 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMcBE: A Multi-task Chinese Bias Evaluation Benchmark for Large Language Models
Jul 02, 2025As large language models (LLMs) are increasingly applied to various NLP tasks, their inherent biases are gradually disclosed. Therefore, measuring biases in LLMs is crucial to mitigate its ethical risks. However, most existing bias evaluation datasets focus on English and North American culture, and their bias categories are not fully applicable to other cultures. The datasets grounded in the Chinese language and culture are scarce. More importantly, these datasets usually only support single evaluation tasks and cannot evaluate the bias from multiple aspects in LLMs. To address these issues, we present a Multi-task Chinese Bias Evaluation Benchmark (McBE) that includes 4,077 bias evaluation instances, covering 12 single bias categories, 82 subcategories and introducing 5 evaluation tasks, providing extensive category coverage, content diversity, and measuring comprehensiveness. Additionally, we evaluate several popular LLMs from different series and with parameter sizes. In general, all these LLMs demonstrated varying degrees of bias. We conduct an in-depth analysis of results, offering novel insights into bias in LLMs.
NYK-MS: A Well-annotated Multi-modal Metaphor and Sarcasm Understanding Benchmark on Cartoon-Caption Dataset
Sep 02, 2024



Metaphor and sarcasm are common figurative expressions in people's communication, especially on the Internet or the memes popular among teenagers. We create a new benchmark named NYK-MS (NewYorKer for Metaphor and Sarcasm), which contains 1,583 samples for metaphor understanding tasks and 1,578 samples for sarcasm understanding tasks. These tasks include whether it contains metaphor/sarcasm, which word or object contains metaphor/sarcasm, what does it satirize and why does it contains metaphor/sarcasm, all of the 7 tasks are well-annotated by at least 3 annotators. We annotate the dataset for several rounds to improve the consistency and quality, and use GUI and GPT-4V to raise our efficiency. Based on the benchmark, we conduct plenty of experiments. In the zero-shot experiments, we show that Large Language Models (LLM) and Large Multi-modal Models (LMM) can't do classification task well, and as the scale increases, the performance on other 5 tasks improves. In the experiments on traditional pre-train models, we show the enhancement with augment and alignment methods, which prove our benchmark is consistent with previous dataset and requires the model to understand both of the two modalities.
Multi-modal Semantic Understanding with Contrastive Cross-modal Feature Alignment
Mar 11, 2024Multi-modal semantic understanding requires integrating information from different modalities to extract users' real intention behind words. Most previous work applies a dual-encoder structure to separately encode image and text, but fails to learn cross-modal feature alignment, making it hard to achieve cross-modal deep information interaction. This paper proposes a novel CLIP-guided contrastive-learning-based architecture to perform multi-modal feature alignment, which projects the features derived from different modalities into a unified deep space. On multi-modal sarcasm detection (MMSD) and multi-modal sentiment analysis (MMSA) tasks, the experimental results show that our proposed model significantly outperforms several baselines, and our feature alignment strategy brings obvious performance gain over models with different aggregating methods and models even enriched with knowledge. More importantly, our model is simple to implement without using task-specific external knowledge, and thus can easily migrate to other multi-modal tasks. Our source codes are available at https://github.com/ChangKe123/CLFA.
Bidding Machine: Learning to Bid for Directly Optimizing Profits in Display Advertising
Mar 11, 2018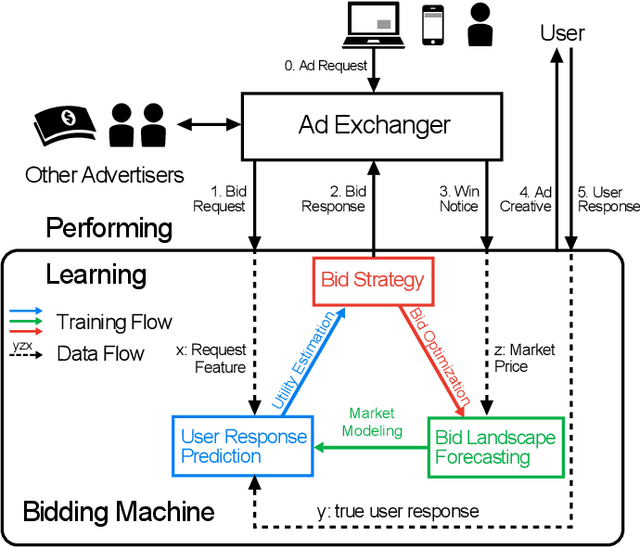
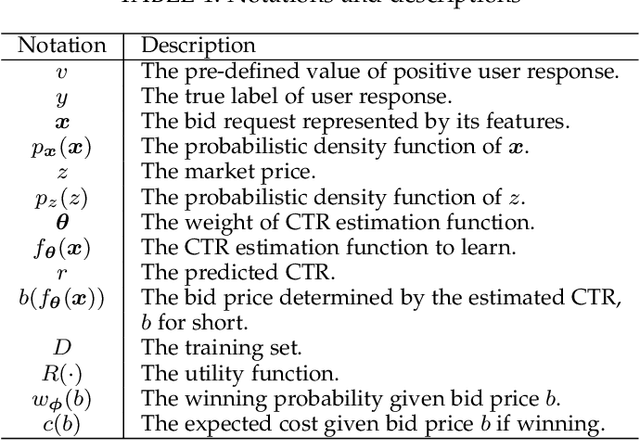
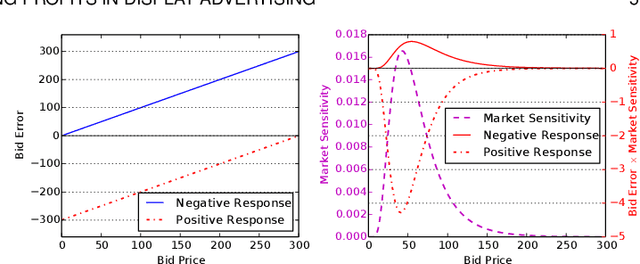

Real-time bidding (RTB) based display advertising has become one of the key technological advances in computational advertising. RTB enables advertisers to buy individual ad impressions via an auction in real-time and facilitates the evaluation and the bidding of individual impressions across multiple advertisers. In RTB, the advertisers face three main challenges when optimizing their bidding strategies, namely (i) estimating the utility (e.g., conversions, clicks) of the ad impression, (ii) forecasting the market value (thus the cost) of the given ad impression, and (iii) deciding the optimal bid for the given auction based on the first two. Previous solutions assume the first two are solved before addressing the bid optimization problem. However, these challenges are strongly correlated and dealing with any individual problem independently may not be globally optimal. In this paper, we propose Bidding Machine, a comprehensive learning to bid framework, which consists of three optimizers dealing with each challenge above, and as a whole, jointly optimizes these three parts. We show that such a joint optimization would largely increase the campaign effectiveness and the profit. From the learning perspective, we show that the bidding machine can be updated smoothly with both offline periodical batch or online sequential training schemes. Our extensive offline empirical study and online A/B testing verify the high effectiveness of the proposed bidding machine.
* 18 pages, 10 figures, Final version published in IEEE Transactions on Knowledge and Data Engineering (TKDE), URL: http://ieeexplore.ieee.org/document/8115218/