 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveTTS: Tacotron-based TTS with Joint Time-Frequency Domain Loss
Paper and Code
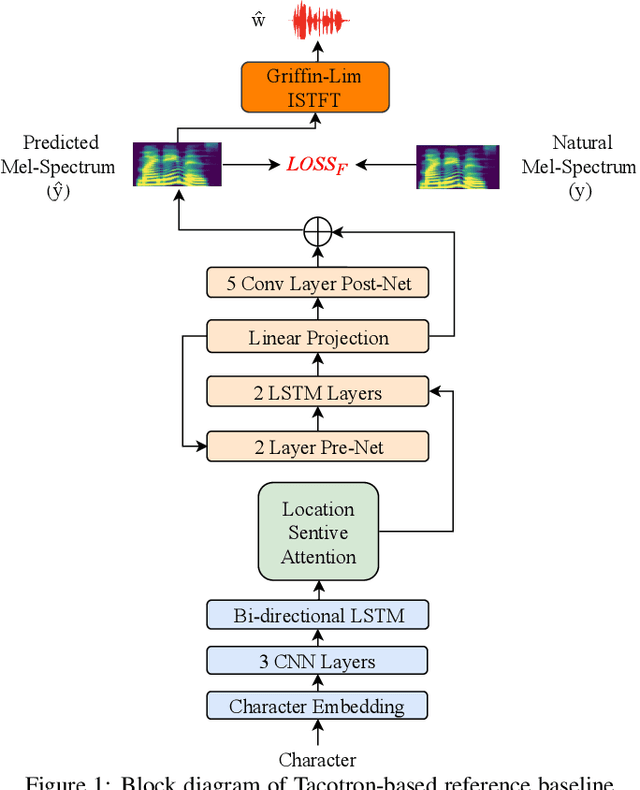

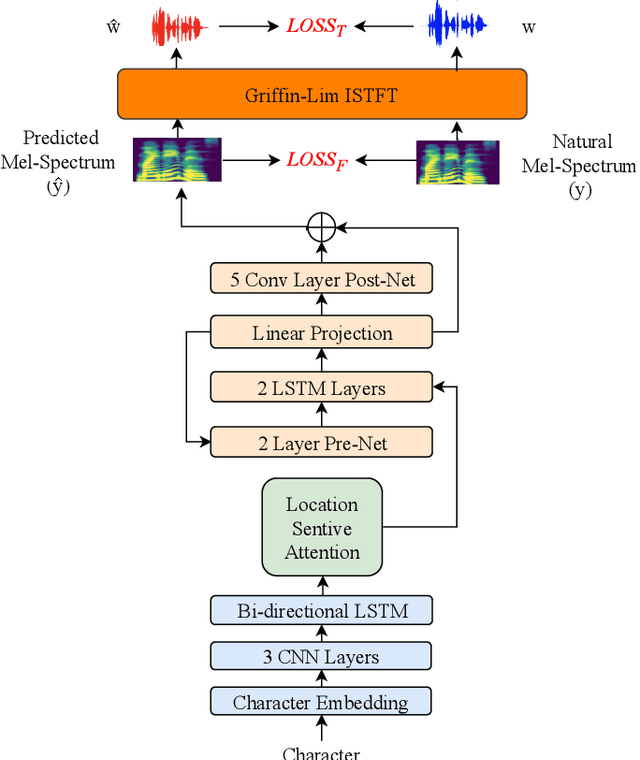
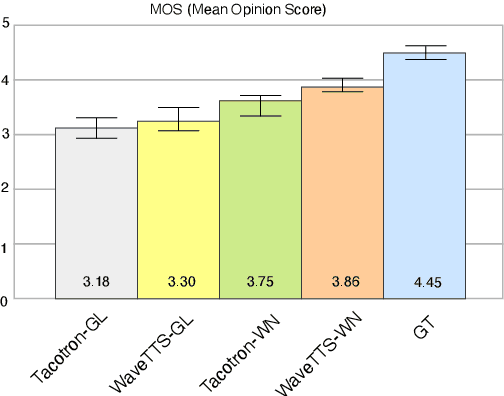
Tacotron-based text-to-speech (TTS) systems directly synthesize speech from text input. Such frameworks typically consist of a feature prediction network that maps character sequences to frequency-domain acoustic features, followed by a waveform reconstruction algorithm or a neural vocoder that generates the time-domain waveform from acoustic features. As the loss function is usually calculated only for frequency-domain acoustic features, that doesn't directly control the quality of the generated time-domain waveform. To address this problem, we propose a new training scheme for Tacotron-based TTS, referred to as WaveTTS, that has 2 loss functions: 1) time-domain loss, denoted as the waveform loss, that measures the distortion between the natural and generated waveform; and 2) frequency-domain loss, that measures the Mel-scale acoustic feature loss between the natural and generated acoustic features. WaveTTS ensures both the quality of the acoustic features and the resulting speech waveform. To our best knowledge, this is the first implementation of Tacotron with joint time-frequency domain loss. Experimental results show that the proposed framework outperforms the baselines and achieves high-quality synthesized speech.