 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe-FedLLM: Delving into the Safety of Federated Large Language Models
Jan 12, 2026Federated learning (FL) addresses data privacy and silo issues in large language models (LLMs). Most prior work focuses on improving the training efficiency of federated LLMs. However, security in open environments is overlooked, particularly defenses against malicious clients. To investigate the safety of LLMs during FL, we conduct preliminary experiments to analyze potential attack surfaces and defensible characteristics from the perspective of Low-Rank Adaptation (LoRA) weights. We find two key properties of FL: 1) LLMs are vulnerable to attacks from malicious clients in FL, and 2) LoRA weights exhibit distinct behavioral patterns that can be filtered through simple classifiers. Based on these properties, we propose Safe-FedLLM, a probe-based defense framework for federated LLMs, constructing defenses across three dimensions: Step-Level, Client-Level, and Shadow-Level. The core concept of Safe-FedLLM is to perform probe-based discrimination on the LoRA weights locally trained by each client during FL, treating them as high-dimensional behavioral features and using lightweight classification models to determine whether they possess malicious attributes. Extensive experiments demonstrate that Safe-FedLLM effectively enhances the defense capability of federated LLMs without compromising performance on benign data. Notably, our method effectively suppresses malicious data impact without significant impact on training speed, and remains effective even with many malicious clients. Our code is available at: https://github.com/dmqx/Safe-FedLLM.
Dual Boost-Driven Graph-Level Clustering Network
Apr 08, 2025



Graph-level clustering remains a pivotal yet formidable challenge in graph learning. Recently, the integration of deep learning with representation learning has demonstrated notable advancements, yielding performance enhancements to a certain degree. However, existing methods suffer from at least one of the following issues: 1. the original graph structure has noise, and 2. during feature propagation and pooling processes, noise is gradually aggregated into the graph-level embeddings through information propagation. Consequently, these two limitations mask clustering-friendly information, leading to suboptimal graph-level clustering performance. To this end, we propose a novel Dual Boost-Driven Graph-Level Clustering Network (DBGCN) to alternately promote graph-level clustering and filtering out interference information in a unified framework. Specifically, in the pooling step, we evaluate the contribution of features at the global and optimize them using a learnable transformation matrix to obtain high-quality graph-level representation, such that the model's reasoning capability can be improved. Moreover, to enable reliable graph-level clustering, we first identify and suppress information detrimental to clustering by evaluating similarities between graph-level representations, providing more accurate guidance for multi-view fusion. Extensive experiments demonstrated that DBGCN outperforms the state-of-the-art graph-level clustering methods on six benchmark datasets.
Dynamic Position Transformation and Boundary Refinement Network for Left Atrial Segmentation
Jul 07, 2024



Left atrial (LA) segmentation is a crucial technique for irregular heartbeat (i.e., atrial fibrillation) diagnosis. Most current methods for LA segmentation strictly assume that the input data is acquired using object-oriented center cropping, while this assumption may not always hold in practice due to the high cost of manual object annotation. Random cropping is a straightforward data pre-processing approach. However, it 1) introduces significant irregularities and incompleteness in the input data and 2) disrupts the coherence and continuity of object boundary regions. To tackle these issues, we propose a novel Dynamic Position transformation and Boundary refinement Network (DPBNet). The core idea is to dynamically adjust the relative position of irregular targets to construct their contextual relationships and prioritize difficult boundary pixels to enhance foreground-background distinction. Specifically, we design a shuffle-then-reorder attention module to adjust the position of disrupted objects in the latent space using dynamic generation ratios, such that the vital dependencies among these random cropping targets could be well captured and preserved. Moreover, to improve the accuracy of boundary localization, we introduce a dual fine-grained boundary loss with scenario-adaptive weights to handle the ambiguity of the dual boundary at a fine-grained level, promoting the clarity and continuity of the obtained results. Extensive experimental results on benchmark dataset have demonstrated that DPBNet consistently outperforms existing state-of-the-art methods.
TMac: Temporal Multi-Modal Graph Learning for Acoustic Event Classification
Sep 26, 2023Audiovisual data is everywhere in this digital age, which raises higher requirements for the deep learning models developed on them. To well handle the information of the multi-modal data is the key to a better audiovisual modal. We observe that these audiovisual data naturally have temporal attributes, such as the time information for each frame in the video. More concretely, such data is inherently multi-modal according to both audio and visual cues, which proceed in a strict chronological order. It indicates that temporal information is important in multi-modal acoustic event modeling for both intra- and inter-modal. However, existing methods deal with each modal feature independently and simply fuse them together, which neglects the mining of temporal relation and thus leads to sub-optimal performance. With this motivation, we propose a Temporal Multi-modal graph learning method for Acoustic event Classification, called TMac, by modeling such temporal information via graph learning techniques. In particular, we construct a temporal graph for each acoustic event, dividing its audio data and video data into multiple segments. Each segment can be considered as a node, and the temporal relationships between nodes can be considered as timestamps on their edges. In this case, we can smoothly capture the dynamic information in intra-modal and inter-modal. Several experiments are conducted to demonstrate TMac outperforms other SOTA models in performance. Our code is available at https://github.com/MGitHubL/TMac.
Message Intercommunication for Inductive Relation Reasoning
May 23, 2023Inductive relation reasoning for knowledge graphs, aiming to infer missing links between brand-new entities, has drawn increasing attention. The models developed based on Graph Inductive Learning, called GraIL-based models, have shown promising potential for this task. However, the uni-directional message-passing mechanism hinders such models from exploiting hidden mutual relations between entities in directed graphs. Besides, the enclosing subgraph extraction in most GraIL-based models restricts the model from extracting enough discriminative information for reasoning. Consequently, the expressive ability of these models is limited. To address the problems, we propose a novel GraIL-based inductive relation reasoning model, termed MINES, by introducing a Message Intercommunication mechanism on the Neighbor-Enhanced Subgraph. Concretely, the message intercommunication mechanism is designed to capture the omitted hidden mutual information. It introduces bi-directed information interactions between connected entities by inserting an undirected/bi-directed GCN layer between uni-directed RGCN layers. Moreover, inspired by the success of involving more neighbors in other graph-based tasks, we extend the neighborhood area beyond the enclosing subgraph to enhance the information collection for inductive relation reasoning. Extensive experiments on twelve inductive benchmark datasets demonstrate that our MINES outperforms existing state-of-the-art models, and show the effectiveness of our intercommunication mechanism and reasoning on the neighbor-enhanced subgraph.
RARE: Robust Masked Graph Autoencoder
Apr 06, 2023



Masked graph autoencoder (MGAE) has emerged as a promising self-supervised graph pre-training (SGP) paradigm due to its simplicity and effectiveness. However, existing efforts perform the mask-then-reconstruct operation in the raw data space as is done in computer vision (CV) and natural language processing (NLP) areas, while neglecting the important non-Euclidean property of graph data. As a result, the highly unstable local connection structures largely increase the uncertainty in inferring masked data and decrease the reliability of the exploited self-supervision signals, leading to inferior representations for downstream evaluations. To address this issue, we propose a novel SGP method termed Robust mAsked gRaph autoEncoder (RARE) to improve the certainty in inferring masked data and the reliability of the self-supervision mechanism by further masking and reconstructing node samples in the high-order latent feature space. Through both theoretical and empirical analyses, we have discovered that performing a joint mask-then-reconstruct strategy in both latent feature and raw data spaces could yield improved stability and performance. To this end, we elaborately design a masked latent feature completion scheme, which predicts latent features of masked nodes under the guidance of high-order sample correlations that are hard to be observed from the raw data perspective. Specifically, we first adopt a latent feature predictor to predict the masked latent features from the visible ones. Next, we encode the raw data of masked samples with a momentum graph encoder and subsequently employ the resulting representations to improve predicted results through latent feature matching. Extensive experiments on seventeen datasets have demonstrated the effectiveness and robustness of RARE against state-of-the-art (SOTA) competitors across three downstream tasks.
GANN: Graph Alignment Neural Network for Semi-Supervised Learning
Mar 14, 2023
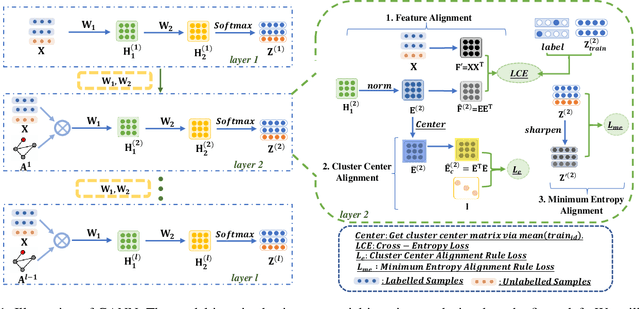
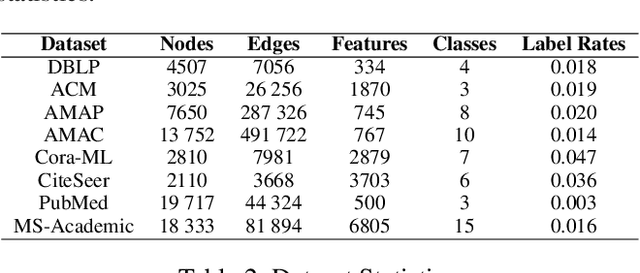
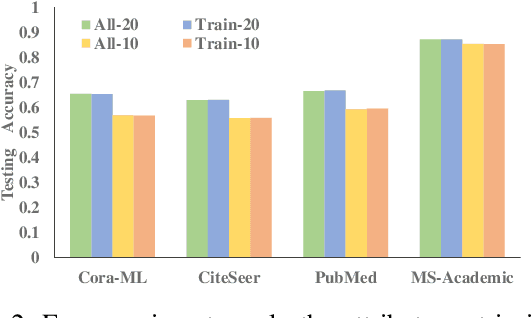
Graph neural networks (GNNs) have been widely investigated in the field of semi-supervised graph machine learning. Most methods fail to exploit adequate graph information when labeled data is limited, leading to the problem of oversmoothing. To overcome this issue, we propose the Graph Alignment Neural Network (GANN), a simple and effective graph neural architecture. A unique learning algorithm with three alignment rules is proposed to thoroughly explore hidden information for insufficient labels. Firstly, to better investigate attribute specifics, we suggest the feature alignment rule to align the inner product of both the attribute and embedding matrices. Secondly, to properly utilize the higher-order neighbor information, we propose the cluster center alignment rule, which involves aligning the inner product of the cluster center matrix with the unit matrix. Finally, to get reliable prediction results with few labels, we establish the minimum entropy alignment rule by lining up the prediction probability matrix with its sharpened result. Extensive studies on graph benchmark datasets demonstrate that GANN can achieve considerable benefits in semi-supervised node classification and outperform state-of-the-art competitors.
Self-Supervised Temporal Graph learning with Temporal and Structural Intensity Alignment
Feb 15, 2023



Temporal graph learning aims to generate high-quality representations for graph-based tasks along with dynamic information, which has recently drawn increasing attention. Unlike the static graph, a temporal graph is usually organized in the form of node interaction sequences over continuous time instead of an adjacency matrix. Most temporal graph learning methods model current interactions by combining historical information over time. However, such methods merely consider the first-order temporal information while ignoring the important high-order structural information, leading to sub-optimal performance. To solve this issue, by extracting both temporal and structural information to learn more informative node representations, we propose a self-supervised method termed S2T for temporal graph learning. Note that the first-order temporal information and the high-order structural information are combined in different ways by the initial node representations to calculate two conditional intensities, respectively. Then the alignment loss is introduced to optimize the node representations to be more informative by narrowing the gap between the two intensities. Concretely, besides modeling temporal information using historical neighbor sequences, we further consider the structural information from both local and global levels. At the local level, we generate structural intensity by aggregating features from the high-order neighbor sequences. At the global level, a global representation is generated based on all nodes to adjust the structural intensity according to the active statuses on different nodes. Extensive experiments demonstrate that the proposed method S2T achieves at most 10.13% performance improvement compared with the state-of-the-art competitors on several datasets.
Revisiting Initializing Then Refining: An Incomplete and Missing Graph Imputation Network
Feb 15, 2023



With the development of various applications, such as social networks and knowledge graphs, graph data has been ubiquitous in the real world. Unfortunately, graphs usually suffer from being absent due to privacy-protecting policies or copyright restrictions during data collection. The absence of graph data can be roughly categorized into attribute-incomplete and attribute-missing circumstances. Specifically, attribute-incomplete indicates that a part of the attribute vectors of all nodes are incomplete, while attribute-missing indicates that the whole attribute vectors of partial nodes are missing. Although many efforts have been devoted, none of them is custom-designed for a common situation where both types of graph data absence exist simultaneously. To fill this gap, we develop a novel network termed Revisiting Initializing Then Refining (RITR), where we complete both attribute-incomplete and attribute-missing samples under the guidance of a novel initializing-then-refining imputation criterion. Specifically, to complete attribute-incomplete samples, we first initialize the incomplete attributes using Gaussian noise before network learning, and then introduce a structure-attribute consistency constraint to refine incomplete values by approximating a structure-attribute correlation matrix to a high-order structural matrix. To complete attribute-missing samples, we first adopt structure embeddings of attribute-missing samples as the embedding initialization, and then refine these initial values by adaptively aggregating the reliable information of attribute-incomplete samples according to a dynamic affinity structure. To the best of our knowledge, this newly designed method is the first unsupervised framework dedicated to handling hybrid-absent graphs. Extensive experiments on four datasets have verified that our methods consistently outperform existing state-of-the-art competitors.
Cluster-guided Contrastive Graph Clustering Network
Jan 03, 2023


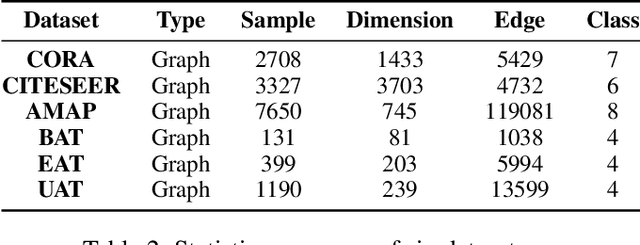
Benefiting from the intrinsic supervision information exploitation capability, contrastive learning has achieved promising performance in the field of deep graph clustering recently. However, we observe that two drawbacks of the positive and negative sample construction mechanisms limit the performance of existing algorithms from further improvement. 1) The quality of positive samples heavily depends on the carefully designed data augmentations, while inappropriate data augmentations would easily lead to the semantic drift and indiscriminative positive samples. 2) The constructed negative samples are not reliable for ignoring important clustering information. To solve these problems, we propose a Cluster-guided Contrastive deep Graph Clustering network (CCGC) by mining the intrinsic supervision information in the high-confidence clustering results. Specifically, instead of conducting complex node or edge perturbation, we construct two views of the graph by designing special Siamese encoders whose weights are not shared between the sibling sub-networks. Then, guided by the high-confidence clustering information, we carefully select and construct the positive samples from the same high-confidence cluster in two views. Moreover, to construct semantic meaningful negative sample pairs, we regard the centers of different high-confidence clusters as negative samples, thus improving the discriminative capability and reliability of the constructed sample pairs. Lastly, we design an objective function to pull close the samples from the same cluster while pushing away those from other clusters by maximizing and minimizing the cross-view cosine similarity between positive and negative samples. Extensive experimental results on six datasets demonstrate the effectiveness of CCGC compared with the existing state-of-the-art algorithms.