 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Wrote This Line? Evaluating the Detection of LLM-Generated Classical Chinese Poetry
Apr 11, 2026The rapid development of large language models (LLMs) has extended text generation tasks into the literary domain. However, AI-generated literary creations has raised increasingly prominent issues of creative authenticity and ethics in literary world, making the detection of LLM-generated literary texts essential and urgent. While previous works have made significant progress in detecting AI-generated text, it has yet to address classical Chinese poetry. Due to the unique linguistic features of classical Chinese poetry, such as strict metrical regularity, a shared system of poetic imagery, and flexible syntax, distinguishing whether a poem is authored by AI presents a substantial challenge. To address these issues, we introduce ChangAn, a benchmark for detecting LLM-generated classical Chinese poetry that containing total 30,664 poems, 10,276 are human-written poems and 20,388 poems are generated by four popular LLMs. Based on ChangAn, we conducted a systematic evaluation of 12 AI detectors, investigating their performance variations across different text granularities and generation strategies. Our findings highlight the limitations of current Chinese text detectors, which fail to serve as reliable tools for detecting LLM-generated classical Chinese poetry. These results validate the effectiveness and necessity of our proposed ChangAn benchmark. Our dataset and code are available at https://github.com/VelikayaScarlet/ChangAn.
McBE: A Multi-task Chinese Bias Evaluation Benchmark for Large Language Models
Jul 02, 2025As large language models (LLMs) are increasingly applied to various NLP tasks, their inherent biases are gradually disclosed. Therefore, measuring biases in LLMs is crucial to mitigate its ethical risks. However, most existing bias evaluation datasets focus on English and North American culture, and their bias categories are not fully applicable to other cultures. The datasets grounded in the Chinese language and culture are scarce. More importantly, these datasets usually only support single evaluation tasks and cannot evaluate the bias from multiple aspects in LLMs. To address these issues, we present a Multi-task Chinese Bias Evaluation Benchmark (McBE) that includes 4,077 bias evaluation instances, covering 12 single bias categories, 82 subcategories and introducing 5 evaluation tasks, providing extensive category coverage, content diversity, and measuring comprehensiveness. Additionally, we evaluate several popular LLMs from different series and with parameter sizes. In general, all these LLMs demonstrated varying degrees of bias. We conduct an in-depth analysis of results, offering novel insights into bias in LLMs.
Unifying Dual-Space Embedding for Entity Alignment via Contrastive Learning
Dec 06, 2024



Entity alignment aims to match identical entities across different knowledge graphs (KGs). Graph neural network-based entity alignment methods have achieved promising results in Euclidean space. However, KGs often contain complex structures, including both local and hierarchical ones, which make it challenging to efficiently represent them within a single space. In this paper, we proposed a novel method UniEA, which unifies dual-space embedding to preserve the intrinsic structure of KGs. Specifically, we learn graph structure embedding in both Euclidean and hyperbolic spaces simultaneously to maximize the consistency between the embedding in both spaces. Moreover, we employ contrastive learning to mitigate the misalignment issues caused by similar entities, where embedding of similar neighboring entities within the KG become too close in distance. Extensive experiments on benchmark datasets demonstrate that our method achieves state-of-the-art performance in structure-based EA. Our code is available at https://github.com/wonderCS1213/UniEA.
Distance-Adaptive Quaternion Knowledge Graph Embedding with Bidirectional Rotation
Dec 05, 2024



Quaternion contains one real part and three imaginary parts, which provided a more expressive hypercomplex space for learning knowledge graph. Existing quaternion embedding models measure the plausibility of a triplet either through semantic matching or geometric distance scoring functions. However, it appears that semantic matching diminishes the separability of entities, while the distance scoring function weakens the semantics of entities. To address this issue, we propose a novel quaternion knowledge graph embedding model. Our model combines semantic matching with entity's geometric distance to better measure the plausibility of triplets. Specifically, in the quaternion space, we perform a right rotation on head entity and a reverse rotation on tail entity to learn rich semantic features. Then, we utilize distance adaptive translations to learn geometric distance between entities. Furthermore, we provide mathematical proofs to demonstrate our model can handle complex logical relationships. Extensive experimental results and analyses show our model significantly outperforms previous models on well-known knowledge graph completion benchmark datasets. Our code is available at https://github.com/llqy123/DaBR.
Fully Hyperbolic Rotation for Knowledge Graph Embedding
Nov 07, 2024

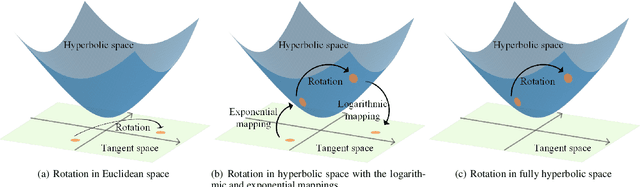
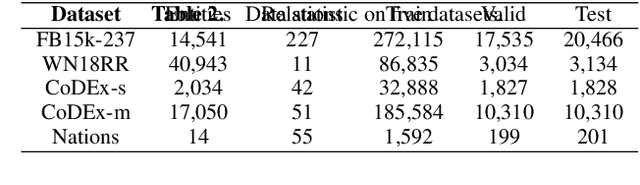
Hyperbolic rotation is commonly used to effectively model knowledge graphs and their inherent hierarchies. However, existing hyperbolic rotation models rely on logarithmic and exponential mappings for feature transformation. These models only project data features into hyperbolic space for rotation, limiting their ability to fully exploit the hyperbolic space. To address this problem, we propose a novel fully hyperbolic model designed for knowledge graph embedding. Instead of feature mappings, we define the model directly in hyperbolic space with the Lorentz model. Our model considers each relation in knowledge graphs as a Lorentz rotation from the head entity to the tail entity. We adopt the Lorentzian version distance as the scoring function for measuring the plausibility of triplets. Extensive results on standard knowledge graph completion benchmarks demonstrated that our model achieves competitive results with fewer parameters. In addition, our model get the state-of-the-art performance on datasets of CoDEx-s and CoDEx-m, which are more diverse and challenging than before. Our code is available at https://github.com/llqy123/FHRE.
MCDubber: Multimodal Context-Aware Expressive Video Dubbing
Aug 21, 2024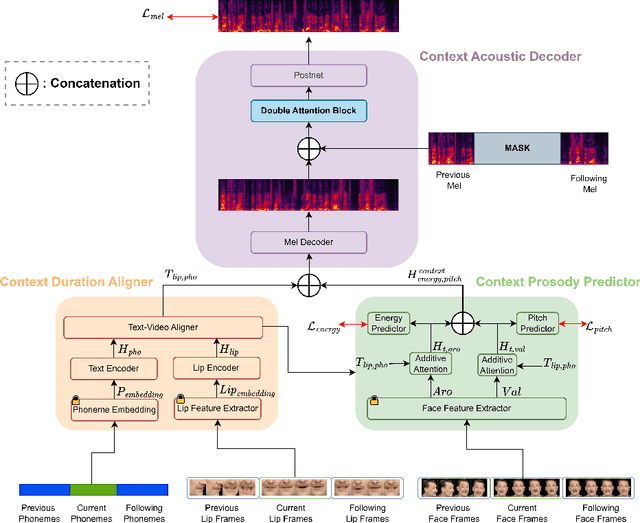
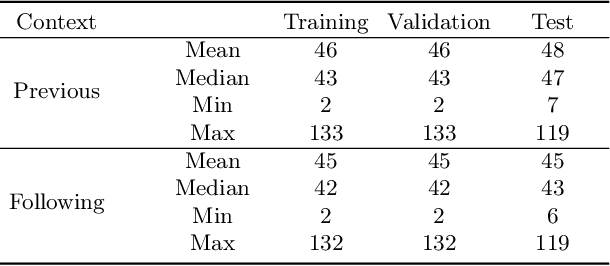
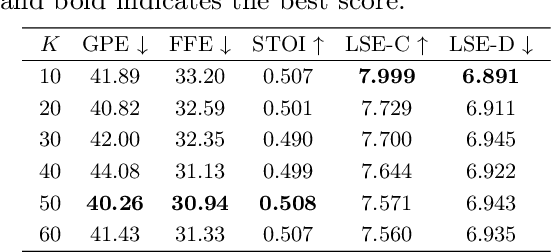
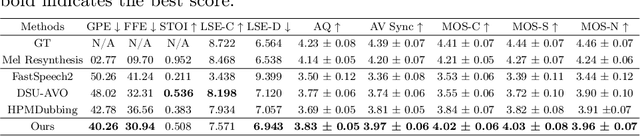
Automatic Video Dubbing (AVD) aims to take the given script and generate speech that aligns with lip motion and prosody expressiveness. Current AVD models mainly utilize visual information of the current sentence to enhance the prosody of synthesized speech. However, it is crucial to consider whether the prosody of the generated dubbing aligns with the multimodal context, as the dubbing will be combined with the original context in the final video. This aspect has been overlooked in previous studies. To address this issue, we propose a Multimodal Context-aware video Dubbing model, termed \textbf{MCDubber}, to convert the modeling object from a single sentence to a longer sequence with context information to ensure the consistency of the global context prosody. MCDubber comprises three main components: (1) A context duration aligner aims to learn the context-aware alignment between the text and lip frames; (2) A context prosody predictor seeks to read the global context visual sequence and predict the context-aware global energy and pitch; (3) A context acoustic decoder ultimately predicts the global context mel-spectrogram with the assistance of adjacent ground-truth mel-spectrograms of the target sentence. Through this process, MCDubber fully considers the influence of multimodal context on the prosody expressiveness of the current sentence when dubbing. The extracted mel-spectrogram belonging to the target sentence from the output context mel-spectrograms is the final required dubbing audio. Extensive experiments on the Chem benchmark dataset demonstrate that our MCDubber significantly improves dubbing expressiveness compared to all advanced baselines. The code and demos are available at https://github.com/XiaoYuanJun-zy/MCDubber.
Mitigating Heterogeneity among Factor Tensors via Lie Group Manifolds for Tensor Decomposition Based Temporal Knowledge Graph Embedding
Apr 14, 2024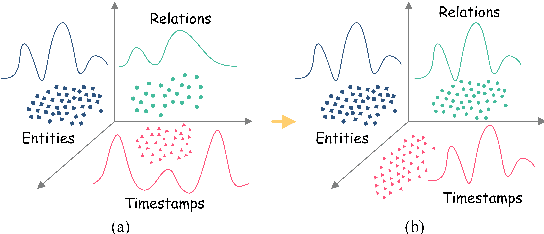
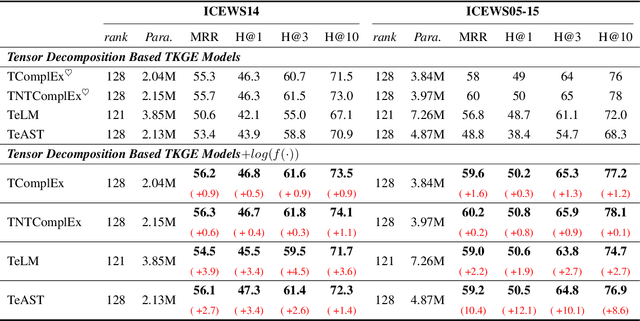
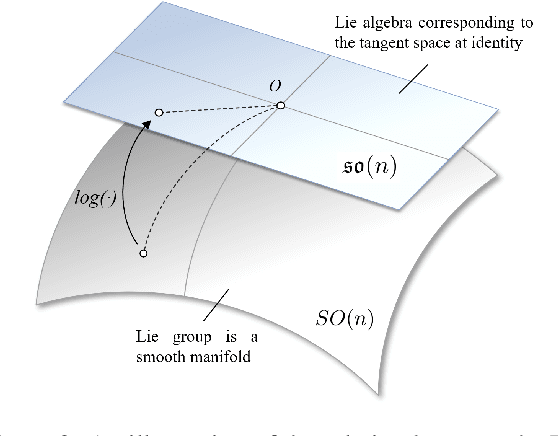
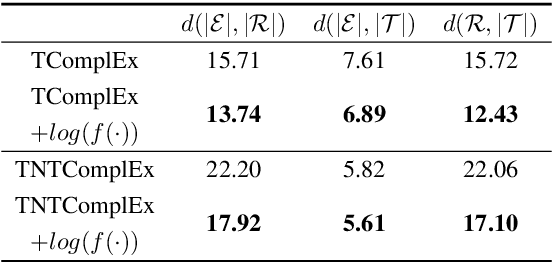
Recent studies have highlighted the effectiveness of tensor decomposition methods in the Temporal Knowledge Graphs Embedding (TKGE) task. However, we found that inherent heterogeneity among factor tensors in tensor decomposition significantly hinders the tensor fusion process and further limits the performance of link prediction. To overcome this limitation, we introduce a novel method that maps factor tensors onto a unified smooth Lie group manifold to make the distribution of factor tensors approximating homogeneous in tensor decomposition. We provide the theoretical proof of our motivation that homogeneous tensors are more effective than heterogeneous tensors in tensor fusion and approximating the target for tensor decomposition based TKGE methods. The proposed method can be directly integrated into existing tensor decomposition based TKGE methods without introducing extra parameters. Extensive experiments demonstrate the effectiveness of our method in mitigating the heterogeneity and in enhancing the tensor decomposition based TKGE models.
L$^2$GC: Lorentzian Linear Graph Convolutional Networks For Node Classification
Mar 10, 2024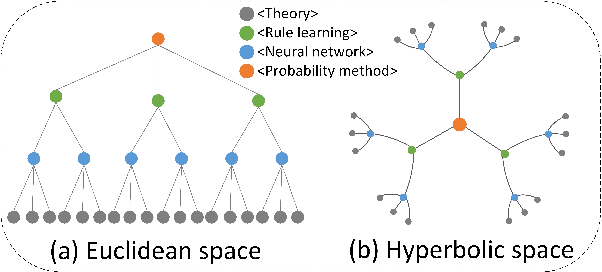
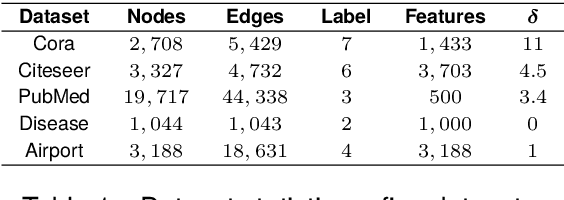
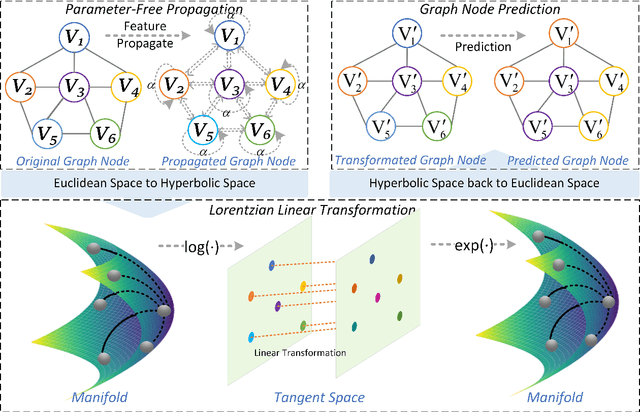
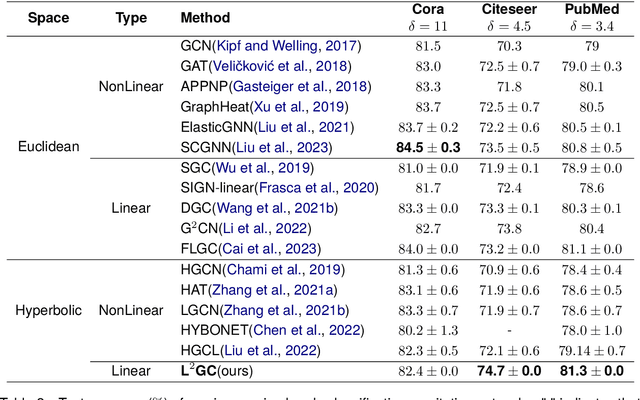
Linear Graph Convolutional Networks (GCNs) are used to classify the node in the graph data. However, we note that most existing linear GCN models perform neural network operations in Euclidean space, which do not explicitly capture the tree-like hierarchical structure exhibited in real-world datasets that modeled as graphs. In this paper, we attempt to introduce hyperbolic space into linear GCN and propose a novel framework for Lorentzian linear GCN. Specifically, we map the learned features of graph nodes into hyperbolic space, and then perform a Lorentzian linear feature transformation to capture the underlying tree-like structure of data. Experimental results on standard citation networks datasets with semi-supervised learning show that our approach yields new state-of-the-art results of accuracy 74.7$\%$ on Citeseer and 81.3$\%$ on PubMed datasets. Furthermore, we observe that our approach can be trained up to two orders of magnitude faster than other nonlinear GCN models on PubMed dataset. Our code is publicly available at https://github.com/llqy123/LLGC-master.
Betray Oneself: A Novel Audio DeepFake Detection Model via Mono-to-Stereo Conversion
May 25, 2023Audio Deepfake Detection (ADD) aims to detect the fake audio generated by text-to-speech (TTS), voice conversion (VC) and replay, etc., which is an emerging topic. Traditionally we take the mono signal as input and focus on robust feature extraction and effective classifier design. However, the dual-channel stereo information in the audio signal also includes important cues for deepfake, which has not been studied in the prior work. In this paper, we propose a novel ADD model, termed as M2S-ADD, that attempts to discover audio authenticity cues during the mono-to-stereo conversion process. We first projects the mono to a stereo signal using a pretrained stereo synthesizer, then employs a dual-branch neural architecture to process the left and right channel signals, respectively. In this way, we effectively reveal the artifacts in the fake audio, thus improve the ADD performance. The experiments on the ASVspoof2019 database show that M2S-ADD outperforms all baselines that input mono. We release the source code at \url{https://github.com/AI-S2-Lab/M2S-ADD}.
FCTalker: Fine and Coarse Grained Context Modeling for Expressive Conversational Speech Synthesis
Oct 27, 2022Conversational Text-to-Speech (TTS) aims to synthesis an utterance with the right linguistic and affective prosody in a conversational context. The correlation between the current utterance and the dialogue history at the utterance level was used to improve the expressiveness of synthesized speech. However, the fine-grained information in the dialogue history at the word level also has an important impact on the prosodic expression of an utterance, which has not been well studied in the prior work. Therefore, we propose a novel expressive conversational TTS model, termed as FCTalker, that learn the fine and coarse grained context dependency at the same time during speech generation. Specifically, the FCTalker includes fine and coarse grained encoders to exploit the word and utterance-level context dependency. To model the word-level dependencies between an utterance and its dialogue history, the fine-grained dialogue encoder is built on top of a dialogue BERT model. The experimental results show that the proposed method outperforms all baselines and generates more expressive speech that is contextually appropriate. We release the source code at: https://github.com/walker-hyf/FCTalker.