the versatility, comprehensiveness, and challenging nature of ALLVB. 2) A fully automated annotation pipeline using GPT-4o is designed, requiring only human quality control, which facilitates the maintenance and expansion of the benchmark. 3) It contains 1,376 videos across 16 categories, averaging nearly 2 hours each, with a total of 252k QAs. To the best of our knowledge, it is the largest long video understanding benchmark in terms of the number of videos, average duration, and number of QAs. We have tested various mainstream MLLMs on ALLVB, and the results indicate that even the most advanced commercial models have significant room for improvement. This reflects the benchmark's challenging nature and demonstrates the substantial potential for development in long video understanding.
MetaTrading: An Immersion-Aware Model Trading Framework for Vehicular Metaverse Services
Oct 25, 2024
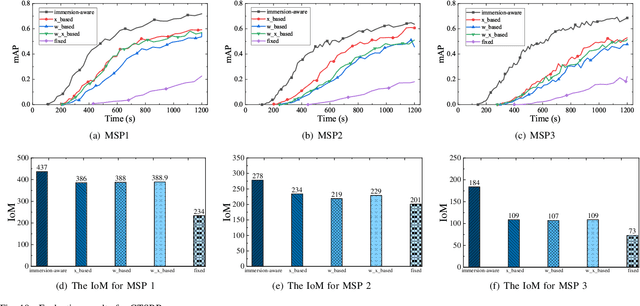
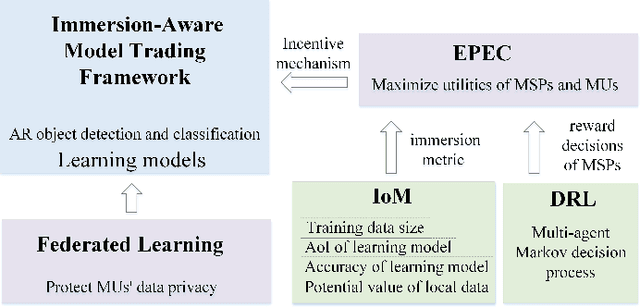
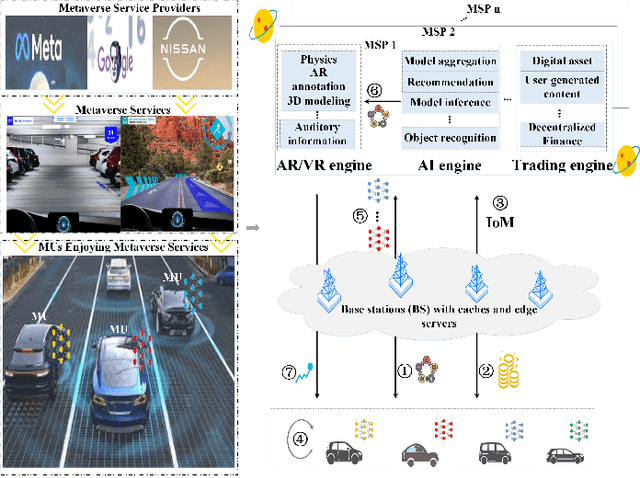
Updates of extensive Internet of Things (IoT) data are critical to the immersion of vehicular metaverse services. However, providing high-quality and sustainable data in unstable and resource-constrained vehicular networks remains a significant challenge. To address this problem, we put forth a novel immersion-aware model trading framework that incentivizes metaverse users (MUs) to contribute learning models trained by their latest local data for augmented reality (AR) services in the vehicular metaverse, while preserving their privacy through federated learning. To comprehensively evaluate the contribution of locally trained learning models provided by MUs to AR services, we design a new immersion metric that captures service immersion by considering the freshness and accuracy of learning models, as well as the amount and potential value of raw data used for training. We model the trading interactions between metaverse service providers (MSPs) and MUs as an equilibrium problem with equilibrium constraints (EPEC) to analyze and balance their costs and gains. Moreover, considering dynamic network conditions and privacy concerns, we formulate the reward decisions of MSPs as a multi-agent Markov decision process. Then, a fully distributed dynamic reward method based on deep reinforcement learning is presented, which operates without any private information about MUs and other MSPs. Experimental results demonstrate that the proposed framework can effectively provide higher-value models for object detection and classification in AR services on real AR-related vehicle datasets compared to benchmark schemes.
DiffusionEdge: Diffusion Probabilistic Model for Crisp Edge Detection
Jan 09, 2024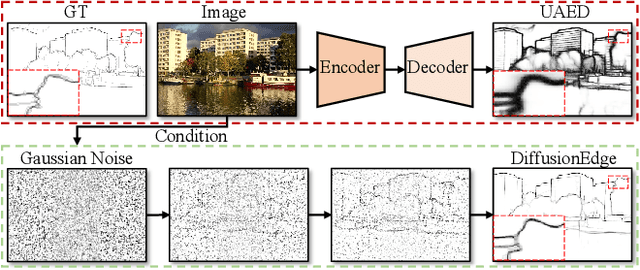

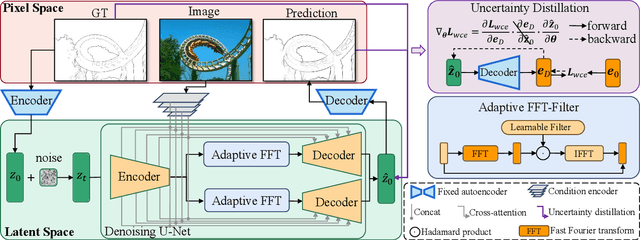
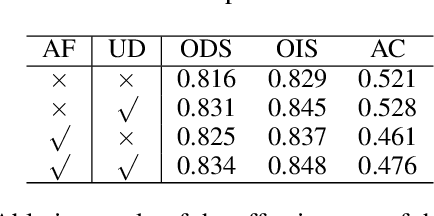
Limited by the encoder-decoder architecture, learning-based edge detectors usually have difficulty predicting edge maps that satisfy both correctness and crispness. With the recent success of the diffusion probabilistic model (DPM), we found it is especially suitable for accurate and crisp edge detection since the denoising process is directly applied to the original image size. Therefore, we propose the first diffusion model for the task of general edge detection, which we call DiffusionEdge. To avoid expensive computational resources while retaining the final performance, we apply DPM in the latent space and enable the classic cross-entropy loss which is uncertainty-aware in pixel level to directly optimize the parameters in latent space in a distillation manner. We also adopt a decoupled architecture to speed up the denoising process and propose a corresponding adaptive Fourier filter to adjust the latent features of specific frequencies. With all the technical designs, DiffusionEdge can be stably trained with limited resources, predicting crisp and accurate edge maps with much fewer augmentation strategies. Extensive experiments on four edge detection benchmarks demonstrate the superiority of DiffusionEdge both in correctness and crispness. On the NYUDv2 dataset, compared to the second best, we increase the ODS, OIS (without post-processing) and AC by 30.2%, 28.1% and 65.1%, respectively. Code: https://github.com/GuHuangAI/DiffusionEdge.
RayMVSNet++: Learning Ray-based 1D Implicit Fields for Accurate Multi-View Stereo
Jul 16, 2023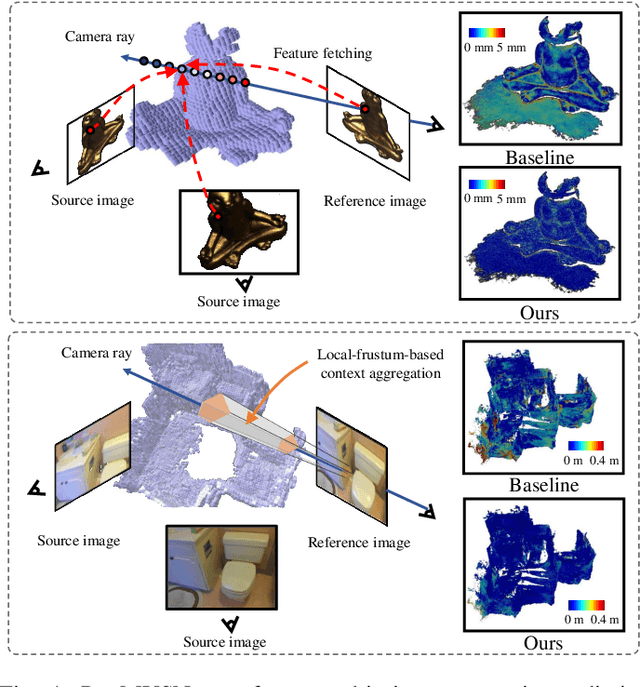
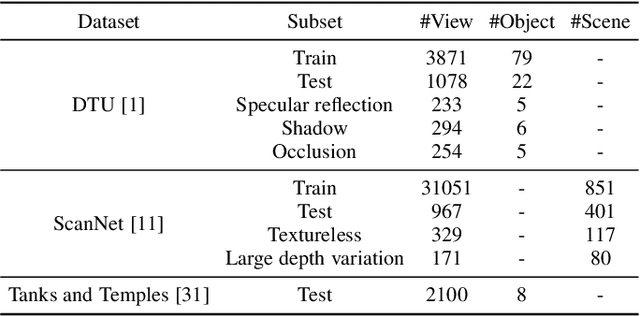
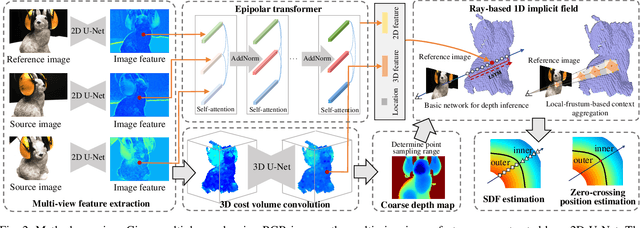
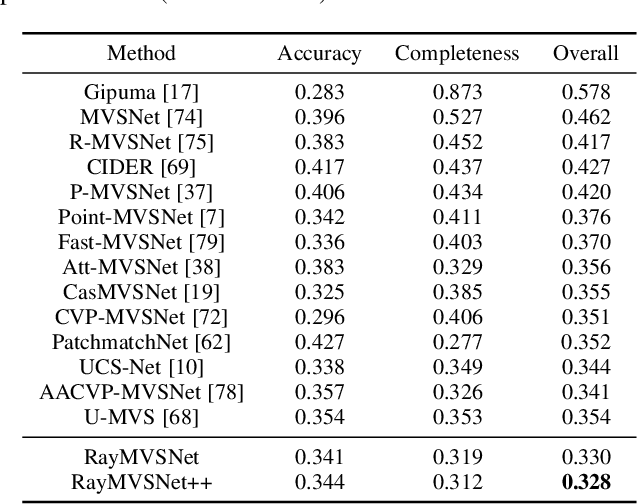
Learning-based multi-view stereo (MVS) has by far centered around 3D convolution on cost volumes. Due to the high computation and memory consumption of 3D CNN, the resolution of output depth is often considerably limited. Different from most existing works dedicated to adaptive refinement of cost volumes, we opt to directly optimize the depth value along each camera ray, mimicking the range finding of a laser scanner. This reduces the MVS problem to ray-based depth optimization which is much more light-weight than full cost volume optimization. In particular, we propose RayMVSNet which learns sequential prediction of a 1D implicit field along each camera ray with the zero-crossing point indicating scene depth. This sequential modeling, conducted based on transformer features, essentially learns the epipolar line search in traditional multi-view stereo. We devise a multi-task learning for better optimization convergence and depth accuracy. We found the monotonicity property of the SDFs along each ray greatly benefits the depth estimation. Our method ranks top on both the DTU and the Tanks & Temples datasets over all previous learning-based methods, achieving an overall reconstruction score of 0.33mm on DTU and an F-score of 59.48% on Tanks & Temples. It is able to produce high-quality depth estimation and point cloud reconstruction in challenging scenarios such as objects/scenes with non-textured surface, severe occlusion, and highly varying depth range. Further, we propose RayMVSNet++ to enhance contextual feature aggregation for each ray through designing an attentional gating unit to select semantically relevant neighboring rays within the local frustum around that ray. RayMVSNet++ achieves state-of-the-art performance on the ScanNet dataset. In particular, it attains an AbsRel of 0.058m and produces accurate results on the two subsets of textureless regions and large depth variation.
Delving into Crispness: Guided Label Refinement for Crisp Edge Detection
Jun 27, 2023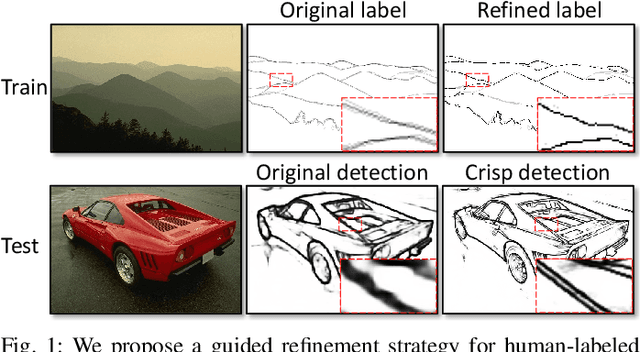
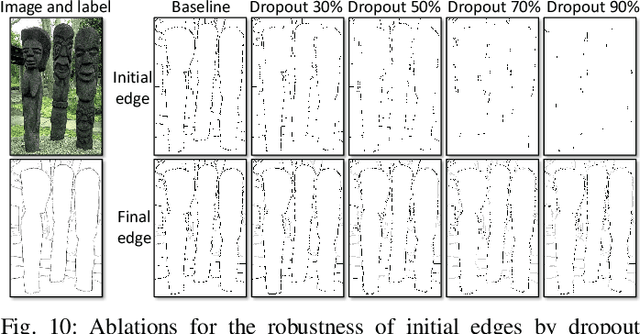


Learning-based edge detection usually suffers from predicting thick edges. Through extensive quantitative study with a new edge crispness measure, we find that noisy human-labeled edges are the main cause of thick predictions. Based on this observation, we advocate that more attention should be paid on label quality than on model design to achieve crisp edge detection. To this end, we propose an effective Canny-guided refinement of human-labeled edges whose result can be used to train crisp edge detectors. Essentially, it seeks for a subset of over-detected Canny edges that best align human labels. We show that several existing edge detectors can be turned into a crisp edge detector through training on our refined edge maps. Experiments demonstrate that deep models trained with refined edges achieve significant performance boost of crispness from 17.4% to 30.6%. With the PiDiNet backbone, our method improves ODS and OIS by 12.2% and 12.6% on the Multicue dataset, respectively, without relying on non-maximal suppression. We further conduct experiments and show the superiority of our crisp edge detection for optical flow estimation and image segmentation.
RARE: Robust Masked Graph Autoencoder
Apr 06, 2023



Masked graph autoencoder (MGAE) has emerged as a promising self-supervised graph pre-training (SGP) paradigm due to its simplicity and effectiveness. However, existing efforts perform the mask-then-reconstruct operation in the raw data space as is done in computer vision (CV) and natural language processing (NLP) areas, while neglecting the important non-Euclidean property of graph data. As a result, the highly unstable local connection structures largely increase the uncertainty in inferring masked data and decrease the reliability of the exploited self-supervision signals, leading to inferior representations for downstream evaluations. To address this issue, we propose a novel SGP method termed Robust mAsked gRaph autoEncoder (RARE) to improve the certainty in inferring masked data and the reliability of the self-supervision mechanism by further masking and reconstructing node samples in the high-order latent feature space. Through both theoretical and empirical analyses, we have discovered that performing a joint mask-then-reconstruct strategy in both latent feature and raw data spaces could yield improved stability and performance. To this end, we elaborately design a masked latent feature completion scheme, which predicts latent features of masked nodes under the guidance of high-order sample correlations that are hard to be observed from the raw data perspective. Specifically, we first adopt a latent feature predictor to predict the masked latent features from the visible ones. Next, we encode the raw data of masked samples with a momentum graph encoder and subsequently employ the resulting representations to improve predicted results through latent feature matching. Extensive experiments on seventeen datasets have demonstrated the effectiveness and robustness of RARE against state-of-the-art (SOTA) competitors across three downstream tasks.