 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting modality-invariant feature for robust multimodal emotion recognition with missing modalities
Paper and Code
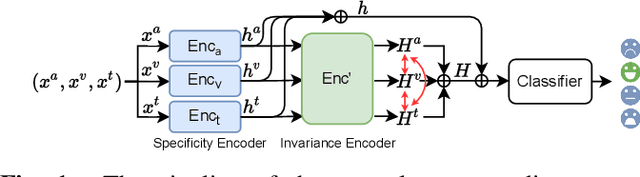

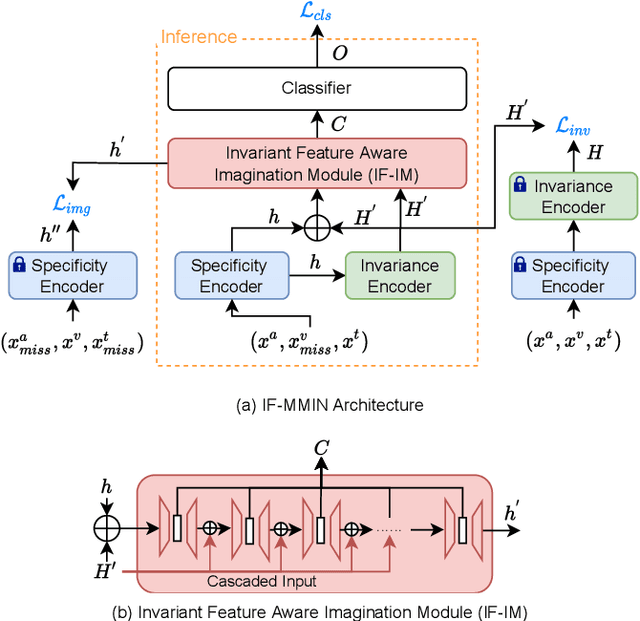
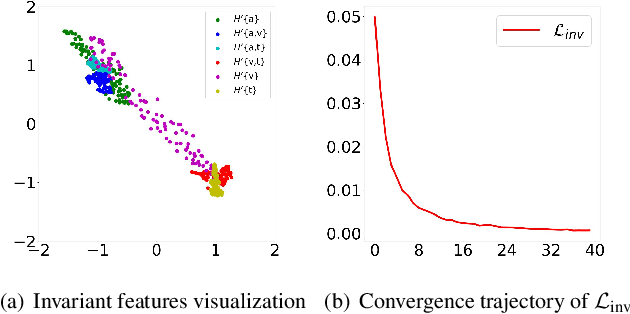
Multimodal emotion recognition leverages complementary information across modalities to gain performance. However, we cannot guarantee that the data of all modalities are always present in practice. In the studies to predict the missing data across modalities, the inherent difference between heterogeneous modalities, namely the modality gap, presents a challenge. To address this, we propose to use invariant features for a missing modality imagination network (IF-MMIN) which includes two novel mechanisms: 1) an invariant feature learning strategy that is based on the central moment discrepancy (CMD) distance under the full-modality scenario; 2) an invariant feature based imagination module (IF-IM) to alleviate the modality gap during the missing modalities prediction, thus improving the robustness of multimodal joint representation. Comprehensive experiments on the benchmark dataset IEMOCAP demonstrate that the proposed model outperforms all baselines and invariantly improves the overall emotion recognition performance under uncertain missing-modality conditions. We release the code at: https://github.com/ZhuoYulang/IF-MMIN.