 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWisteria: A Unified Multi-Scale Feature Learning Framework for DNA Language Model
May 07, 2026DNA language model aims to decipher the regulatory grammar and semantic of genomes by capturing long range dependencies in DNA sequences. Existing methods emphasize long range token interactions but often ignore the interplay between local motifs and global dependencies. In this paper, we propose Wisteria, a genomic language model that integrates multi scale feature learning within a unified framework for DNA sequence. Specifically, Wisteria augments the Mamba based architecture with gated dilated convolutions to capture local motifs and regulatory patterns, while gated multilayer perceptrons refine global dependencies. We further introduce a Fourier based attention mechanism to support frequency domain modeling, periodic extension and length generalization. Across four experimental settings with both short and long range dependencies, Wisteria demonstrates strong performance on downstream benchmarks against competitive DNA language model baselines. These results indicate that Wisteria effectively unifies local and global dependency modeling for multi scale genomic sequence analysis.
Debate to Align: Reliable Entity Alignment through Two-Stage Multi-Agent Debate
Apr 15, 2026Entity alignment (EA) aims to identify entities referring to the same real-world object across different knowledge graphs (KGs). Recent approaches based on large language models (LLMs) typically obtain entity embeddings through knowledge representation learning and use embedding similarity to identify an alignment-uncertain entity set. For each uncertain entity, a candidate entity set (CES) is then retrieved based on embedding similarity to support subsequent alignment reasoning and decision making. However, the reliability of the CES and the reasoning capability of LLMs critically affect the effectiveness of subsequent alignment decisions. To address this issue, we propose AgentEA, a reliable EA framework based on multi-agent debate. AgentEA first improves embedding quality through entity representation preference optimization, and then introduces a two-stage multi-role debate mechanism consisting of lightweight debate verification and deep debate alignment to progressively enhance the reliability of alignment decisions while enabling more efficient debate-based reasoning. Extensive experiments on public benchmarks under cross-lingual, sparse, large-scale, and heterogeneous settings demonstrate the effectiveness of AgentEA.
Retrieval-Augmented Dialogue Knowledge Aggregation for Expressive Conversational Speech Synthesis
Jan 11, 2025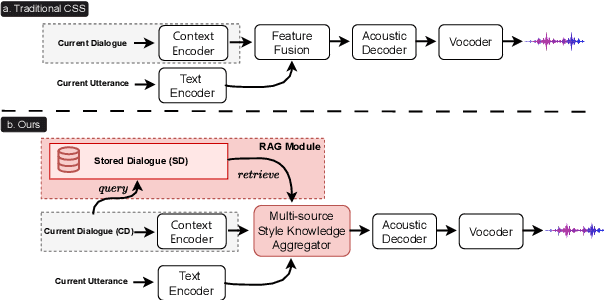
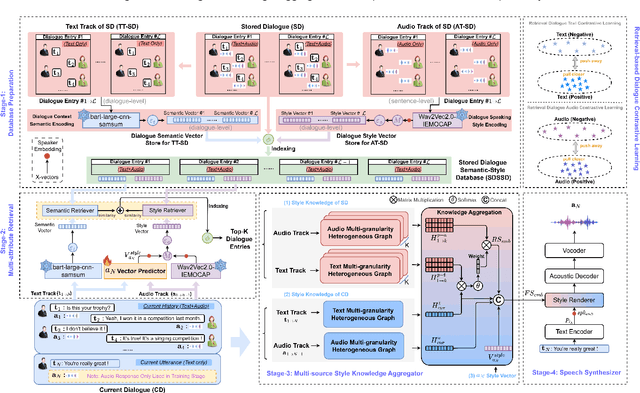

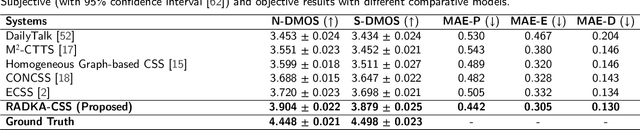
Conversational speech synthesis (CSS) aims to take the current dialogue (CD) history as a reference to synthesize expressive speech that aligns with the conversational style. Unlike CD, stored dialogue (SD) contains preserved dialogue fragments from earlier stages of user-agent interaction, which include style expression knowledge relevant to scenarios similar to those in CD. Note that this knowledge plays a significant role in enabling the agent to synthesize expressive conversational speech that generates empathetic feedback. However, prior research has overlooked this aspect. To address this issue, we propose a novel Retrieval-Augmented Dialogue Knowledge Aggregation scheme for expressive CSS, termed RADKA-CSS, which includes three main components: 1) To effectively retrieve dialogues from SD that are similar to CD in terms of both semantic and style. First, we build a stored dialogue semantic-style database (SDSSD) which includes the text and audio samples. Then, we design a multi-attribute retrieval scheme to match the dialogue semantic and style vectors of the CD with the stored dialogue semantic and style vectors in the SDSSD, retrieving the most similar dialogues. 2) To effectively utilize the style knowledge from CD and SD, we propose adopting the multi-granularity graph structure to encode the dialogue and introducing a multi-source style knowledge aggregation mechanism. 3) Finally, the aggregated style knowledge are fed into the speech synthesizer to help the agent synthesize expressive speech that aligns with the conversational style. We conducted a comprehensive and in-depth experiment based on the DailyTalk dataset, which is a benchmarking dataset for the CSS task. Both objective and subjective evaluations demonstrate that RADKA-CSS outperforms baseline models in expressiveness rendering. Code and audio samples can be found at: https://github.com/Coder-jzq/RADKA-CSS.
Unifying Dual-Space Embedding for Entity Alignment via Contrastive Learning
Dec 06, 2024



Entity alignment aims to match identical entities across different knowledge graphs (KGs). Graph neural network-based entity alignment methods have achieved promising results in Euclidean space. However, KGs often contain complex structures, including both local and hierarchical ones, which make it challenging to efficiently represent them within a single space. In this paper, we proposed a novel method UniEA, which unifies dual-space embedding to preserve the intrinsic structure of KGs. Specifically, we learn graph structure embedding in both Euclidean and hyperbolic spaces simultaneously to maximize the consistency between the embedding in both spaces. Moreover, we employ contrastive learning to mitigate the misalignment issues caused by similar entities, where embedding of similar neighboring entities within the KG become too close in distance. Extensive experiments on benchmark datasets demonstrate that our method achieves state-of-the-art performance in structure-based EA. Our code is available at https://github.com/wonderCS1213/UniEA.
Distance-Adaptive Quaternion Knowledge Graph Embedding with Bidirectional Rotation
Dec 05, 2024



Quaternion contains one real part and three imaginary parts, which provided a more expressive hypercomplex space for learning knowledge graph. Existing quaternion embedding models measure the plausibility of a triplet either through semantic matching or geometric distance scoring functions. However, it appears that semantic matching diminishes the separability of entities, while the distance scoring function weakens the semantics of entities. To address this issue, we propose a novel quaternion knowledge graph embedding model. Our model combines semantic matching with entity's geometric distance to better measure the plausibility of triplets. Specifically, in the quaternion space, we perform a right rotation on head entity and a reverse rotation on tail entity to learn rich semantic features. Then, we utilize distance adaptive translations to learn geometric distance between entities. Furthermore, we provide mathematical proofs to demonstrate our model can handle complex logical relationships. Extensive experimental results and analyses show our model significantly outperforms previous models on well-known knowledge graph completion benchmark datasets. Our code is available at https://github.com/llqy123/DaBR.
Fully Hyperbolic Rotation for Knowledge Graph Embedding
Nov 07, 2024

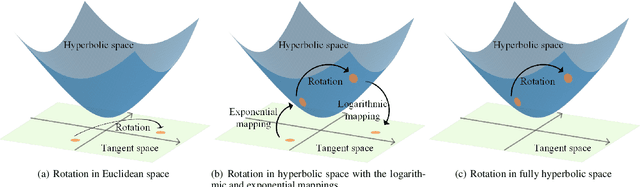
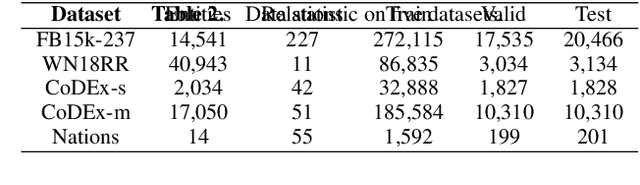
Hyperbolic rotation is commonly used to effectively model knowledge graphs and their inherent hierarchies. However, existing hyperbolic rotation models rely on logarithmic and exponential mappings for feature transformation. These models only project data features into hyperbolic space for rotation, limiting their ability to fully exploit the hyperbolic space. To address this problem, we propose a novel fully hyperbolic model designed for knowledge graph embedding. Instead of feature mappings, we define the model directly in hyperbolic space with the Lorentz model. Our model considers each relation in knowledge graphs as a Lorentz rotation from the head entity to the tail entity. We adopt the Lorentzian version distance as the scoring function for measuring the plausibility of triplets. Extensive results on standard knowledge graph completion benchmarks demonstrated that our model achieves competitive results with fewer parameters. In addition, our model get the state-of-the-art performance on datasets of CoDEx-s and CoDEx-m, which are more diverse and challenging than before. Our code is available at https://github.com/llqy123/FHRE.
MCDubber: Multimodal Context-Aware Expressive Video Dubbing
Aug 21, 2024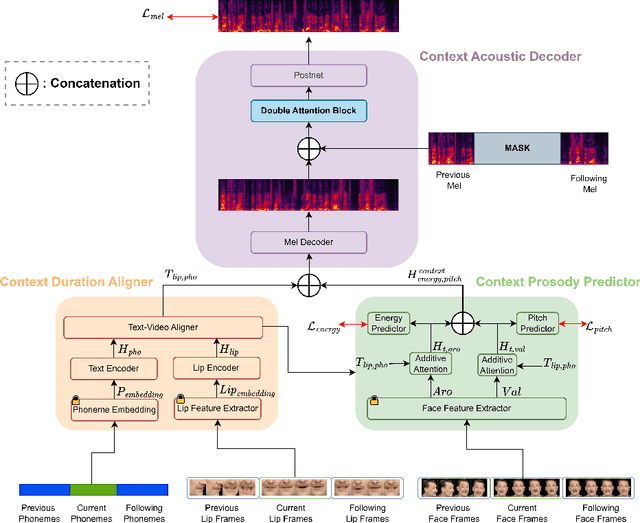
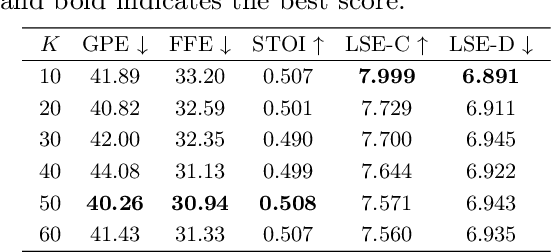
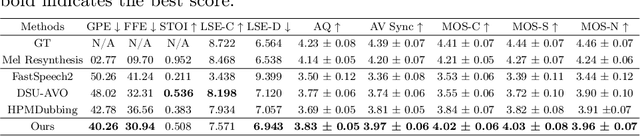
Automatic Video Dubbing (AVD) aims to take the given script and generate speech that aligns with lip motion and prosody expressiveness. Current AVD models mainly utilize visual information of the current sentence to enhance the prosody of synthesized speech. However, it is crucial to consider whether the prosody of the generated dubbing aligns with the multimodal context, as the dubbing will be combined with the original context in the final video. This aspect has been overlooked in previous studies. To address this issue, we propose a Multimodal Context-aware video Dubbing model, termed \textbf{MCDubber}, to convert the modeling object from a single sentence to a longer sequence with context information to ensure the consistency of the global context prosody. MCDubber comprises three main components: (1) A context duration aligner aims to learn the context-aware alignment between the text and lip frames; (2) A context prosody predictor seeks to read the global context visual sequence and predict the context-aware global energy and pitch; (3) A context acoustic decoder ultimately predicts the global context mel-spectrogram with the assistance of adjacent ground-truth mel-spectrograms of the target sentence. Through this process, MCDubber fully considers the influence of multimodal context on the prosody expressiveness of the current sentence when dubbing. The extracted mel-spectrogram belonging to the target sentence from the output context mel-spectrograms is the final required dubbing audio. Extensive experiments on the Chem benchmark dataset demonstrate that our MCDubber significantly improves dubbing expressiveness compared to all advanced baselines. The code and demos are available at https://github.com/XiaoYuanJun-zy/MCDubber.
L$^2$GC: Lorentzian Linear Graph Convolutional Networks For Node Classification
Mar 10, 2024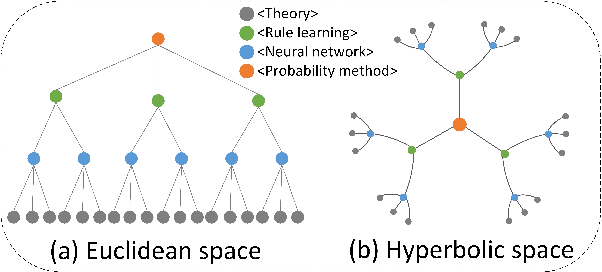
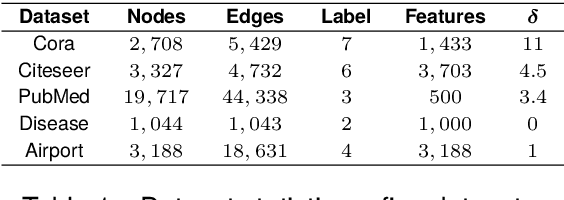
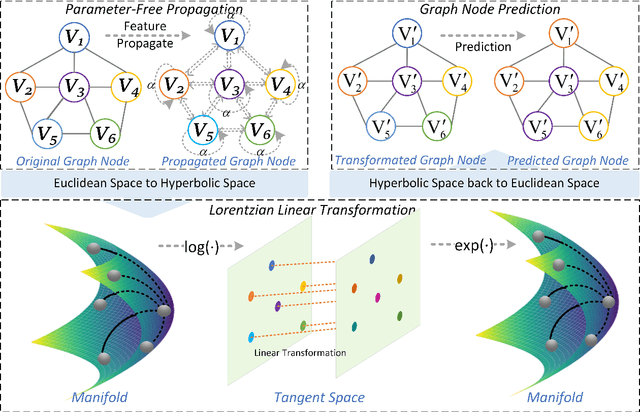
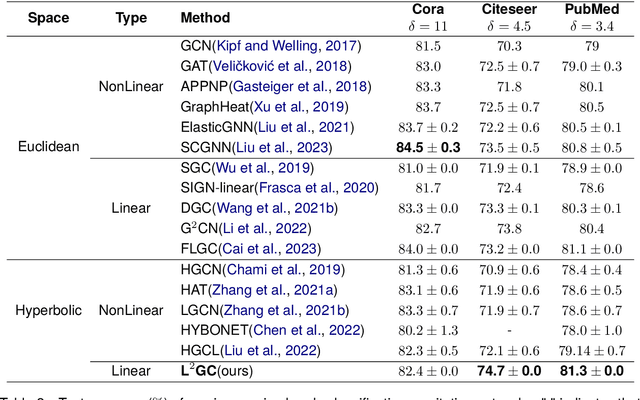
Linear Graph Convolutional Networks (GCNs) are used to classify the node in the graph data. However, we note that most existing linear GCN models perform neural network operations in Euclidean space, which do not explicitly capture the tree-like hierarchical structure exhibited in real-world datasets that modeled as graphs. In this paper, we attempt to introduce hyperbolic space into linear GCN and propose a novel framework for Lorentzian linear GCN. Specifically, we map the learned features of graph nodes into hyperbolic space, and then perform a Lorentzian linear feature transformation to capture the underlying tree-like structure of data. Experimental results on standard citation networks datasets with semi-supervised learning show that our approach yields new state-of-the-art results of accuracy 74.7$\%$ on Citeseer and 81.3$\%$ on PubMed datasets. Furthermore, we observe that our approach can be trained up to two orders of magnitude faster than other nonlinear GCN models on PubMed dataset. Our code is publicly available at https://github.com/llqy123/LLGC-master.
MnTTS: An Open-Source Mongolian Text-to-Speech Synthesis Dataset and Accompanied Baseline
Sep 22, 2022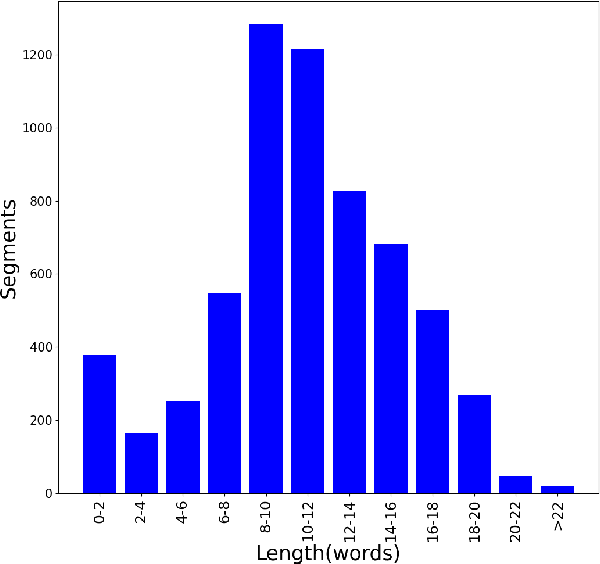
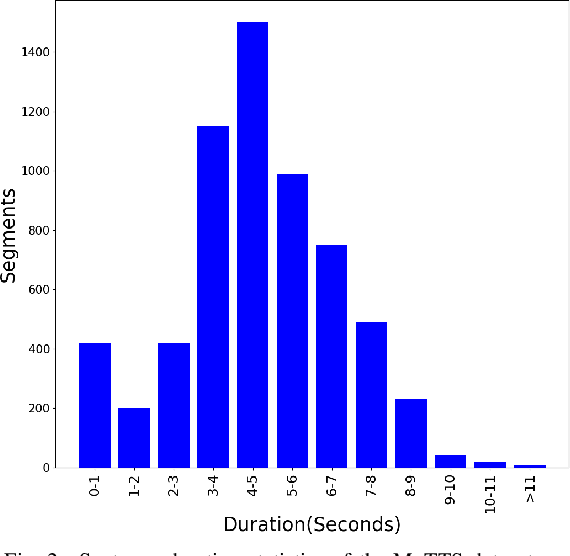
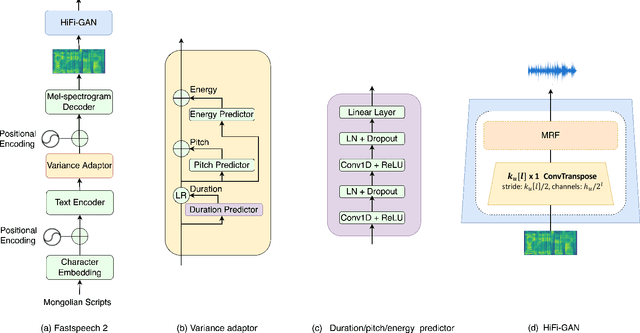
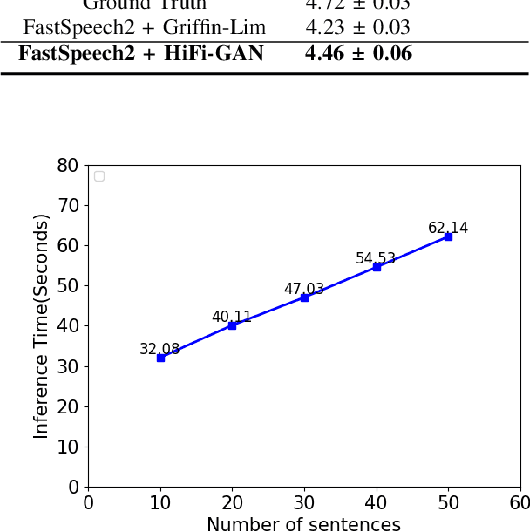
This paper introduces a high-quality open-source text-to-speech (TTS) synthesis dataset for Mongolian, a low-resource language spoken by over 10 million people worldwide. The dataset, named MnTTS, consists of about 8 hours of transcribed audio recordings spoken by a 22-year-old professional female Mongolian announcer. It is the first publicly available dataset developed to promote Mongolian TTS applications in both academia and industry. In this paper, we share our experience by describing the dataset development procedures and faced challenges. To demonstrate the reliability of our dataset, we built a powerful non-autoregressive baseline system based on FastSpeech2 model and HiFi-GAN vocoder, and evaluated it using the subjective mean opinion score (MOS) and real time factor (RTF) metrics. Evaluation results show that the powerful baseline system trained on our dataset achieves MOS above 4 and RTF about $3.30\times10^{-1}$, which makes it applicable for practical use. The dataset, training recipe, and pretrained TTS models are freely available \footnote{\label{github}\url{https://github.com/walker-hyf/MnTTS}}.
Modeling Prosodic Phrasing with Multi-Task Learning in Tacotron-based TTS
Aug 11, 2020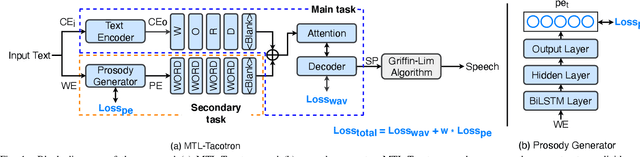
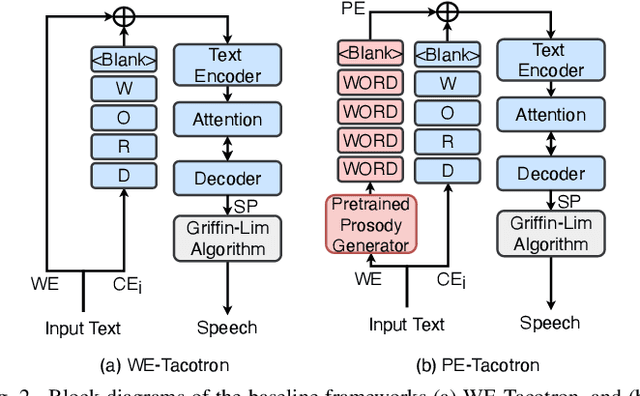
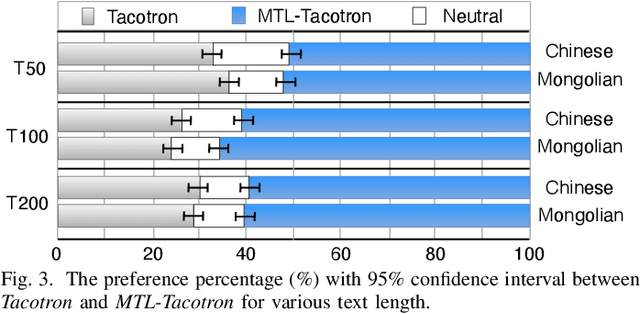
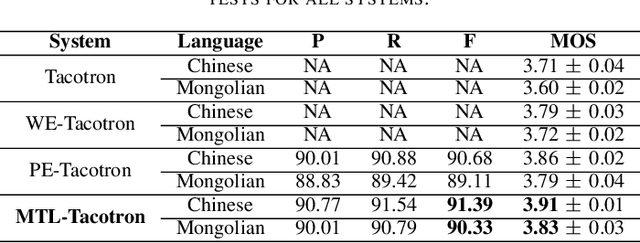
Tacotron-based end-to-end speech synthesis has shown remarkable voice quality. However, the rendering of prosody in the synthesized speech remains to be improved, especially for long sentences, where prosodic phrasing errors can occur frequently. In this paper, we extend the Tacotron-based speech synthesis framework to explicitly model the prosodic phrase breaks. We propose a multi-task learning scheme for Tacotron training, that optimizes the system to predict both Mel spectrum and phrase breaks. To our best knowledge, this is the first implementation of multi-task learning for Tacotron based TTS with a prosodic phrasing model. Experiments show that our proposed training scheme consistently improves the voice quality for both Chinese and Mongolian systems.