 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNYK-MS: A Well-annotated Multi-modal Metaphor and Sarcasm Understanding Benchmark on Cartoon-Caption Dataset
Sep 02, 2024



Metaphor and sarcasm are common figurative expressions in people's communication, especially on the Internet or the memes popular among teenagers. We create a new benchmark named NYK-MS (NewYorKer for Metaphor and Sarcasm), which contains 1,583 samples for metaphor understanding tasks and 1,578 samples for sarcasm understanding tasks. These tasks include whether it contains metaphor/sarcasm, which word or object contains metaphor/sarcasm, what does it satirize and why does it contains metaphor/sarcasm, all of the 7 tasks are well-annotated by at least 3 annotators. We annotate the dataset for several rounds to improve the consistency and quality, and use GUI and GPT-4V to raise our efficiency. Based on the benchmark, we conduct plenty of experiments. In the zero-shot experiments, we show that Large Language Models (LLM) and Large Multi-modal Models (LMM) can't do classification task well, and as the scale increases, the performance on other 5 tasks improves. In the experiments on traditional pre-train models, we show the enhancement with augment and alignment methods, which prove our benchmark is consistent with previous dataset and requires the model to understand both of the two modalities.
Unc-TTP: A Method for Classifying LLM Uncertainty to Improve In-Context Example Selection
Aug 20, 2024

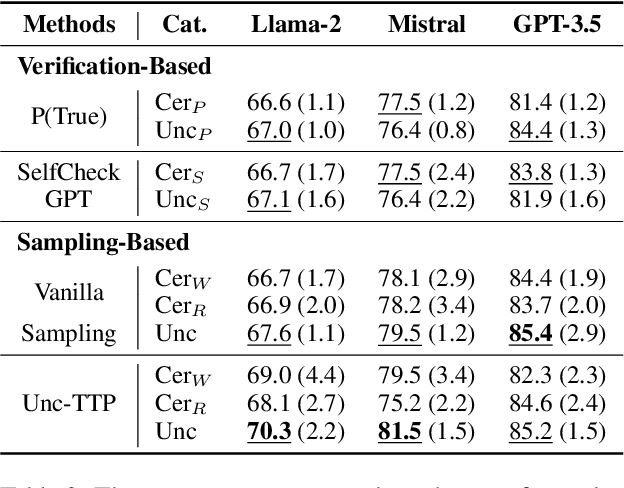
Nowadays, Large Language Models (LLMs) have demonstrated exceptional performance across various downstream tasks. However, it is challenging for users to discern whether the responses are generated with certainty or are fabricated to meet user expectations. Estimating the uncertainty of LLMs is particularly challenging due to their vast scale and the lack of white-box access. In this work, we propose a novel Uncertainty Tripartite Testing Paradigm (Unc-TTP) to classify LLM uncertainty, via evaluating the consistency of LLM outputs when incorporating label interference into the sampling-based approach. Based on Unc-TTP outputs, we aggregate instances into certain and uncertain categories. Further, we conduct a detailed analysis of the uncertainty properties of LLMs and show Unc-TTP's superiority over the existing sampling-based methods. In addition, we leverage the obtained uncertainty information to guide in-context example selection, demonstrating that Unc-TTP obviously outperforms retrieval-based and sampling-based approaches in selecting more informative examples. Our work paves a new way to classify the uncertainty of both open- and closed-source LLMs, and introduces a practical approach to exploit this uncertainty to improve LLMs performance.
On the Learning Dynamics of Two-layer Nonlinear Convolutional Neural Networks
May 24, 2019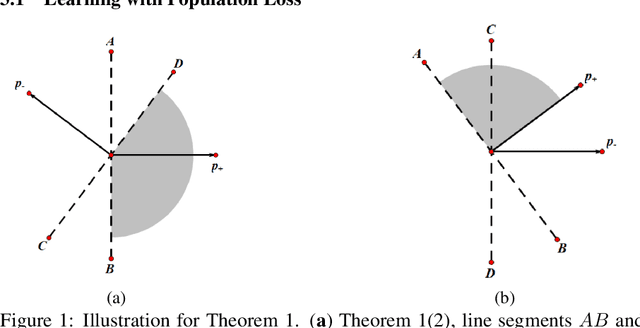
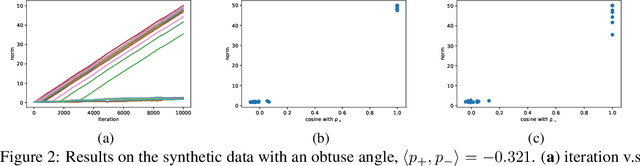
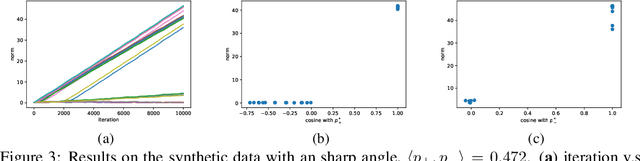

Convolutional neural networks (CNNs) have achieved remarkable performance in various fields, particularly in the domain of computer vision. However, why this architecture works well remains to be a mystery. In this work we move a small step toward understanding the success of CNNs by investigating the learning dynamics of a two-layer nonlinear convolutional neural network over some specific data distributions. Rather than the typical Gaussian assumption for input data distribution, we consider a more realistic setting that each data point (e.g. image) contains a specific pattern determining its class label. Within this setting, we both theoretically and empirically show that some convolutional filters will learn the key patterns in data and the norm of these filters will dominate during the training process with stochastic gradient descent. And with any high probability, when the number of iterations is sufficiently large, the CNN model could obtain 100% accuracy over the considered data distributions. Our experiments demonstrate that for practical image classification tasks our findings still hold to some extent.