 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnc-TTP: A Method for Classifying LLM Uncertainty to Improve In-Context Example Selection
Paper and Code
Aug 20, 2024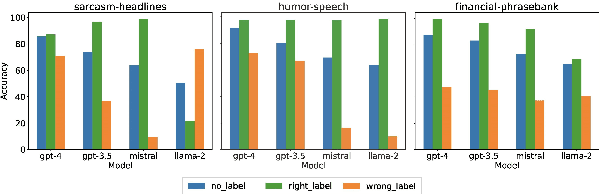

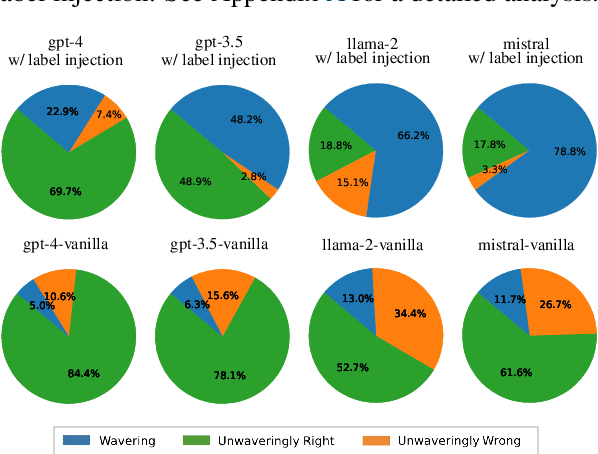
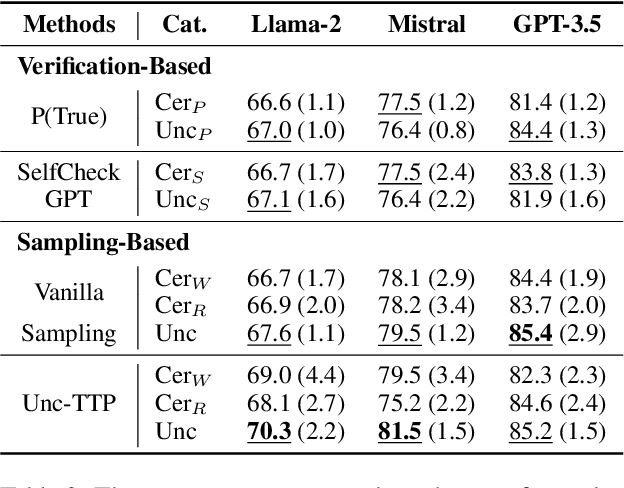
Nowadays, Large Language Models (LLMs) have demonstrated exceptional performance across various downstream tasks. However, it is challenging for users to discern whether the responses are generated with certainty or are fabricated to meet user expectations. Estimating the uncertainty of LLMs is particularly challenging due to their vast scale and the lack of white-box access. In this work, we propose a novel Uncertainty Tripartite Testing Paradigm (Unc-TTP) to classify LLM uncertainty, via evaluating the consistency of LLM outputs when incorporating label interference into the sampling-based approach. Based on Unc-TTP outputs, we aggregate instances into certain and uncertain categories. Further, we conduct a detailed analysis of the uncertainty properties of LLMs and show Unc-TTP's superiority over the existing sampling-based methods. In addition, we leverage the obtained uncertainty information to guide in-context example selection, demonstrating that Unc-TTP obviously outperforms retrieval-based and sampling-based approaches in selecting more informative examples. Our work paves a new way to classify the uncertainty of both open- and closed-source LLMs, and introduces a practical approach to exploit this uncertainty to improve LLMs performance.