 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Outside the Policy: In-Context Steered Policy Optimization
Oct 30, 2025Existing Reinforcement Learning from Verifiable Rewards (RLVR) methods, such as Group Relative Policy Optimization (GRPO), have achieved remarkable progress in improving the reasoning capabilities of Large Reasoning Models (LRMs). However, they exhibit limited exploration due to reliance on on-policy rollouts where confined to the current policy's distribution, resulting in narrow trajectory diversity. Recent approaches attempt to expand policy coverage by incorporating trajectories generated from stronger expert models, yet this reliance increases computational cost and such advaned models are often inaccessible. To address these issues, we propose In-Context Steered Policy Optimization (ICPO), a unified framework that leverages the inherent in-context learning capability of LRMs to provide expert guidance using existing datasets. ICPO introduces Mixed-Policy GRPO with Implicit Expert Forcing, which expands exploration beyond the current policy distribution without requiring advanced LRM trajectories. To further stabilize optimization, ICPO integrates Expert Region Reject Sampling to filter unreliable off-policy trajectories and Annealed Expert-Bonus Reward Shaping to balance early expert guidance with later autonomous improvement. Results demonstrate that ICPO consistently enhances reinforcement learning performance and training stability on mathematical reasoning benchmarks, revealing a scalable and effective RLVR paradigm for LRMs.
Do Not Step Into the Same River Twice: Learning to Reason from Trial and Error
Oct 30, 2025Reinforcement learning with verifiable rewards (RLVR) has significantly boosted the reasoning capability of large language models (LLMs) recently. However, existing RLVR approaches merely train LLMs based on their own generated responses and are constrained by the initial capability of LLMs, thus prone to exploration stagnation, in which LLMs fail to solve more training problems and cannot further learn from the training data. Some work tries to address this by leveraging off-policy solutions to training problems but requires external guidance from experts which suffers from limited availability. In this work, we propose LTE (Learning to reason from Trial and Error), an approach hinting LLMs with their previously self-generated incorrect answers and problem of overlong responses, which does not require any external expert guidance. Experiments validate the effectiveness of LTE, which outperforms the normal group relative policy optimization (GRPO) by 6.38 in Pass@1 and 9.00 in Pass@k on average across six mathematics benchmarks for Qwen3-4B-Base. Further analysis confirms that LTE successfully mitigates the problem of exploration stagnation and enhances both exploitation and exploration during training.
Beyond Spurious Signals: Debiasing Multimodal Large Language Models via Counterfactual Inference and Adaptive Expert Routing
Sep 18, 2025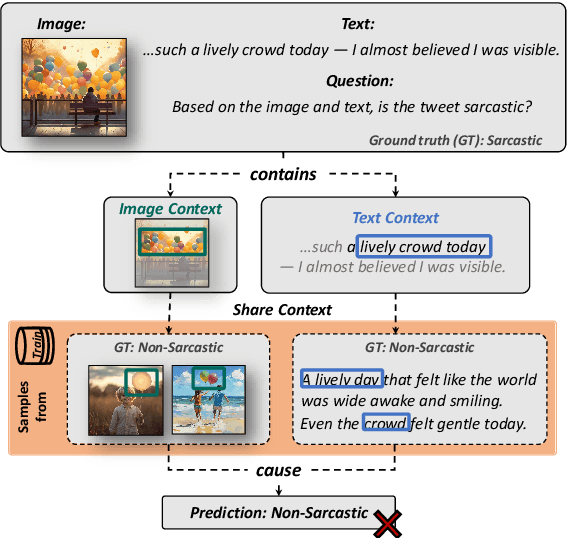

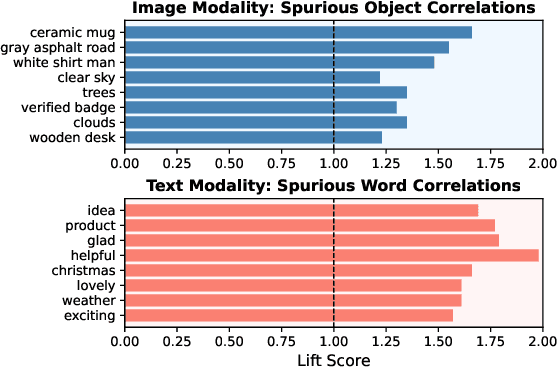
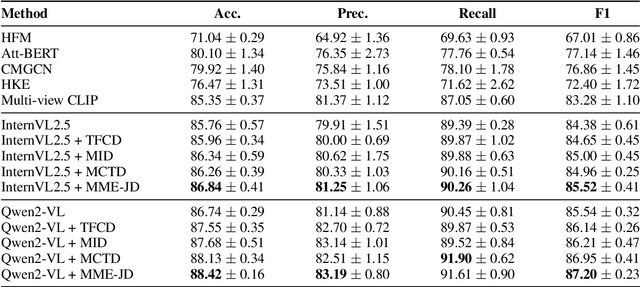
Multimodal Large Language Models (MLLMs) have shown substantial capabilities in integrating visual and textual information, yet frequently rely on spurious correlations, undermining their robustness and generalization in complex multimodal reasoning tasks. This paper addresses the critical challenge of superficial correlation bias in MLLMs through a novel causal mediation-based debiasing framework. Specially, we distinguishing core semantics from spurious textual and visual contexts via counterfactual examples to activate training-stage debiasing and employ a Mixture-of-Experts (MoE) architecture with dynamic routing to selectively engages modality-specific debiasing experts. Empirical evaluation on multimodal sarcasm detection and sentiment analysis tasks demonstrates that our framework significantly surpasses unimodal debiasing strategies and existing state-of-the-art models.
From Prompting to Alignment: A Generative Framework for Query Recommendation
Apr 14, 2025



In modern search systems, search engines often suggest relevant queries to users through various panels or components, helping refine their information needs. Traditionally, these recommendations heavily rely on historical search logs to build models, which suffer from cold-start or long-tail issues. Furthermore, tasks such as query suggestion, completion or clarification are studied separately by specific design, which lacks generalizability and hinders adaptation to novel applications. Despite recent attempts to explore the use of LLMs for query recommendation, these methods mainly rely on the inherent knowledge of LLMs or external sources like few-shot examples, retrieved documents, or knowledge bases, neglecting the importance of the calibration and alignment with user feedback, thus limiting their practical utility. To address these challenges, we first propose a general Generative Query Recommendation (GQR) framework that aligns LLM-based query generation with user preference. Specifically, we unify diverse query recommendation tasks by a universal prompt framework, leveraging the instruct-following capability of LLMs for effective generation. Secondly, we align LLMs with user feedback via presenting a CTR-alignment framework, which involves training a query-wise CTR predictor as a process reward model and employing list-wise preference alignment to maximize the click probability of the generated query list. Furthermore, recognizing the inconsistency between LLM knowledge and proactive search intents arising from the separation of user-initiated queries from models, we align LLMs with user initiative via retrieving co-occurrence queries as side information when historical logs are available.
A Survey of Uncertainty Estimation in LLMs: Theory Meets Practice
Oct 20, 2024
As large language models (LLMs) continue to evolve, understanding and quantifying the uncertainty in their predictions is critical for enhancing application credibility. However, the existing literature relevant to LLM uncertainty estimation often relies on heuristic approaches, lacking systematic classification of the methods. In this survey, we clarify the definitions of uncertainty and confidence, highlighting their distinctions and implications for model predictions. On this basis, we integrate theoretical perspectives, including Bayesian inference, information theory, and ensemble strategies, to categorize various classes of uncertainty estimation methods derived from heuristic approaches. Additionally, we address challenges that arise when applying these methods to LLMs. We also explore techniques for incorporating uncertainty into diverse applications, including out-of-distribution detection, data annotation, and question clarification. Our review provides insights into uncertainty estimation from both definitional and theoretical angles, contributing to a comprehensive understanding of this critical aspect in LLMs. We aim to inspire the development of more reliable and effective uncertainty estimation approaches for LLMs in real-world scenarios.
Unc-TTP: A Method for Classifying LLM Uncertainty to Improve In-Context Example Selection
Aug 20, 2024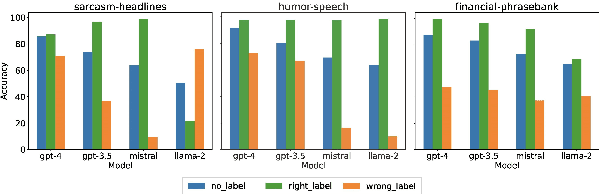

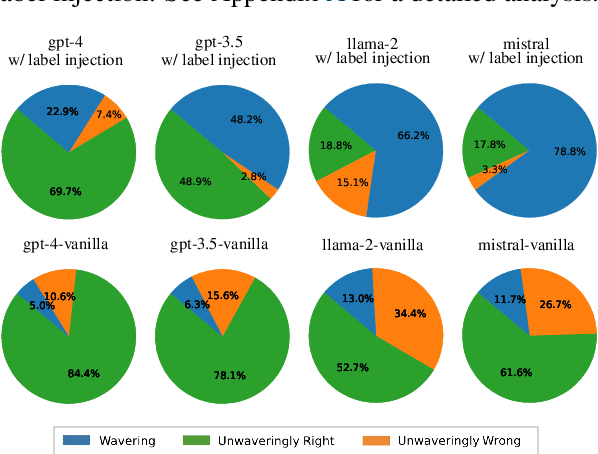
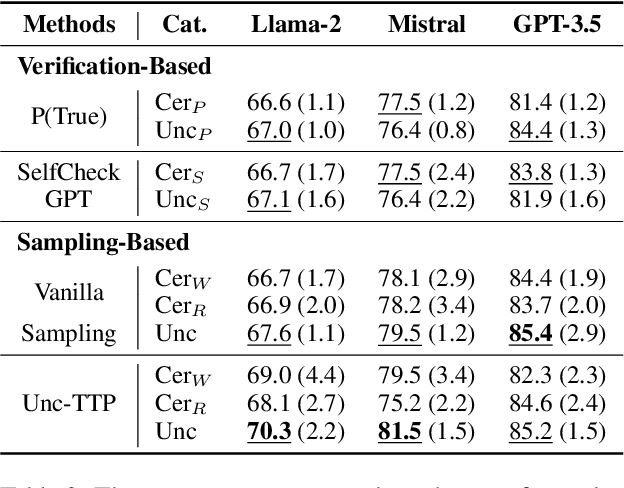
Nowadays, Large Language Models (LLMs) have demonstrated exceptional performance across various downstream tasks. However, it is challenging for users to discern whether the responses are generated with certainty or are fabricated to meet user expectations. Estimating the uncertainty of LLMs is particularly challenging due to their vast scale and the lack of white-box access. In this work, we propose a novel Uncertainty Tripartite Testing Paradigm (Unc-TTP) to classify LLM uncertainty, via evaluating the consistency of LLM outputs when incorporating label interference into the sampling-based approach. Based on Unc-TTP outputs, we aggregate instances into certain and uncertain categories. Further, we conduct a detailed analysis of the uncertainty properties of LLMs and show Unc-TTP's superiority over the existing sampling-based methods. In addition, we leverage the obtained uncertainty information to guide in-context example selection, demonstrating that Unc-TTP obviously outperforms retrieval-based and sampling-based approaches in selecting more informative examples. Our work paves a new way to classify the uncertainty of both open- and closed-source LLMs, and introduces a practical approach to exploit this uncertainty to improve LLMs performance.
Assessing the Performance of Chinese Open Source Large Language Models in Information Extraction Tasks
Jun 04, 2024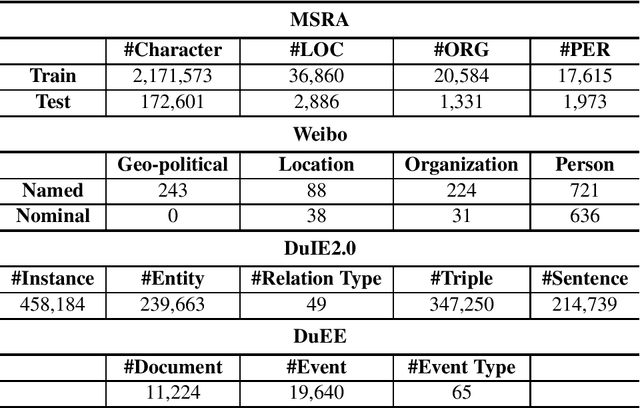



Information Extraction (IE) plays a crucial role in Natural Language Processing (NLP) by extracting structured information from unstructured text, thereby facilitating seamless integration with various real-world applications that rely on structured data. Despite its significance, recent experiments focusing on English IE tasks have shed light on the challenges faced by Large Language Models (LLMs) in achieving optimal performance, particularly in sub-tasks like Named Entity Recognition (NER). In this paper, we delve into a comprehensive investigation of the performance of mainstream Chinese open-source LLMs in tackling IE tasks, specifically under zero-shot conditions where the models are not fine-tuned for specific tasks. Additionally, we present the outcomes of several few-shot experiments to further gauge the capability of these models. Moreover, our study includes a comparative analysis between these open-source LLMs and ChatGPT, a widely recognized language model, on IE performance. Through meticulous experimentation and analysis, we aim to provide insights into the strengths, limitations, and potential enhancements of existing Chinese open-source LLMs in the domain of Information Extraction within the context of NLP.
FPT: Feature Prompt Tuning for Few-shot Readability Assessment
Apr 10, 2024



Prompt-based methods have achieved promising results in most few-shot text classification tasks. However, for readability assessment tasks, traditional prompt methods lackcrucial linguistic knowledge, which has already been proven to be essential. Moreover, previous studies on utilizing linguistic features have shown non-robust performance in few-shot settings and may even impair model performance.To address these issues, we propose a novel prompt-based tuning framework that incorporates rich linguistic knowledge, called Feature Prompt Tuning (FPT). Specifically, we extract linguistic features from the text and embed them into trainable soft prompts. Further, we devise a new loss function to calibrate the similarity ranking order between categories. Experimental results demonstrate that our proposed method FTP not only exhibits a significant performance improvement over the prior best prompt-based tuning approaches, but also surpasses the previous leading methods that incorporate linguistic features. Also, our proposed model significantly outperforms the large language model gpt-3.5-turbo-16k in most cases. Our proposed method establishes a new architecture for prompt tuning that sheds light on how linguistic features can be easily adapted to linguistic-related tasks.
Mixture-of-Prompt-Experts for Multi-modal Semantic Understanding
Mar 24, 2024Deep multimodal semantic understanding that goes beyond the mere superficial content relation mining has received increasing attention in the realm of artificial intelligence. The challenges of collecting and annotating high-quality multi-modal data have underscored the significance of few-shot learning. In this paper, we focus on two critical tasks under this context: few-shot multi-modal sarcasm detection (MSD) and multi-modal sentiment analysis (MSA). To address them, we propose Mixture-of-Prompt-Experts with Block-Aware Prompt Fusion (MoPE-BAF), a novel multi-modal soft prompt framework based on the unified vision-language model (VLM). Specifically, we design three experts of soft prompts: a text prompt and an image prompt that extract modality-specific features to enrich the single-modal representation, and a unified prompt to assist multi-modal interaction. Additionally, we reorganize Transformer layers into several blocks and introduce cross-modal prompt attention between adjacent blocks, which smoothens the transition from single-modal representation to multi-modal fusion. On both MSD and MSA datasets in few-shot setting, our proposed model not only surpasses the 8.2B model InstructBLIP with merely 2% parameters (150M), but also significantly outperforms other widely-used prompt methods on VLMs or task-specific methods.
Human Emotion Knowledge Representation Emerges in Large Language Model and Supports Discrete Emotion Inference
Feb 21, 2023

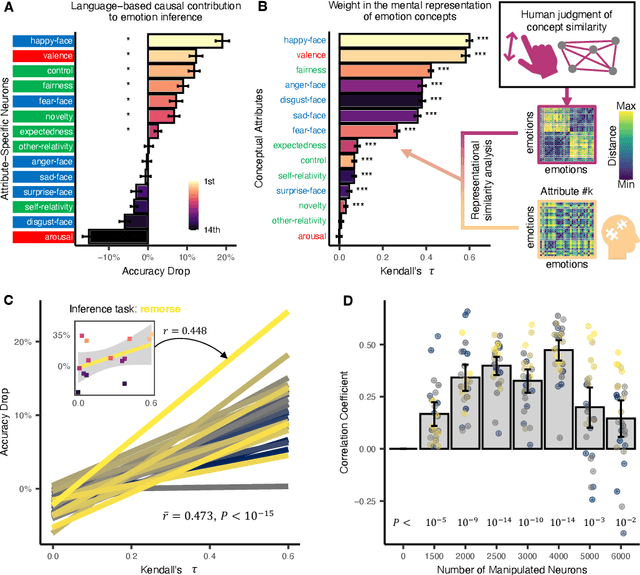
How humans infer discrete emotions is a fundamental research question in the field of psychology. While conceptual knowledge about emotions (emotion knowledge) has been suggested to be essential for emotion inference, evidence to date is mostly indirect and inconclusive. As the large language models (LLMs) have been shown to support effective representations of various human conceptual knowledge, the present study further employed artificial neurons in LLMs to investigate the mechanism of human emotion inference. With artificial neurons activated by prompts, the LLM (RoBERTa) demonstrated a similar conceptual structure of 27 discrete emotions as that of human behaviors. Furthermore, the LLM-based conceptual structure revealed a human-like reliance on 14 underlying conceptual attributes of emotions for emotion inference. Most importantly, by manipulating attribute-specific neurons, we found that the corresponding LLM's emotion inference performance deteriorated, and the performance deterioration was correlated to the effectiveness of representations of the conceptual attributes on the human side. Our findings provide direct evidence for the emergence of emotion knowledge representation in large language models and suggest its casual support for discrete emotion inference.