 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCG-DMER: Hybrid Contrastive-Generative Framework for Disentangled Multimodal ECG Representation Learning
Feb 24, 2026Accurate interpretation of electrocardiogram (ECG) signals is crucial for diagnosing cardiovascular diseases. Recent multimodal approaches that integrate ECGs with accompanying clinical reports show strong potential, but they still face two main concerns from a modality perspective: (1) intra-modality: existing models process ECGs in a lead-agnostic manner, overlooking spatial-temporal dependencies across leads, which restricts their effectiveness in modeling fine-grained diagnostic patterns; (2) inter-modality: existing methods directly align ECG signals with clinical reports, introducing modality-specific biases due to the free-text nature of the reports. In light of these two issues, we propose CG-DMER, a contrastive-generative framework for disentangled multimodal ECG representation learning, powered by two key designs: (1) Spatial-temporal masked modeling is designed to better capture fine-grained temporal dynamics and inter-lead spatial dependencies by applying masking across both spatial and temporal dimensions and reconstructing the missing information. (2) A representation disentanglement and alignment strategy is designed to mitigate unnecessary noise and modality-specific biases by introducing modality-specific and modality-shared encoders, ensuring a clearer separation between modality-invariant and modality-specific representations. Experiments on three public datasets demonstrate that CG-DMER achieves state-of-the-art performance across diverse downstream tasks.
Beyond Parameter Finetuning: Test-Time Representation Refinement for Node Classification
Jan 29, 2026Graph Neural Networks frequently exhibit significant performance degradation in the out-of-distribution test scenario. While test-time training (TTT) offers a promising solution, existing Parameter Finetuning (PaFT) paradigm suffer from catastrophic forgetting, hindering their real-world applicability. We propose TTReFT, a novel Test-Time Representation FineTuning framework that transitions the adaptation target from model parameters to latent representations. Specifically, TTReFT achieves this through three key innovations: (1) uncertainty-guided node selection for specific interventions, (2) low-rank representation interventions that preserve pre-trained knowledge, and (3) an intervention-aware masked autoencoder that dynamically adjust masking strategy to accommodate the node selection scheme. Theoretically, we establish guarantees for TTReFT in OOD settings. Empirically, extensive experiments across five benchmark datasets demonstrate that TTReFT achieves consistent and superior performance. Our work establishes representation finetuning as a new paradigm for graph TTT, offering both theoretical grounding and immediate practical utility for real-world deployment.
Generalized Deep Multi-view Clustering via Causal Learning with Partially Aligned Cross-view Correspondence
Sep 19, 2025Multi-view clustering (MVC) aims to explore the common clustering structure across multiple views. Many existing MVC methods heavily rely on the assumption of view consistency, where alignments for corresponding samples across different views are ordered in advance. However, real-world scenarios often present a challenge as only partial data is consistently aligned across different views, restricting the overall clustering performance. In this work, we consider the model performance decreasing phenomenon caused by data order shift (i.e., from fully to partially aligned) as a generalized multi-view clustering problem. To tackle this problem, we design a causal multi-view clustering network, termed CauMVC. We adopt a causal modeling approach to understand multi-view clustering procedure. To be specific, we formulate the partially aligned data as an intervention and multi-view clustering with partially aligned data as an post-intervention inference. However, obtaining invariant features directly can be challenging. Thus, we design a Variational Auto-Encoder for causal learning by incorporating an encoder from existing information to estimate the invariant features. Moreover, a decoder is designed to perform the post-intervention inference. Lastly, we design a contrastive regularizer to capture sample correlations. To the best of our knowledge, this paper is the first work to deal generalized multi-view clustering via causal learning. Empirical experiments on both fully and partially aligned data illustrate the strong generalization and effectiveness of CauMVC.
Automatically Identify and Rectify: Robust Deep Contrastive Multi-view Clustering in Noisy Scenarios
May 27, 2025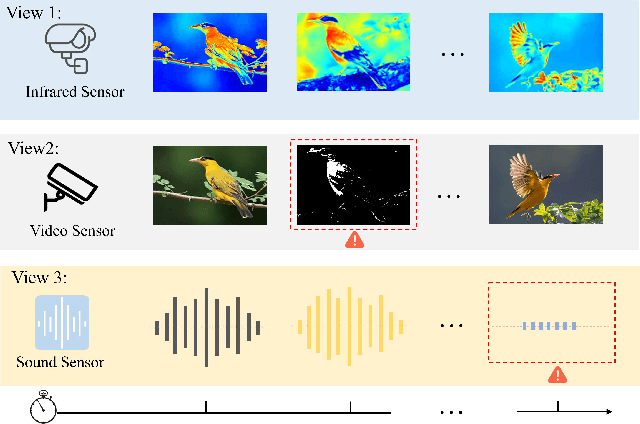
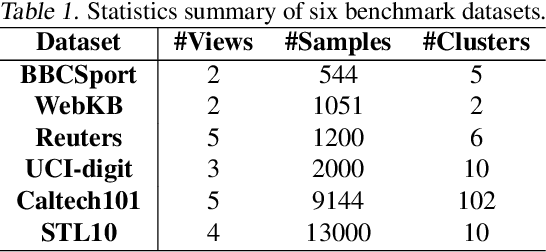
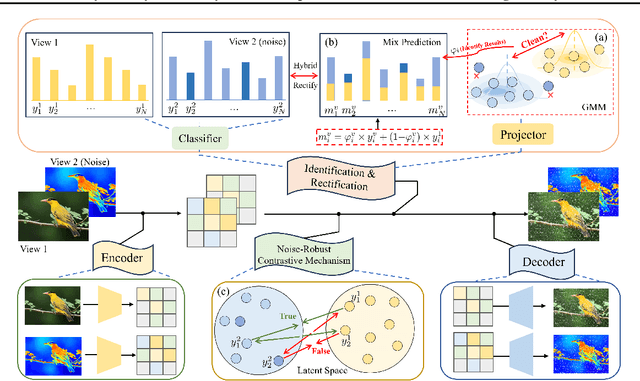

Leveraging the powerful representation learning capabilities, deep multi-view clustering methods have demonstrated reliable performance by effectively integrating multi-source information from diverse views in recent years. Most existing methods rely on the assumption of clean views. However, noise is pervasive in real-world scenarios, leading to a significant degradation in performance. To tackle this problem, we propose a novel multi-view clustering framework for the automatic identification and rectification of noisy data, termed AIRMVC. Specifically, we reformulate noisy identification as an anomaly identification problem using GMM. We then design a hybrid rectification strategy to mitigate the adverse effects of noisy data based on the identification results. Furthermore, we introduce a noise-robust contrastive mechanism to generate reliable representations. Additionally, we provide a theoretical proof demonstrating that these representations can discard noisy information, thereby improving the performance of downstream tasks. Extensive experiments on six benchmark datasets demonstrate that AIRMVC outperforms state-of-the-art algorithms in terms of robustness in noisy scenarios. The code of AIRMVC are available at https://github.com/xihongyang1999/AIRMVC on Github.
Imputation-free and Alignment-free: Incomplete Multi-view Clustering Driven by Consensus Semantic Learning
May 16, 2025In incomplete multi-view clustering (IMVC), missing data induce prototype shifts within views and semantic inconsistencies across views. A feasible solution is to explore cross-view consistency in paired complete observations, further imputing and aligning the similarity relationships inherently shared across views. Nevertheless, existing methods are constrained by two-tiered limitations: (1) Neither instance- nor cluster-level consistency learning construct a semantic space shared across views to learn consensus semantics. The former enforces cross-view instances alignment, and wrongly regards unpaired observations with semantic consistency as negative pairs; the latter focuses on cross-view cluster counterparts while coarsely handling fine-grained intra-cluster relationships within views. (2) Excessive reliance on consistency results in unreliable imputation and alignment without incorporating view-specific cluster information. Thus, we propose an IMVC framework, imputation- and alignment-free for consensus semantics learning (FreeCSL). To bridge semantic gaps across all observations, we learn consensus prototypes from available data to discover a shared space, where semantically similar observations are pulled closer for consensus semantics learning. To capture semantic relationships within specific views, we design a heuristic graph clustering based on modularity to recover cluster structure with intra-cluster compactness and inter-cluster separation for cluster semantics enhancement. Extensive experiments demonstrate, compared to state-of-the-art competitors, FreeCSL achieves more confident and robust assignments on IMVC task.
From Prompting to Alignment: A Generative Framework for Query Recommendation
Apr 14, 2025



In modern search systems, search engines often suggest relevant queries to users through various panels or components, helping refine their information needs. Traditionally, these recommendations heavily rely on historical search logs to build models, which suffer from cold-start or long-tail issues. Furthermore, tasks such as query suggestion, completion or clarification are studied separately by specific design, which lacks generalizability and hinders adaptation to novel applications. Despite recent attempts to explore the use of LLMs for query recommendation, these methods mainly rely on the inherent knowledge of LLMs or external sources like few-shot examples, retrieved documents, or knowledge bases, neglecting the importance of the calibration and alignment with user feedback, thus limiting their practical utility. To address these challenges, we first propose a general Generative Query Recommendation (GQR) framework that aligns LLM-based query generation with user preference. Specifically, we unify diverse query recommendation tasks by a universal prompt framework, leveraging the instruct-following capability of LLMs for effective generation. Secondly, we align LLMs with user feedback via presenting a CTR-alignment framework, which involves training a query-wise CTR predictor as a process reward model and employing list-wise preference alignment to maximize the click probability of the generated query list. Furthermore, recognizing the inconsistency between LLM knowledge and proactive search intents arising from the separation of user-initiated queries from models, we align LLMs with user initiative via retrieving co-occurrence queries as side information when historical logs are available.
DaRec: A Disentangled Alignment Framework for Large Language Model and Recommender System
Aug 15, 2024Benefiting from the strong reasoning capabilities, Large language models (LLMs) have demonstrated remarkable performance in recommender systems. Various efforts have been made to distill knowledge from LLMs to enhance collaborative models, employing techniques like contrastive learning for representation alignment. In this work, we prove that directly aligning the representations of LLMs and collaborative models is sub-optimal for enhancing downstream recommendation tasks performance, based on the information theorem. Consequently, the challenge of effectively aligning semantic representations between collaborative models and LLMs remains unresolved. Inspired by this viewpoint, we propose a novel plug-and-play alignment framework for LLMs and collaborative models. Specifically, we first disentangle the latent representations of both LLMs and collaborative models into specific and shared components via projection layers and representation regularization. Subsequently, we perform both global and local structure alignment on the shared representations to facilitate knowledge transfer. Additionally, we theoretically prove that the specific and shared representations contain more pertinent and less irrelevant information, which can enhance the effectiveness of downstream recommendation tasks. Extensive experimental results on benchmark datasets demonstrate that our method is superior to existing state-of-the-art algorithms.
Dual Test-time Training for Out-of-distribution Recommender System
Jul 22, 2024Deep learning has been widely applied in recommender systems, which has achieved revolutionary progress recently. However, most existing learning-based methods assume that the user and item distributions remain unchanged between the training phase and the test phase. However, the distribution of user and item features can naturally shift in real-world scenarios, potentially resulting in a substantial decrease in recommendation performance. This phenomenon can be formulated as an Out-Of-Distribution (OOD) recommendation problem. To address this challenge, we propose a novel Dual Test-Time-Training framework for OOD Recommendation, termed DT3OR. In DT3OR, we incorporate a model adaptation mechanism during the test-time phase to carefully update the recommendation model, allowing the model to specially adapt to the shifting user and item features. To be specific, we propose a self-distillation task and a contrastive task to assist the model learning both the user's invariant interest preferences and the variant user/item characteristics during the test-time phase, thus facilitating a smooth adaptation to the shifting features. Furthermore, we provide theoretical analysis to support the rationale behind our dual test-time training framework. To the best of our knowledge, this paper is the first work to address OOD recommendation via a test-time-training strategy. We conduct experiments on three datasets with various backbones. Comprehensive experimental results have demonstrated the effectiveness of DT3OR compared to other state-of-the-art baselines.
Test-Time Training on Graphs with Large Language Models
Apr 21, 2024



Graph Neural Networks have demonstrated great success in various fields of multimedia. However, the distribution shift between the training and test data challenges the effectiveness of GNNs. To mitigate this challenge, Test-Time Training (TTT) has been proposed as a promising approach. Traditional TTT methods require a demanding unsupervised training strategy to capture the information from test to benefit the main task. Inspired by the great annotation ability of Large Language Models (LLMs) on Text-Attributed Graphs (TAGs), we propose to enhance the test-time training on graphs with LLMs as annotators. In this paper, we design a novel Test-Time Training pipeline, LLMTTT, which conducts the test-time adaptation under the annotations by LLMs on a carefully-selected node set. Specifically, LLMTTT introduces a hybrid active node selection strategy that considers not only node diversity and representativeness, but also prediction signals from the pre-trained model. Given annotations from LLMs, a two-stage training strategy is designed to tailor the test-time model with the limited and noisy labels. A theoretical analysis ensures the validity of our method and extensive experiments demonstrate that the proposed LLMTTT can achieve a significant performance improvement compared to existing Out-of-Distribution (OOD) generalization methods.
Boosting the Power of Small Multimodal Reasoning Models to Match Larger Models with Self-Consistency Training
Nov 23, 2023Multimodal reasoning is a challenging task that requires models to reason across multiple modalities to answer questions. Existing approaches have made progress by incorporating language and visual modalities into a two-stage reasoning framework, separating rationale generation from answer inference. However, these approaches often fall short due to the inadequate quality of the generated rationales. In this work, we delve into the importance of rationales in model reasoning. We observe that when rationales are completely accurate, the model's accuracy significantly improves, highlighting the need for high-quality rationale generation. Motivated by this, we propose MC-CoT, a self-consistency training strategy that generates multiple rationales and answers, subsequently selecting the most accurate through a voting process. This approach not only enhances the quality of generated rationales but also leads to more accurate and robust answers. Through extensive experiments, we demonstrate that our approach significantly improves model performance across various benchmarks. Remarkably, we show that even smaller base models, when equipped with our proposed approach, can achieve results comparable to those of larger models, illustrating the potential of our approach in harnessing the power of rationales for improved multimodal reasoning. The code is available at https://github.com/chengtan9907/mc-cot.