 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCDubber: Multimodal Context-Aware Expressive Video Dubbing
Paper and Code
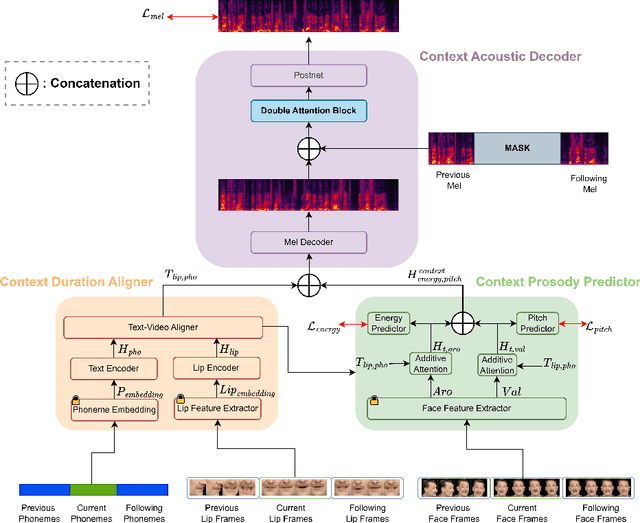
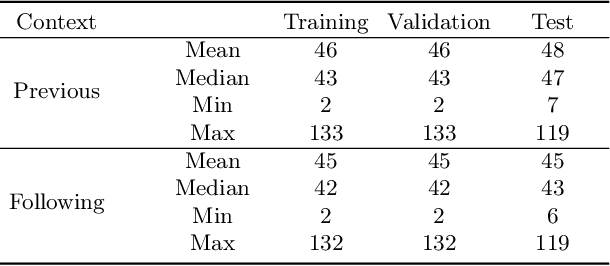
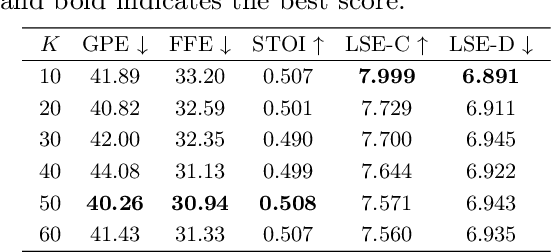
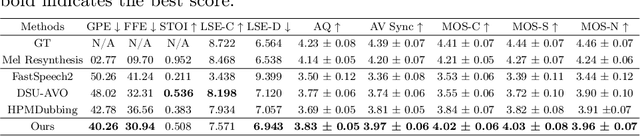
Automatic Video Dubbing (AVD) aims to take the given script and generate speech that aligns with lip motion and prosody expressiveness. Current AVD models mainly utilize visual information of the current sentence to enhance the prosody of synthesized speech. However, it is crucial to consider whether the prosody of the generated dubbing aligns with the multimodal context, as the dubbing will be combined with the original context in the final video. This aspect has been overlooked in previous studies. To address this issue, we propose a Multimodal Context-aware video Dubbing model, termed \textbf{MCDubber}, to convert the modeling object from a single sentence to a longer sequence with context information to ensure the consistency of the global context prosody. MCDubber comprises three main components: (1) A context duration aligner aims to learn the context-aware alignment between the text and lip frames; (2) A context prosody predictor seeks to read the global context visual sequence and predict the context-aware global energy and pitch; (3) A context acoustic decoder ultimately predicts the global context mel-spectrogram with the assistance of adjacent ground-truth mel-spectrograms of the target sentence. Through this process, MCDubber fully considers the influence of multimodal context on the prosody expressiveness of the current sentence when dubbing. The extracted mel-spectrogram belonging to the target sentence from the output context mel-spectrograms is the final required dubbing audio. Extensive experiments on the Chem benchmark dataset demonstrate that our MCDubber significantly improves dubbing expressiveness compared to all advanced baselines. The code and demos are available at https://github.com/XiaoYuanJun-zy/MCDubber.