 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion and Intent Joint Understanding in Multimodal Conversation: A Benchmarking Dataset
Jul 03, 2024


Emotion and Intent Joint Understanding in Multimodal Conversation (MC-EIU) aims to decode the semantic information manifested in a multimodal conversational history, while inferring the emotions and intents simultaneously for the current utterance. MC-EIU is enabling technology for many human-computer interfaces. However, there is a lack of available datasets in terms of annotation, modality, language diversity, and accessibility. In this work, we propose an MC-EIU dataset, which features 7 emotion categories, 9 intent categories, 3 modalities, i.e., textual, acoustic, and visual content, and two languages, i.e., English and Mandarin. Furthermore, it is completely open-source for free access. To our knowledge, MC-EIU is the first comprehensive and rich emotion and intent joint understanding dataset for multimodal conversation. Together with the release of the dataset, we also develop an Emotion and Intent Interaction (EI$^2$) network as a reference system by modeling the deep correlation between emotion and intent in the multimodal conversation. With comparative experiments and ablation studies, we demonstrate the effectiveness of the proposed EI$^2$ method on the MC-EIU dataset. The dataset and codes will be made available at: https://github.com/MC-EIU/MC-EIU.
Exploiting modality-invariant feature for robust multimodal emotion recognition with missing modalities
Oct 27, 2022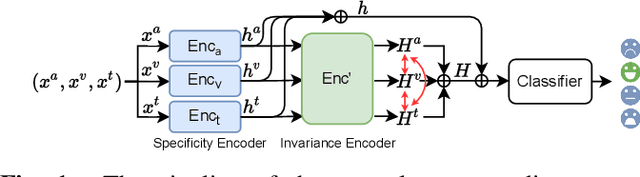

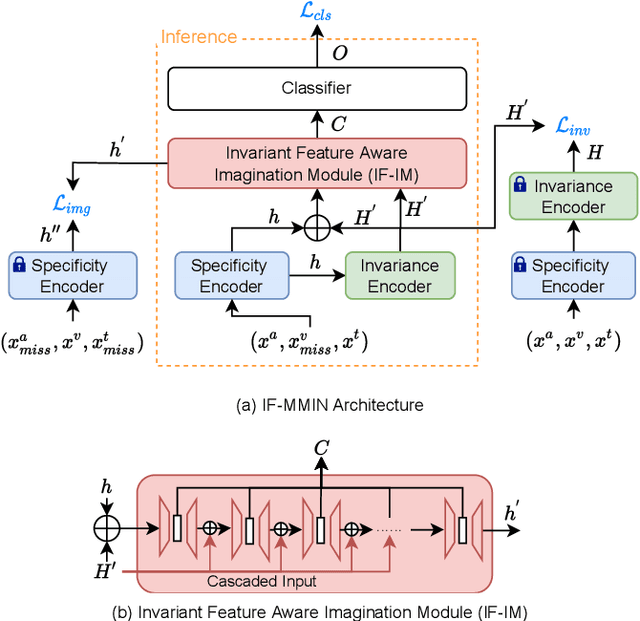
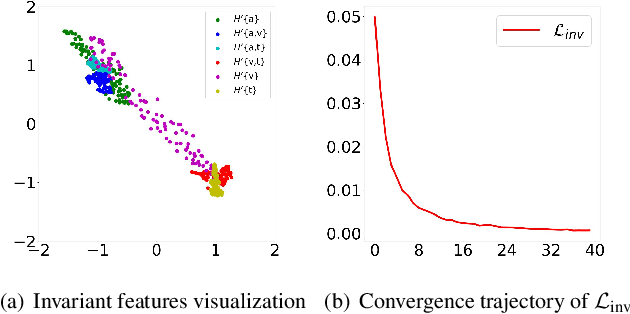
Multimodal emotion recognition leverages complementary information across modalities to gain performance. However, we cannot guarantee that the data of all modalities are always present in practice. In the studies to predict the missing data across modalities, the inherent difference between heterogeneous modalities, namely the modality gap, presents a challenge. To address this, we propose to use invariant features for a missing modality imagination network (IF-MMIN) which includes two novel mechanisms: 1) an invariant feature learning strategy that is based on the central moment discrepancy (CMD) distance under the full-modality scenario; 2) an invariant feature based imagination module (IF-IM) to alleviate the modality gap during the missing modalities prediction, thus improving the robustness of multimodal joint representation. Comprehensive experiments on the benchmark dataset IEMOCAP demonstrate that the proposed model outperforms all baselines and invariantly improves the overall emotion recognition performance under uncertain missing-modality conditions. We release the code at: https://github.com/ZhuoYulang/IF-MMIN.
Explicit Intensity Control for Accented Text-to-speech
Oct 27, 2022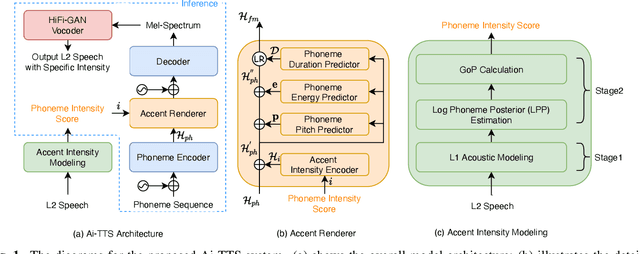
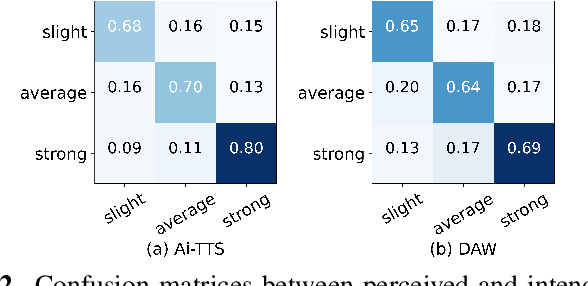
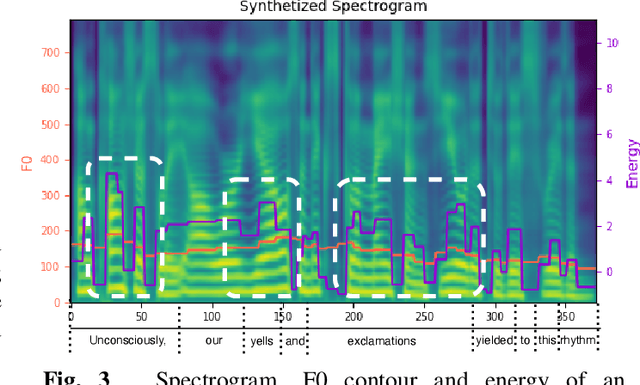
Accented text-to-speech (TTS) synthesis seeks to generate speech with an accent (L2) as a variant of the standard version (L1). How to control the intensity of accent in the process of TTS is a very interesting research direction, and has attracted more and more attention. Recent work design a speaker-adversarial loss to disentangle the speaker and accent information, and then adjust the loss weight to control the accent intensity. However, such a control method lacks interpretability, and there is no direct correlation between the controlling factor and natural accent intensity. To this end, this paper propose a new intuitive and explicit accent intensity control scheme for accented TTS. Specifically, we first extract the posterior probability, called as ``goodness of pronunciation (GoP)'' from the L1 speech recognition model to quantify the phoneme accent intensity for accented speech, then design a FastSpeech2 based TTS model, named Ai-TTS, to take the accent intensity expression into account during speech generation. Experiments show that the our method outperforms the baseline model in terms of accent rendering and intensity control.