 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Intensity Control for Accented Text-to-speech
Paper and Code
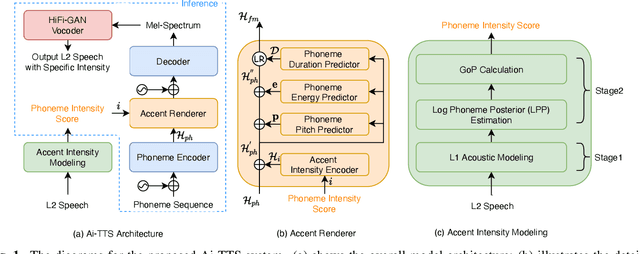
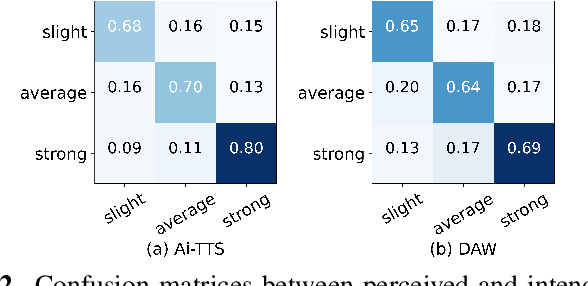
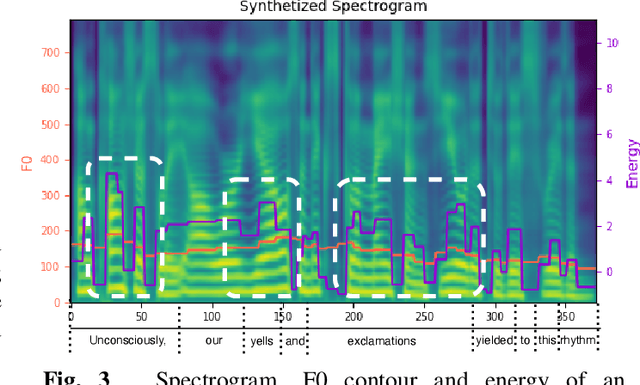
Accented text-to-speech (TTS) synthesis seeks to generate speech with an accent (L2) as a variant of the standard version (L1). How to control the intensity of accent in the process of TTS is a very interesting research direction, and has attracted more and more attention. Recent work design a speaker-adversarial loss to disentangle the speaker and accent information, and then adjust the loss weight to control the accent intensity. However, such a control method lacks interpretability, and there is no direct correlation between the controlling factor and natural accent intensity. To this end, this paper propose a new intuitive and explicit accent intensity control scheme for accented TTS. Specifically, we first extract the posterior probability, called as ``goodness of pronunciation (GoP)'' from the L1 speech recognition model to quantify the phoneme accent intensity for accented speech, then design a FastSpeech2 based TTS model, named Ai-TTS, to take the accent intensity expression into account during speech generation. Experiments show that the our method outperforms the baseline model in terms of accent rendering and intensity control.