 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Spurious Signals: Debiasing Multimodal Large Language Models via Counterfactual Inference and Adaptive Expert Routing
Sep 18, 2025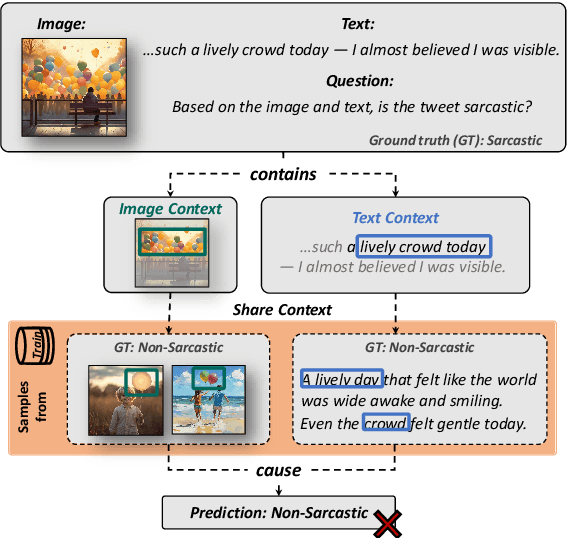

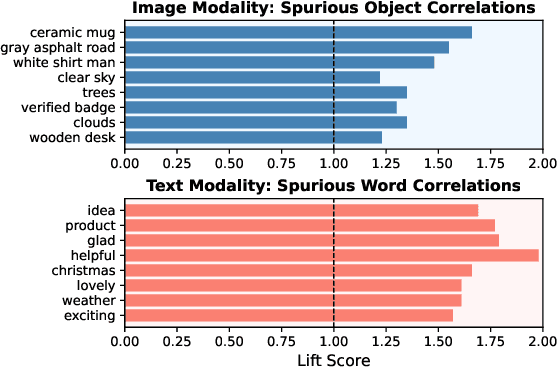
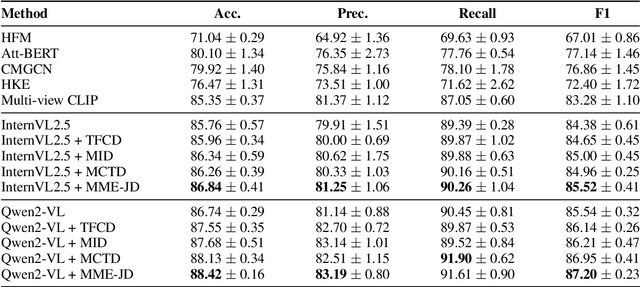
Multimodal Large Language Models (MLLMs) have shown substantial capabilities in integrating visual and textual information, yet frequently rely on spurious correlations, undermining their robustness and generalization in complex multimodal reasoning tasks. This paper addresses the critical challenge of superficial correlation bias in MLLMs through a novel causal mediation-based debiasing framework. Specially, we distinguishing core semantics from spurious textual and visual contexts via counterfactual examples to activate training-stage debiasing and employ a Mixture-of-Experts (MoE) architecture with dynamic routing to selectively engages modality-specific debiasing experts. Empirical evaluation on multimodal sarcasm detection and sentiment analysis tasks demonstrates that our framework significantly surpasses unimodal debiasing strategies and existing state-of-the-art models.
Unc-TTP: A Method for Classifying LLM Uncertainty to Improve In-Context Example Selection
Aug 20, 2024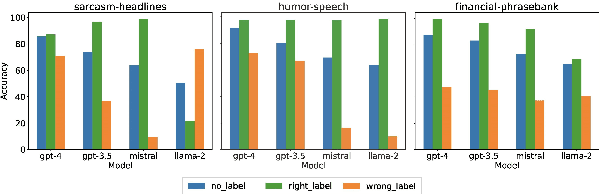

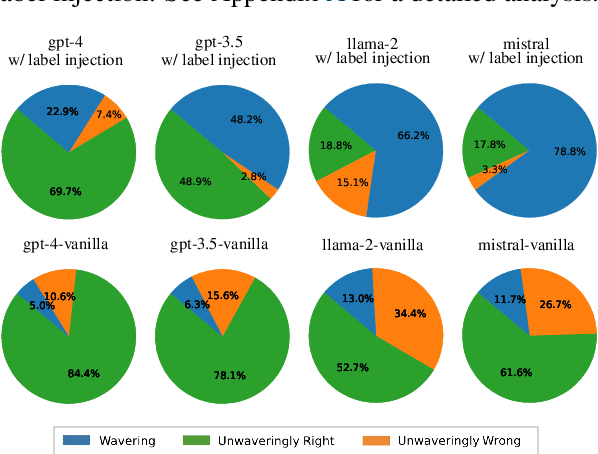
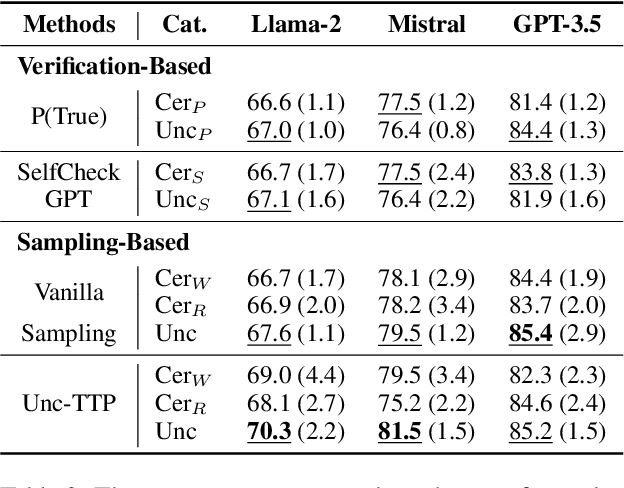
Nowadays, Large Language Models (LLMs) have demonstrated exceptional performance across various downstream tasks. However, it is challenging for users to discern whether the responses are generated with certainty or are fabricated to meet user expectations. Estimating the uncertainty of LLMs is particularly challenging due to their vast scale and the lack of white-box access. In this work, we propose a novel Uncertainty Tripartite Testing Paradigm (Unc-TTP) to classify LLM uncertainty, via evaluating the consistency of LLM outputs when incorporating label interference into the sampling-based approach. Based on Unc-TTP outputs, we aggregate instances into certain and uncertain categories. Further, we conduct a detailed analysis of the uncertainty properties of LLMs and show Unc-TTP's superiority over the existing sampling-based methods. In addition, we leverage the obtained uncertainty information to guide in-context example selection, demonstrating that Unc-TTP obviously outperforms retrieval-based and sampling-based approaches in selecting more informative examples. Our work paves a new way to classify the uncertainty of both open- and closed-source LLMs, and introduces a practical approach to exploit this uncertainty to improve LLMs performance.
Mixture-of-Prompt-Experts for Multi-modal Semantic Understanding
Mar 24, 2024Deep multimodal semantic understanding that goes beyond the mere superficial content relation mining has received increasing attention in the realm of artificial intelligence. The challenges of collecting and annotating high-quality multi-modal data have underscored the significance of few-shot learning. In this paper, we focus on two critical tasks under this context: few-shot multi-modal sarcasm detection (MSD) and multi-modal sentiment analysis (MSA). To address them, we propose Mixture-of-Prompt-Experts with Block-Aware Prompt Fusion (MoPE-BAF), a novel multi-modal soft prompt framework based on the unified vision-language model (VLM). Specifically, we design three experts of soft prompts: a text prompt and an image prompt that extract modality-specific features to enrich the single-modal representation, and a unified prompt to assist multi-modal interaction. Additionally, we reorganize Transformer layers into several blocks and introduce cross-modal prompt attention between adjacent blocks, which smoothens the transition from single-modal representation to multi-modal fusion. On both MSD and MSA datasets in few-shot setting, our proposed model not only surpasses the 8.2B model InstructBLIP with merely 2% parameters (150M), but also significantly outperforms other widely-used prompt methods on VLMs or task-specific methods.
Enhancing Pre-trained Models with Text Structure Knowledge for Question Generation
Sep 09, 2022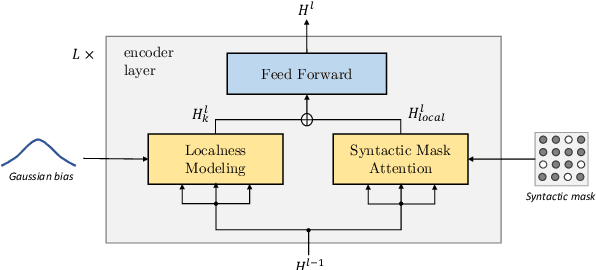
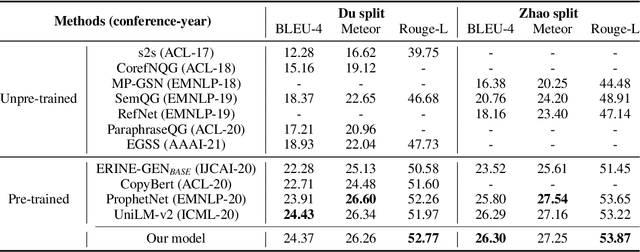
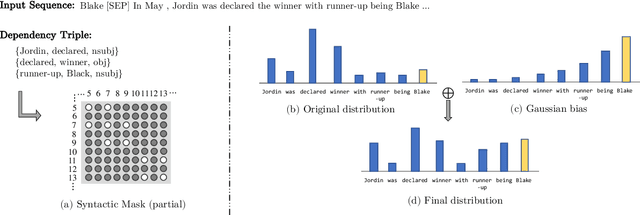

Today the pre-trained language models achieve great success for question generation (QG) task and significantly outperform traditional sequence-to-sequence approaches. However, the pre-trained models treat the input passage as a flat sequence and are thus not aware of the text structure of input passage. For QG task, we model text structure as answer position and syntactic dependency, and propose answer localness modeling and syntactic mask attention to address these limitations. Specially, we present localness modeling with a Gaussian bias to enable the model to focus on answer-surrounded context, and propose a mask attention mechanism to make the syntactic structure of input passage accessible in question generation process. Experiments on SQuAD dataset show that our proposed two modules improve performance over the strong pre-trained model ProphetNet, and combing them together achieves very competitive results with the state-of-the-art pre-trained model.